
Data governance describes how data is gathered and used within an organization. Effective data governance is crucial for ensuring data quality, security, and compliance, as well as enabling informed decision-making and driving business value. Data governance encompasses the processes, policies, and standards that govern how data is managed, secured, and utilized within an organization.
Data governance plays a vital role in establishing a consistent and unified approach to data management, ensuring data integrity, and promoting data-driven decision-making. By implementing robust data governance practices, organizations can unlock the true potential of their data assets, mitigate risks associated with data mismanagement, and foster a culture of data literacy and accountability.
As organizations increasingly deploy AI agents to automate decisions, generate analysis, and run business workflows, governance model choice has taken on a new dimension of consequence. The governance model an organization adopts determines not just how humans interact with data — it determines whether AI agents can retrieve consistent, certified, and trustworthy context regardless of which platform or system they are querying. Governance that works for a single data warehouse is different from governance that works for an enterprise running AI agents across multiple clouds, warehouses, and business units simultaneously.
So how should leaders approach governance? There are three main data governance models organizations can adopt: centralized, decentralized, and federated. Each model has its unique structure, benefits, and challenges, and the choice of model depends on the organization's specific needs, size, and data complexity.
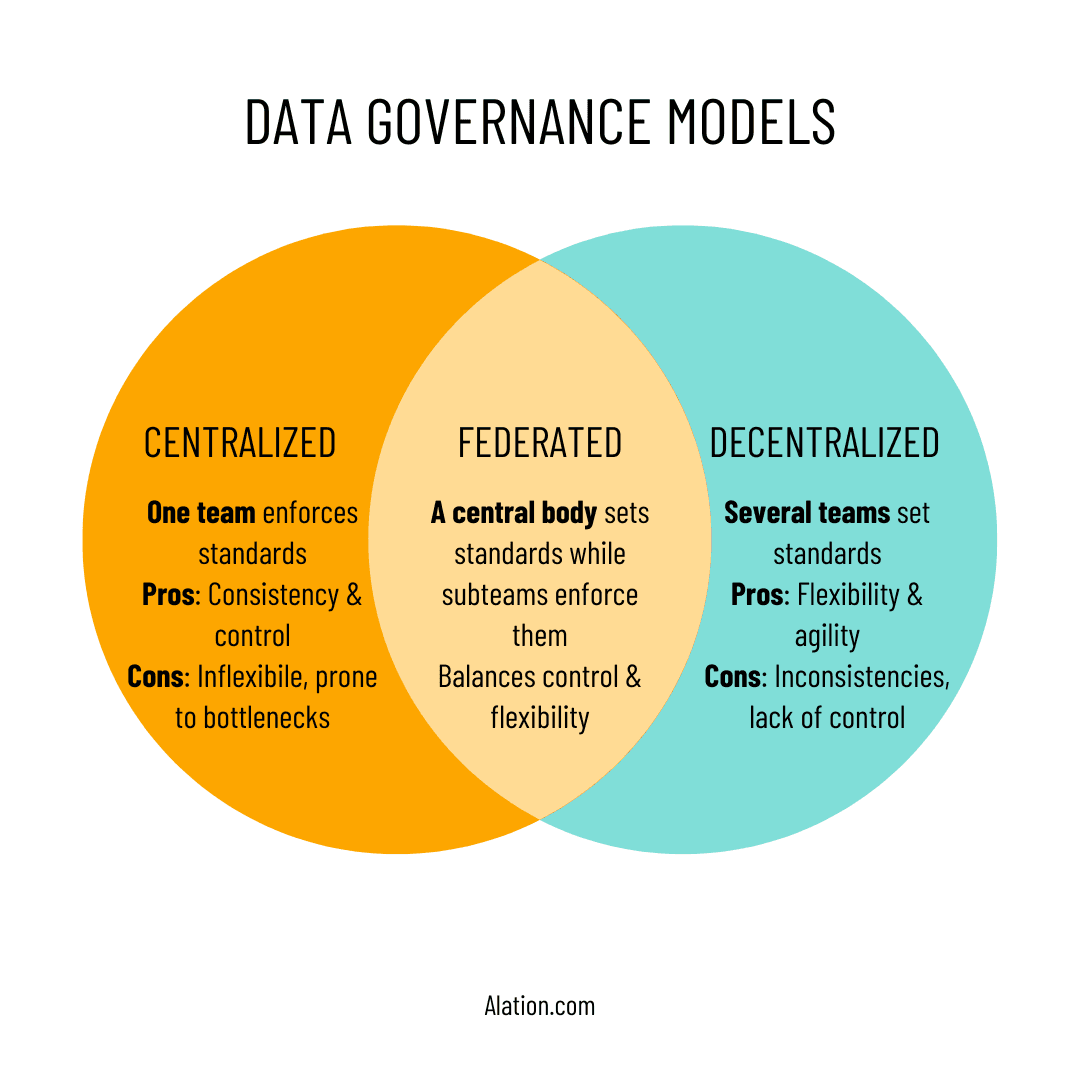
The centralized data governance model is characterized by a central authority or team (typically sitting in IT) that oversees and enforces data governance policies and standards across the entire organization. This model promotes consistency, control, and compliance but may face challenges such as bottlenecks and lack of flexibility – which is important as new regulations arise.
In contrast, the decentralized data governance model distributes data governance responsibilities across different business units or departments. This approach offers flexibility and faster decision-making but may lead to inconsistencies and a lack of control over data management practices.
The federated data governance model strikes a balance between centralized and decentralized approaches. It combines elements of both models, with a central governing body providing guidance and oversight, while individual business units or departments maintain a certain degree of autonomy in data management practices.
Key components of a data governance framework
Data governance is a broad term; it encompasses the processes, roles, policies, standards, and metrics that ensure the effective and efficient use of data assets within an organization. It establishes accountability for data management, ensuring data is treated as a valuable asset and leveraged to drive business value.
The key components of a data governance framework include:
Data Governance Roles and Responsibilities: Clearly defined roles and responsibilities for data stewards, data owners, data custodians, and other stakeholders involved in data management and governance.
Data Policies and Standards: Documented policies and standards that outline the rules and guidelines for data management, including data quality, data security, data privacy, data retention, and data usage.
Data Architecture and Metadata Management: A well-defined data architecture that outlines the structure and organization of data assets, along with robust metadata management practices to ensure data is properly documented and understood.
Data Quality Management: Processes and metrics to measure, monitor, and improve the quality of data assets, ensuring data is accurate, complete, consistent, and fit for its intended use.
Data Access and Security Controls: Policies and procedures to ensure appropriate access controls and security measures are in place to protect sensitive data and maintain data privacy and compliance.
Data Lifecycle Management: Processes for managing data throughout its lifecycle, from creation and acquisition to archiving and disposal, ensuring data is properly managed and maintained.
Data Governance Oversight and Monitoring: A governance body or committee responsible for overseeing and monitoring data governance initiatives, ensuring adherence to policies and standards, and driving continuous improvement.
By implementing a comprehensive data governance framework, organizations can establish a consistent and controlled approach to data management, enabling better decision-making, increased operational efficiency, and mitigated risks associated with data quality and compliance issues.

Centralized data governance model
The centralized data governance model is a top-down approach where a central authority or team is responsible for defining and enforcing data governance policies, standards, and processes across the entire organization. In this model, data governance decisions are made centrally, and all data-related activities are controlled and monitored by a dedicated governance team.
Definition and structure: centralized governance
In a centralized data governance model, a central data governance office or committee is established to oversee and manage all data-related activities. This central team may consist of representatives from various departments, such as IT, legal, compliance, and business units, although in the past this team was mainly comprised of IT workers. The team is responsible for developing and implementing data governance policies, standards, and procedures that apply to the entire organization.
Benefits of a centralized governance model
Consistency: With a centralized approach, data governance policies and standards are consistently applied across the organization, ensuring data integrity, quality, and uniformity.
Control: The central governance team has complete control over data management processes, enabling them to enforce policies, monitor compliance, and maintain data security and privacy.
Compliance: Centralized governance makes it easier to comply with regulatory requirements and industry standards, as policies and processes are defined and implemented from a single point of control.
Challenges of a centralized governance model
Bottlenecks: Centralized decision-making can lead to bottlenecks, slowing down data-related processes and hampering agility and responsiveness.
Lack of flexibility: A one-size-fits-all approach may not work for all departments or business units, as their data needs and requirements can vary significantly.
Resistance to change: Enforcing centralized policies and standards across the organization can face resistance from departments or individuals who are accustomed to their existing data management practices.
Platform dependency risk: In organizations running data across multiple clouds or warehouses, fully centralized governance can become tightly coupled to a single platform's capabilities, making it harder to govern assets that live outside that platform's boundary.
Use cases and examples: decentralized governance model
The centralized data governance model is often embraced by organizations with strict regulatory requirements, such as financial institutions and government agencies. It is also beneficial for organizations that prioritize data consistency, security, and control over flexibility. Examples of organizations that may adopt a centralized data governance model include:
Large banks and financial services firms
Healthcare providers and insurance companies
Government agencies and public sector organizations
Highly regulated industries (e.g., pharmaceuticals, energy)
In these organizations, a centralized approach ensures compliance with regulations, maintains data integrity, and protects sensitive information while providing a consistent view of data across the enterprise.
Decentralized data governance model
In a decentralized data governance model, decision-making authority and data management responsibilities are distributed across different business units, departments, or geographical locations within an organization. This model promotes a more localized and autonomous approach to data governance, where individual teams or regions have the freedom to define and implement data policies and procedures that align with their specific needs and requirements.
Definition and structure: decentralized governance
The decentralized data governance model is characterized by a distributed structure. Each business unit or department has its own data governance team or committee responsible for managing data assets within their respective domains. These teams operate independently, with minimal oversight or coordination from a central governing body. The decision-making process is typically bottom-up, with local teams having the autonomy to make data-related decisions that best suit their operational needs.
Benefits of a decentralized governance model
Flexibility: One of the primary advantages of a decentralized data governance model is its flexibility. Local teams can adapt data policies and procedures to meet their unique business requirements, enabling them to respond quickly to changes in the market, regulatory landscape, or organizational priorities.
Faster decision-making: With decision-making authority distributed across multiple teams, the decentralized model allows for faster decision-making processes. Local teams can make data-related decisions without having to navigate through a centralized bureaucracy, resulting in increased agility and responsiveness.
Localized expertise: By empowering local teams to manage their own data assets, the decentralized model leverages the domain-specific knowledge and expertise of those closest to the data. This localized expertise can lead to more informed and effective data governance decisions.
Challenges of a decentralized governance model
Inconsistency: One of the major challenges of a decentralized data governance model is the potential for inconsistencies across different business units or departments. Without a centralized governing body to enforce standards and guidelines, data definitions, policies, and procedures may vary, leading to data silos and interoperability issues.
Lack of control: In a decentralized model, there is a risk of losing overall control and visibility over data assets across the organization. Without a centralized governing body, it can be difficult to ensure compliance with enterprise-wide data governance policies and regulatory requirements.
Duplication of efforts: With multiple teams working independently on data governance initiatives, there is a higher likelihood of duplicating efforts, leading to inefficiencies and potential waste of resources.
AI accuracy risk: For organizations deploying AI agents, inconsistent data definitions across domains create a specific hazard. An agent querying data from two business units that define the same metric differently will produce inconsistent outputs — and neither result may match what a regulator or executive expects.

Use cases and examples: decentralized governance model
The decentralized data governance model is often suitable for organizations with a highly diversified business portfolio or those operating in multiple geographical regions with varying regulatory and cultural environments. Examples of industries where a decentralized model may be appropriate include:
Large conglomerates with diverse business units
Global organizations with operations in multiple countries or regions
Highly regulated industries operating on a global scale, with hyper-localized compliance requirements (e.g., finance, healthcare)
Organizations with a strong culture of autonomy and decentralized decision-making
It's important to note that while the decentralized model offers flexibility and localized control, it may require additional measures to ensure consistency, coordination, and overall alignment with enterprise-wide data governance objectives.
Federated data governance model
The federated data governance model strikes a balance between the centralized and decentralized approaches. It combines elements of both models to create a hybrid structure that offers a degree of control and standardization while still allowing for flexibility and autonomy across different business units or domains.
Definition and structure: federated governance
In a federated data governance model, a central governing body or council is established to oversee and coordinate data governance efforts across the organization. This central body is responsible for defining overarching data governance policies, standards, and guidelines. However, the implementation and enforcement of these policies are delegated to individual business units or domains within the organization, much like, as one governance lead at an energy company called “a data octopus.”
Each business unit or domain has its own data governance team or committee responsible for managing data governance within its respective area. These local teams work in collaboration with the central governing body, ensuring alignment with the overall data governance framework while also addressing their specific data needs and requirements.
Benefits of a federated governance model
Balance of control and flexibility: The federated model provides a balance between centralized control and decentralized flexibility. It allows for consistent data governance practices across the organization while still empowering individual business units to make decisions that align with their unique requirements.
Scalability: As organizations grow and become more complex, the federated model can scale more effectively than a purely centralized approach. It distributes the workload and decision-making across multiple teams, reducing the risk of bottlenecks and enabling faster adaptation to changing business needs.
Domain expertise: By involving local teams with domain-specific knowledge, the federated model leverages the expertise of subject matter experts within each business unit. This ensures that data governance practices are tailored to the specific needs and nuances of different domains.
Multi-platform compatibility: The federated model is particularly well-suited to organizations running data across multiple platforms — different cloud providers, warehouses, and BI tools operated by different teams. Rather than mandating a single platform as the governance center, federated governance allows each team to use the technology that best serves its needs while common policies and definitions flow across all of them.
Challenges of a federated governance model
Complexity: Coordinating and aligning multiple data governance teams across the organization can be complex and challenging. Clear communication channels, well-defined roles and responsibilities, and effective collaboration mechanisms are crucial for the successful implementation of a federated model.
Consistency and standardization: While the federated model aims to strike a balance, ensuring consistent data governance practices and standards across all business units can be difficult. Robust governance processes and regular communication between the central body and local teams are necessary to maintain alignment.
Federated governance and sovereign governance
A critical property of any federated governance implementation — and especially one designed to support AI agents operating across multiple platforms — is what practitioners call sovereign governance: a governance layer that exists independently of any single platform vendor.
As enterprises run data across Snowflake, Databricks, cloud storage, SaaS applications, and more, governance baked into any one platform's native tools stops at that platform's boundary. Snowflake Horizon governs within Snowflake. Databricks Unity Catalog governs within Databricks. Neither can govern the full estate without making itself the center — which is a form of lock-in the enterprise does not control.
Sovereign governance is different: it lives in a layer that no single platform owns, mastering business definitions, policies, and trust signals in one place and making them available across every platform that needs them. For federated organizations especially, this independence is what gives governance its durability. Business units can change platforms, adopt new tools, or migrate workloads without losing the institutional knowledge that governance represents.
The companion concept is fluid governance: metadata and business context that flows freely across platforms so that knowledge defined in one system enriches every other system that consumes it. Sovereignty without fluidity is a vault — knowledge that is protected but not useful. Fluidity without sovereignty is a liability — knowledge that circulates but belongs to the platform, not the enterprise. Effective federated governance for modern enterprises requires both.
Use cases and examples of a federated governance model
The federated data governance model is often adopted by large, diversified organizations with multiple business units or divisions operating in different domains or geographical regions. Examples include:
Large conglomerates with diverse business portfolios
Global organizations with operations in multiple countries or regions
Highly regulated industries, such as finance or healthcare, where data governance requirements may vary across different domains or jurisdictions
Technology-driven enterprises running data across multiple cloud providers, warehouses, and analytics tools that cannot be practically consolidated onto a single platform
By implementing a federated data governance model, these organizations can leverage the benefits of both centralized control and decentralized flexibility, enabling them to effectively manage and govern their data assets while addressing the unique needs of their different business units or domains.
Governance models and AI agents: why the model you choose affects agent accuracy
When organizations deploy AI agents to answer business questions, generate reports, or trigger automated workflows, they introduce a new consumer of data that is simultaneously more demanding and less forgiving than a human analyst. An analyst who encounters an ambiguous or inconsistent metric can ask a colleague. An agent will use whatever it finds — and produce a confident output based on it.
This makes governance model choice a direct determinant of AI agent accuracy. The patterns are consistent:
In purely decentralized environments, agents querying data across business units frequently encounter conflicting definitions of the same concept. Two domains may define "active customer" differently. Three warehouses may calculate "revenue" using different fiscal period assumptions. When an agent asks a question that spans those domains, it receives inconsistent inputs and has no way to resolve which definition is authoritative. The output is confident but unreliable.
In purely centralized environments, agents benefit from consistent definitions but may face a different problem: the centralized governance layer becomes a bottleneck. As AI use cases proliferate and different domains need tailored context for their specific data, a single central team cannot curate and maintain that context fast enough. Governance becomes a constraint on AI velocity rather than an enabler.
In well-implemented federated environments with cross-platform sovereign governance, agents can draw from consistent, certified business definitions regardless of which platform they are querying. Domain teams maintain ownership of their data and context; a central governance layer ensures that definitions are standardized and trust signals are uniform. An agent querying a Snowflake warehouse and an agent querying a Databricks lakehouse encounter the same definition of "revenue," the same quality signals, and the same policy constraints — because those definitions live in a governance layer that sits above both platforms, not inside either one.
This is why the most AI-ready organizations tend to converge on federated governance with cross-platform sovereign design. They have learned that standardizing the platform is neither practical nor desirable — different teams have legitimate reasons to use different tools. But standardizing the knowledge layer that governs what data means and whether it can be trusted is both achievable and essential. Data products become the governed, reusable packages through which that knowledge reaches agents and analysts alike, regardless of which system they happen to be querying.
The practical test: ask your governance team whether an AI agent querying your Snowflake environment would receive the same definition of your most critical business metrics as one querying your Databricks environment. If the answer is uncertain, your governance model is not yet ready to support trustworthy AI at scale.

The role of data catalogs in data governance
Data catalogs play a crucial role in supporting effective data governance across all three models: centralized, decentralized, and federated. A data catalog is a centralized repository that stores metadata about an organization's data assets, including their location, ownership, access permissions, and usage details.
Its inventory may encompass all of an organization's data assets, including databases, data lakes, data warehouses, and other data sources. A data catalog acts as a single source of truth for metadata, making it easier for data professionals to discover, understand, and access the data they need. Data catalogs are essential for data governance because they provide a bird’s eye view of an organization's data landscape, enabling better data management, compliance, and decision-making.
How data catalogs support each governance model
Centralized Data Governance: In a centralized model, a data catalog serves as the central repository for metadata, enabling consistent data definitions, policies, and standards across the organization. It facilitates data discovery, access control, and auditing, supporting the centralized governance team's efforts.
Decentralized Data Governance: In a decentralized model, a data catalog helps maintain consistency and transparency by providing a shared view of the organization's data assets. It enables collaboration and knowledge sharing among distributed teams, ensuring that data is managed and used consistently across different business units or regions.
Federated Data Governance: In a federated model, a data catalog acts as a central hub for metadata, while still allowing for localized data governance practices. It enables the sharing of data assets and metadata across different domains or organizations, promoting collaboration and interoperability.
Benefits of using data catalogs
Key benefits of implementing a data catalog include:
Improved Data Discovery: Data catalogs make it easier for users to find the data they need, reducing the time and effort required to locate relevant data assets.
Metadata Management: Data catalogs centralize and organize metadata, enabling better data understanding, lineage tracking, and impact analysis.
Data Access Control: Data catalogs facilitate the management of data access permissions, ensuring that only authorized users can access sensitive data.
Data Quality and Consistency: By providing a single source of truth for metadata, data catalogs help maintain data quality and consistency across the organization.
Compliance and Auditing: Data catalogs support compliance efforts by enabling the tracking and auditing of data usage, access, and lineage.
By leveraging data catalogs, organizations can enhance their data governance practices, improve data management, and ultimately drive better decision-making based on trusted and accessible data.
Choosing the right data governance model
Selecting the appropriate data governance model for your organization is crucial to ensure effective data management, compliance, and data-driven decision-making. The choice of model depends on several factors, including organizational size, data complexity, and regulatory requirements. Additionally, it's essential to weigh the pros and cons of each model to make an informed decision.
Factors to consider when choosing your data governance model
Organizational Size: The size of your organization plays a significant role in determining the most suitable data governance model. Larger organizations with multiple departments and geographic locations may benefit from a federated or decentralized approach, allowing for more flexibility and autonomy. Smaller organizations, on the other hand, may find a centralized model more manageable and cost-effective.
Data Complexity: The complexity of your organization's data landscape is another critical factor. If you deal with highly complex and diverse data sources, a federated or decentralized model may be more appropriate, as it allows for specialized data governance practices within different domains or business units. However, if your data is relatively straightforward and consistent, a centralized model can provide better control and consistency.
Regulatory Requirements: Depending on your industry and geographic location, you may be subject to various regulatory requirements related to data privacy, security, and compliance. A centralized data governance model can be advantageous in ensuring consistent adherence to these regulations across the organization. However, in some cases, a federated or decentralized approach may be necessary to address specific regulatory requirements within different business units or regions.
How different industries apply data governance models
Industry demands heavily influence whether organizations adopt centralized, decentralized, or federated governance. While every sector aims to balance trust, agility, and compliance, the execution varies based on regulatory pressure, operating models, and data maturity.
Financial services: Centralized for oversight, evolving toward hybrid
Banks, insurers, and superannuation funds operate under some of the strictest regulatory environments in the world. Because reporting accuracy, privacy, and auditability are non-negotiable, many financial organizations default to a centralized governance structure. This ensures uniform standards, consistent controls, and clear accountability.
Aware Super, one of Australia’s largest pension funds, recognized that full centralization slowed agility as data needs grew across the business. They adopted a hybrid governance model in which centralized teams set guardrails for data literacy, quality, and stewardship, while domain teams remain responsible for the data they own. This structure preserves regulatory rigor while allowing individual domains to move faster and create value.

Retail and consumer brands: Decentralized for speed and innovation
Retail and consumer-facing organizations must react quickly to shifting customer behavior and market trends. Decentralized or hub-and-spoke governance empowers merchandising, marketing, and digital teams to act on insights in real time.
The Very Group, a leading UK online retailer, inherited a fragmented data environment. By implementing a hub-and-spoke model through Alation, they established central policy coordination while giving departments autonomy. This strengthened data consistency without dampening innovation.
Energy and healthcare: Federated to support complex, regulated operations
Energy providers, utilities, hospitals, and life sciences organizations manage diverse datasets across clinical, operational, and research domains—each with unique compliance requirements. A federated model enables domain-level ownership while maintaining centralized policies for safety, privacy, and regulatory alignment.
Avista, a Pacific Northwest energy utility, exemplifies this approach with its “data octopus” framework. Each functional area manages its own responsibilities, such as lineage or stewardship, while a shared Alation catalog connects their work. This allows for both operational autonomy and coordinated outcomes.
Media organizations often take a similarly pragmatic path. For example, the BBC’s data governance team adopted a domain-owned, centrally governed operating framework to balance innovation with consistent oversight—a pattern mirrored by hospitals and research institutions managing highly sensitive data.
Across industries, the strongest governance strategies blend centralized standards with distributed ownership—enabling teams to operate quickly while preserving trust, quality, and compliance.
Kep steps to choose the right data governance model
To choose the most suitable data governance model for your organization, take the following steps:
Assess Your Organization's Needs: Evaluate your organization's size, data complexity, regulatory requirements, and specific business goals related to data management.
Identify Priorities: Determine your top priorities, such as data quality, security, compliance, or flexibility, and rank them in order of importance.
Analyze the Pros and Cons: Carefully weigh the pros and cons of each data governance model against your identified priorities and organizational needs.
Consider Hybrid Approaches: In some cases, a hybrid approach that combines elements of different models may be the most suitable solution for your organization.
Involve Stakeholders: Engage relevant stakeholders, including business unit leaders, data stewards, and IT professionals, to gather input and ensure buy-in for the chosen model.
Develop an Implementation Plan: Once you have selected the appropriate data governance model, develop a detailed implementation plan that outlines roles, responsibilities, processes, and timelines.
Monitor and Adjust: Regularly monitor the effectiveness of your data governance model and be prepared to make adjustments as your organization's needs evolve over time.
Remember, data governance is an ongoing process, and the chosen model should be reviewed and adapted as necessary to ensure it continues to meet your organization's changing requirements.
Conclusion
Implementing an effective data governance strategy is crucial for organizations to manage their data assets effectively, ensure data quality and security, and drive better decision-making. The choice of data governance model — centralized, decentralized, or federated — should align with the organization's goals, data complexity, regulatory requirements, and increasingly, the AI use cases it intends to support.
Key to successful data governance is striking the right balance between control and flexibility. A centralized model offers consistency and compliance but may lack agility and can become tightly coupled to a single platform's capabilities. A decentralized approach promotes flexibility but can lead to inconsistencies that become acute when AI agents need to reason across domain boundaries. The federated model balances control and flexibility, and when designed with cross-platform sovereign governance, it provides the durable foundation that modern AI-driven enterprises need.
Regardless of the chosen model, organizations should prioritize data catalogs as a critical component of their data governance framework. Data catalogs facilitate data discovery, metadata management, and collaboration — and in the era of AI agents, they serve as the knowledge layer that determines whether those agents produce outputs worth trusting. A catalog that governs context independently of any single platform, and makes that context available consistently across all platforms, is no longer a best practice. It is the infrastructure that makes governed AI possible.
For more on how to build a governance framework that supports both human decision-making and AI agent accuracy, explore Alation's Data Governance solution and the Agentic Data Intelligence Platform.
- Key components of a data governance framework
- Centralized data governance model
- Decentralized data governance model
- Federated data governance model
- Governance models and AI agents: why the model you choose affects agent accuracy
- The role of data catalogs in data governance
- Choosing the right data governance model
- How different industries apply data governance models
- Conclusion
Contents
Tagged with
Loading...