A Data Architect’s Guide to the Data Catalog

By Dave Wells
Published on May 20, 2020

A Data Architect’s Guide to the Data Catalog
Modernizing data architecture is one of the key challenges for those organizations pursuing the advantages of artificial intelligence (AI) and machine learning (ML). Data architecture for Business Intelligence (BI) was really quite simple when compared with the complex architecture that is needed today. BI data architecture focused primarily on how to acquire, organize, integrate, store, and access data. Acquisition and integration were based primarily on batch ETL, organization, and storage on relational concepts and technologies, and access on SQL queries. For organizations seeking more advanced analytics, this simpler model is no longer sufficient. Instead, they must transition to a modern data architecture and that requires a new approach to metadata management, best exemplified in an enterprise data catalog.
The Challenges of Modern Data Architecture
Modern data architecture for AI/ML is substantially more complex than for past generations of data management. The complexities begin with the data itself. AI/ML works best with massive data volumes. The data is not all structured and easily organized with relational concepts. Much of the data is not SQL-based and sometimes not SQL compatible. It is not all slow-moving data where batch processing is sufficient. It is not entirely internal data that is known and within the span of the enterprise’s control. It is not able to meet the needs of all use cases with a one-size-fits-all schema such as a data warehouse.
External data and big data sources can be filled with surprises. Sometimes the surprise is a shift in content or organization that affects how data is processed. More disruptive surprises occur when the data contains unanticipated Personally Identifying Information (PII), Payment Card Information (PCI), Protected Health Information (PHI), or other security and privacy sensitive data.
Now consider the multitude of users and use cases for today’s data resources—data scientists, data analysts, and business analysts—with many operating as self-service data consumers. They need to find data for analysis, understand the data, evaluate its suitability to their purpose, and access the data that they need—all without compromising the privacy of protected data.
The Requirements for Modern Data Architecture
Modern data architecture must scale to support massive data volumes and high-performance processing. It must be adaptable and resilient to change in data, technology, and consumer needs. It must support discovery of the data knowledge that is essential for consumers to find and understand the data that they need. It must support all data velocities from stream processing to batch ETL. It must support all data varieties from relational to the many variations of unstructured and semi-structured. It must provide data access for all data consumers while simultaneously protecting sensitive data.
And none of this is possible without metadata!
The Shape of Modern Data Architecture
Modern data architecture comprises several components that are interconnected and interdependent. (See figure 1.)
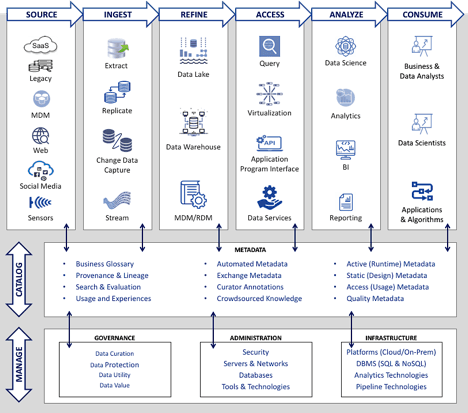
Figure 1. Modern Data Architecture
Through the data analytics lifecycle, the architecture includes the components to:
Source data—Connecting to any data source that is needed. Sources include data that is internal to the enterprise as well as externally sourced data. They include relationally structured, semi-structured, multi-structured, and unstructured data.
Ingest data—Bringing data into the analytics ecosystem. Ingestion includes both batch and real time methods ranging from batch ETL to data stream processing. Scalability and elasticity are important to adapt to variability in data volumes and speed of data.
Refine data—Organizing data into shareable data stores such as data lakes, data warehouses, and master data/reference data hubs. Data cleansing, integration, aggregation, and other types of data transformations are the responsibility of the data refinery.
Access data—Providing access to data both for people and for the applications and algorithms that use data is done in multiple ways including query, data virtualization, APIs, and data services.
Analyze data—Turning data into information and insights includes activities ranging from basic reporting to data science, artificial intelligence, and machine learning.
Consume data—Data consumption is the point where data and people are strongly connected. Getting from information and insights to decisions, actions, and impact is the purpose of data consumption.
In addition to support across all stages of the data analysis lifecycle, the architecture includes components for data management—governance, administration, and infrastructure—and for metadata management. Modern metadata management is ideally built on the capabilities of an enterprise data catalog. The catalog is truly a “Cross-Platform Metadata Management System” as described in a blog by Claudia Imhoff.
The Role of the Data Catalog
Metadata is the connective tissue that binds together all of the other architectural components—the means by which ingestion is aware of sources, refinement is bridged to ingestion, and so on. Every part of the architecture has a role in creating metadata and in consuming metadata.
Data acquisition—sourcing and ingestion—is the point at which data inventory is continuously updated with metadata that is a record of all data within the analytics ecosystem. A smart data catalog includes AI/ML capabilities to discover and extract metadata, minimizing the manual effort required for metadata capture and improving the level of metadata completeness. This is also the point at which data provenance metadata is collected and the data lineage chain begins.
Data refinement collects metadata about the flow of data through data pipelines and all of the transformations that are applied through the data flow. This includes both data pipelines that move data into data lakes and warehouses as well as pipelines that prepare data for analysis. Extending from data provenance, this metadata provides the lineage information that is an essential element of trusted data and a critical tool for tracing and troubleshooting when problems occur. A smart data catalog may also offer recommendations for data refinement—for example suggesting a way to blend two datasets or recommending a method to mask privacy-sensitive data.
Data access and data analysis depend extensively on the data catalog as the means for analysts to find the data that they need, to understand and evaluate data, and to know how to access the data. Metadata also connects data access with data governance to ensure that access controls are applied. Collecting metadata about frequency of access is useful to inform data valuation processes, and knowing who accesses frequently helps to find data subject matter experts.
Consuming data provides an opportunity to collect metadata about who uses which data, for what kinds of use cases, and with what business impact. Knowing about data consumers and their data dependencies is at the core of data management and data-driven culture. The value of consumption knowledge for data strategy, planning, and management should be apparent to everyone who works with data.
Managing data—governance, administration, and infrastructure management—depends on knowledge of the data, the processes that manipulate data, and the uses and users of data. Managing the knowledge as metadata in a data catalog ensures that data management processes are connected with and supportive of data analysis processes.
The modern data architecture diagram in figure 1 shows the data catalog at the center of the architecture and connected with every other component. That is the role of metadata—facilitating flow of data knowledge across all data management and data usage processes. It really is the glue that holds data architecture together.
Final Thoughts

Every data architect should know and appreciate the importance of metadata. Every data architect should also recognize the role of data catalogs as state-of-the-art metadata management. Smart data architects will quickly become data catalog advocates and champions.
- A Data Architect’s Guide to the Data Catalog
- The Challenges of Modern Data Architecture
- The Requirements for Modern Data Architecture
- The Shape of Modern Data Architecture
- The Role of the Data Catalog
- Final Thoughts
Contents
Tagged with
Loading...