Collaboration and Crowdsourcing with Data Cataloging

By Dave Wells
Published on February 13, 2020

A core element of business today is the desire to become a data-driven organization. Most organizations aspire to that goal and many of them struggle. The key to data-driven success and maturity is data culture, and strong data culture begins with participation. Getting people at all levels from chief data officer to self-service data consumer to actively participate in data management activities is a barrier to building a strong and healthy data culture. A data catalog can be the catalyst that helps to break through the barrier with collaboration and crowdsourcing.
Why Collaboration and Crowdsourcing? – A Macro View
Collaboration is central to data-driven culture, creating an environment where no data stakeholders work in isolation, and where working together and sharing knowledge and experience is the norm. A robust and full-featured data catalog encourages collaboration and crowdsourcing with capabilities such as ratings, reviews, annotations, and deprecations. This is the human side of data cataloging that breaks down organizational silos and fosters a culture of sharing—knowledge sharing, data sharing, process sharing (data preparation), and analysis sharing. (See figure 1.) The data catalog becomes the centerpiece connecting people, data, and use cases in a way that improves both speed and quality of analysis.
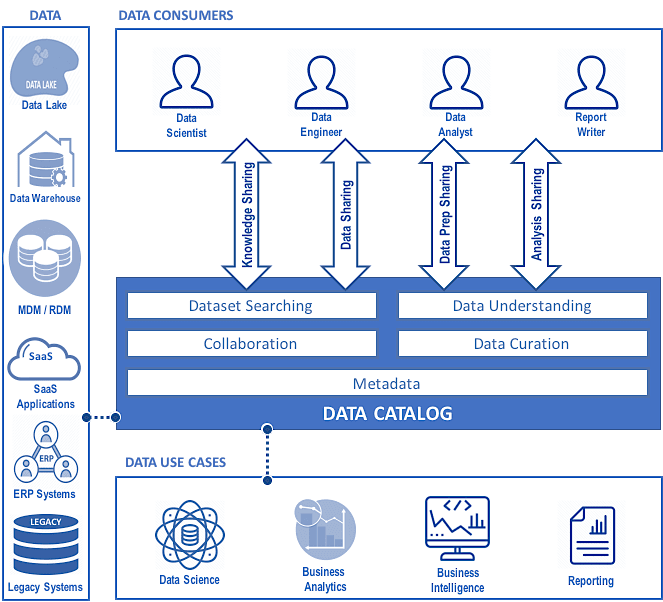
Actively sharing knowledge, data, and experiences elevates data literacy and competencies of everyone involved. Working together exposes every individual to new information and different perspectives, often generating new ideas and sometimes sparking innovation.
Why Collaboration and Crowdsourcing – An In-The-Trenches View
Analysis and Reporting: Finding the right data for a self-service reporting or analysis project is typically a difficult and time-consuming task filled with unanswered questions. Users of data have questions about quality, trustworthiness, latency, lineage, and more. Sometimes they want to find others who know or have worked with the data to get a human perspective. Through collaboration, the network of people willing to share their data knowledge rapidly expands. The effect is amplified with a data catalog that identifies data stewards, data coaches, data subject matter experts, and frequent users of datasets.
Data Curation: Data curation is the work of organizing and managing a collection of datasets to meet the needs and interests of those who work with data. In a previous blog, What Is Data Curation?, I described three levels of data curators—lead, domain, and collaborative. As shown in Figure 2, collaborative curators are the largest group, sharing and formalizing tribal knowledge and posting reviews and ratings to share their experiences when working with data.
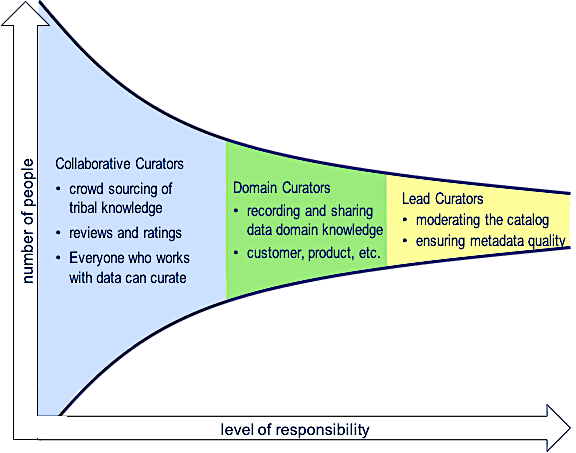
Crowdsourcing of tribal knowledge enriches catalog metadata and elevates the user experience for everyone who works with data. Crowdsourced knowledge from people who have worked with the data, consumer reviews, and usage tracking metadata help to evaluate and select the best-fit datasets for each unique analysis and reporting use case.
Data Governance: Adoption of self-service analytics has challenged conventional data governance practices. The top-down, command-and-control governance techniques of the past are at odds with the agility and autonomy interests of the self-service community. In the self-service world, collaborative data governance is an emerging and important practice. We must govern with the belief that most people want to do the right thing. The primary role of governance is to help them to know what the right thing is. Participation and collaboration are essential to fulfilling that role. (See figure 3.)
The data catalog is a core component of collaborative data governance. It provides a single point of reference for everyone who works with data. Everyone from chief data officers to self-service consumers see the same metadata, and all have opportunity to share their knowledge, experiences, and perspectives about data. Crowdsourced, participative data governance is a natural fit for self-service organizations.
The Collaboration Challenge
Collaboration and crowdsourcing are essential to get the most from your data catalog. The benefits are abundant including culture shift and improvements in data literacy, agility, speed of analysis, and quality of analysis. Collaboration, however, demands participation and many organizations find data catalog adoption—getting people to participate—to be among the biggest challenges. In my next blog, I’ll tackle this challenge with a discussion about Driving Data Catalog Adoption.
- Why Collaboration and Crowdsourcing? – A Macro View
- Why Collaboration and Crowdsourcing – An In-The-Trenches View
- The Collaboration Challenge
Contents
Tagged with
Loading...