Data Lineage Through the Decades: Where It's Going (And Where It's Been)

By Michael Meyer
Published on February 7, 2023

Twenty years ago, I saw into the future.
At the time, I was at a technology conference. There was a software product demo showcasing its ability to scan every layer of your application code, and I was intrigued to see how it worked. The product collected an impressive amount of metadata, from the user interface to the database structure. It then translated all that metadata into an image resembling a spider’s web.
Back then, visualizing impact analysis seemed futuristic with great promise. There was just one problem: the image was incredibly complex. Anybody interested in just one element had to scrutinize that gargantuan web to find it.
That was my earliest taste of data lineage. It was a telling introduction, as the complexity of interpreting the captured metadata posed an obstacle too vast for most people to overcome, lessening the product’s value. It wouldn’t be until 2013 that the topic of data lineage would surface again – this time while working on a data warehouse project.
Data warehouses obfuscate data’s origin
In 2013, I was a Business Intelligence Engineer at a financial services company. The business analysts were dealing with a problem that may sound familiar to folks in the data management space.
The business analysts spent over 75 percent of their time researching questions asked by business users. They sought documentation to help them locate the source of the data from the warehouse. They also needed a way to trace calculated columns and all the elements and logic that composed them. The developers spent time looking for a tool that could scan all the SQL code and Microsoft SSIS packages because that was the ETL tool being used.
Although the first product we tried didn’t deliver, a second product offered a glimmer of hope for scanning Microsoft SSIS and SSAS — and making sense of it all. After five years of searching for the right solution and endless hours of frustration, there was finally a light at the end of the tunnel. The team’s excitement only grew upon seeing demos of the lineage, which were promising. The product delivered a substantial level of lineage detail, all the way down to the columns and code that interacted with the columns.
We finally had a useful tool. Or so I thought. During the next six months, people simply used it less. Even the data lineage diagrams, the feature we saw as the most valuable to most people, were being ignored. I started to ask around to see why that was the case. Our analysts told me that the discovery features were OK, but they were perplexed by the level of detail in the lineage diagrams. On the opposite end of the spectrum were the engineers, who went directly to the source code rather than looking at the tool’s SSIS details.
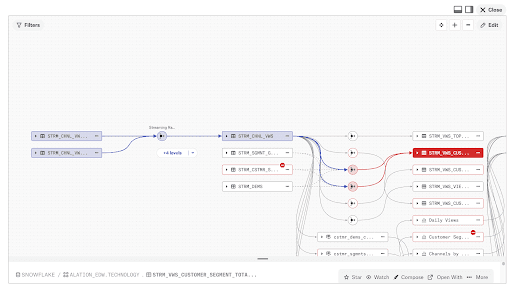
What was missing from the adoption equation? I now realize that it was integration with a data catalog like Alation. The lineage metadata didn’t gain traction because it wasn’t actively integrated with other business and technical metadata. This information is only valuable when it’s used to enrich different contexts. By contrast, if an item is marked as deprecated in Alation, the lineage reflects the downstream impacts immediately. This is valuable for not only analysts but engineers, too!
In today’s world, all data users need details on data’s lineage to use data effectively. This is why it is critical to have active metadata that signals when crucial data assets have issues impacting business users. Lineage can show data movement in your pipelines, but when you add elements, such as data quality, with that movement, you actively ensure the delivered data is trustworthy!
What’s the right lineage level? It depends!
Table and column lineage form an essential data foundation. Beyond that, the question of how much data lineage is required comes down to the value it adds to a business and the person consuming the information. Analysts want that high-level overview, while engineers desire a more granular view. Both groups will benefit from having the information rationalized and integrated into one place (like Alation). This enables organizations to maintain trusted data that proactively drives essential business decisions. This is the true measurement of data lineage.
It’s been more than 20 years since I first saw lineage in its earliest form. It’s exciting to see how that spaghetti mess web of visualized lineage has evolved into something much more user-friendly and helpful. The challenge today lies in giving the right people the right lineage information at the right time when they need it most. A data catalog is an ideal platform for surfacing those details with a broad audience.
Curious to learn more? This blog on the future of data lineage outlines the challenges – and opportunities – of data lineage in the coming years.
- Data warehouses obfuscate data’s origin
- What’s the right lineage level? It depends!
Contents
Tagged with
Loading...