Data Mesh: The Sky Is Not Falling

By Jay Piscioneri
Published on April 27, 2023

Article reposted with permission from Eckerson
ABSTRACT: Data mesh is giving many of us from the data warehouse generation a serious case of agita. But, my fellow old-school data tamers, it’s going to be ok.
Sponsored by Alation
Data mesh is a hot topic in the data world, generating conversations about the benefits and drawbacks of its decentralized approach. One persistent area of debate is whether domain teams can and should build products that not only meet their needs, but also address the needs of other domains. It’s a subject that’s giving many of us from the data warehouse generation a serious case of agita.
Concerns about an unmanageable explosion of data silos, inconsistent data quality, and multiple versions of universal data that should be common to all domains, are justified. But the historical forces that drive technological innovation suggest that we are on a well-trodden path of decentralization and decoupling, i.e., technology naturally evolves into smaller, more autonomous units. In this article, I’ll make a case to those who feel a bit like Chicken Little that maybe the sky is not falling. Perhaps we’re climbing upward instead.
The Challenge of Meeting Diverse Needs in a Data Mesh
Data mesh transfers ownership of data from centralized data teams to distributed domain-oriented teams. A domain team understands the key business processes; the data the domain produces; and the analytics that its stakeholders need to solve business problems and capitalize on opportunities.
But what happens when one domain needs data from another domain? It’s not an easy task for domain teams to build products that serve others when they have to consider multiple perspectives and requirements. This is the challenge that central data teams face that slows them down.
Shifting responsibility for building data products to decentralized domain teams makes sense in that they understand their stakeholders’ business processes, applications, and data. This shift can enable them to deliver better solutions faster. However, that advantage dissolves once they venture outside of their domain. They can’t take the time to understand the requirements of unfamiliar domains without becoming a bottleneck like the central data team they’re supposed to improve upon.
What about data subject areas that span multiple domains, such as customer or product information, a.k.a. master data? If each domain team has its own version of master data, then we’ll be right back where we started before data warehousing. Back then everyone had a spreadsheet with their own version of data and there were a thousand different answers to the same question, resulting in the dreaded spreadmart.
This is what gives my generation heartburn. We feel like all the progress we made toward rationalizing enterprise data is slipping away. In fact, it is—for now. But I’m here to tell you, it’s okay. Let’s take a deep breath and look at the big picture.
The Irresistible Force of Decentralization and Decoupling
Data mesh is driven by the same historic forces that have shaped computer technology since its beginning. Over time, software and hardware components tend to get narrower in scope and more independent. They become more than just parts of a centralized system and are less tightly coupled to each other to function. We have seen many waves of this evolutionary dynamic.

Centralized computer operations circa 1964
Over time, software and hardware components tend to get narrower in scope, and more independent
For example, I started my technology career at the dawn of the PC era, a very disruptive wave that decentralized computing power and decoupled users from dependence on a corps of cloistered computer operators. The internet followed, decentralizing information access and decoupling information creators from proprietary distribution channels. More recently, microservice architecture brought about the decentralization and decoupling of software functions. The graphic below illustrates waves of technological decentralization and decoupling.
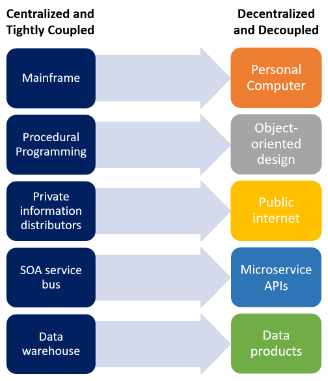
Technologies that evolved toward decentralization and decoupling
Each of these waves initially caused chaos until a balance was struck between the innovation they enabled and some degree of governance and standards that protected long-term outcomes. Each time, we had to learn how to achieve that balance through practical application resulting in pendulum swings between too much control stifling innovation and back to not enough control leading to debilitating inefficiencies and risks. This historical pattern, which has played out repeatedly, convinces me that in the long run, we will work through the challenges presented by data mesh.
History is Great, But What About the Present?
To come back to the legitimate questions and concerns that the agita-sufferers raise, here are a couple of practical recommendations:
Think globally, act locally. Domain teams should primarily focus on building data products for their own domains for which their expertise is uniquely valuable. However, they can serve a broader constituency by making guarantees that their data product will meet certain expectations regarding its schema, its update cadence, its purpose, and its quality. This forms a contract between data producers and consumers. It lets consumers decide whether a data product is suitable for their needs and whether they can rely on it to use as a building block in their own data product development.
Manage common data subjects centrally. Common data subjects that span multiple domains, such as customer or product information, should be managed by a central data team. This is an area where central control is still appropriate to ensure consistency, accuracy, and integrity of enterprise-wide data. We also must centralize our metadata to facilitate search, discovery, collaboration, and governance in a decentralized world. As we improve our skills at implementing data mesh, how we handle common data subjects will evolve toward more decentralized and decoupled solutions. But that’s not where we are now.
Conclusion
Just because there are historical forces at work, we should not be complacent—quite the opposite. We’re experiencing a new iteration of chaos as data mesh, and its most popular principle, the data product, proliferates. The immediate gratification of delivering lots of data products is too hard to resist right now to slow it down. That means we have to work harder at finding the balance between the benefits of decentralized data ownership and the protections of centralized standards.
If you buy the argument data mesh is too much of a risk and will collapse before it delivers on its promise, you’ll be left behind
But I disagree with those that say data mesh is too much of a risk and will collapse before it delivers on its promise. If you buy that argument, you’ll be left behind because the historical forces driving data mesh forward make its objectives inevitable. Each company has to find its own way of decentralizing and decoupling data. They also have to find their own version of balancing its benefits with the protections of data governance.
To those who feel these changes ignore hard lessons about governance that took a generation to learn, I say keep making the point. In this way, you help craft the balance between innovation that serves immediate needs and governance that protects long-term results. It can be painful. But with progress, there is always some pain. As R. Crumb’s famous underground comics character, Mr. Natural says…

- The Challenge of Meeting Diverse Needs in a Data Mesh
- The Irresistible Force of Decentralization and Decoupling
- Over time, software and hardware components tend to get narrower in scope, and more independent
- History is Great, But What About the Present?
- Conclusion
Contents
Tagged with
Loading...