Driving Business Value and ROI from a Hybrid Cloud Data Lake

By Jason Ma
Published on February 20, 2020

For many enterprises, a hybrid cloud data lake is no longer a trend, but becoming reality. With a cloud deployment, enterprises can leverage a “pay as you go” model; reducing the burden of incurring capital costs. Compute and storage resources are separated, allowing those resources to be rapidly provisioned and scaled up or down independently. Not only can resources be quickly provisioned and optimized for different workloads and processing needs, but it can be done cost effectively.
With an on-premise deployment, enterprises have full control over data security, data access, and data governance. Performance is more reliable, and there is wide array of mature software products at the enterprises’ disposal. While enterprises are moving to the cloud for its flexibility and scalability, there is still the need for the robust security and control inherent in an on-premise deployment.
Due to these needs, hybrid cloud data lakes emerged as a logical middle ground between the two consumption models. In a hybrid model, there is more flexibility as to where workloads can run and how much and how fast to scale. Data that needs to be tightly controlled (e.g. customer data, PII) can be stored in an on-premise system, while data that doesn’t need to be as tightly controlled can be stored in the cloud. This enables flexibility and cost-effectiveness, while still maintaining proper security controls.
For example, a risk insurance company that has sensitive customer information and transactional data, can store that information in an on-premise system. The cloud could then be leveraged for burst out scenarios, such as processing and adjusting risk policies around a real-time event (e.g. earthquake, flood, or fire), where the data collected does not need to be as tightly controlled. Since an earthquake event can generate gigabytes of data, a company can spin up extra computing nodes, process the data, and spin down the nodes once the processing is complete.
AWS Propelling Hybrid Cloud Environments
The reality is that many enterprises will continue to maintain an on-premise system for the foreseeable future, though enterprises are increasingly shifting a larger percentage of their deployments to the cloud. Over the past few years, Amazon Web Services (AWS) has captured a significant portion of this shift as more and more customers migrate to its services. Here at Alation, we’ve been working with AWS since the inception of the company. Customers, such as eBay and Invoice2Go, have harnessed the power of Alation’s Data Catalog to find and explore data in AWS Redshift. Recently, Alation announced a new addition to its AWS offering with the ability to automatically catalog(S3). Amazon S3 offers many benefits for enterprises looking to decrease costs, reduce maintenance, and increase durability and scalability for their data lakes.
The Problem with Hybrid Cloud Environments
As more enterprises move to AWS and a hybrid cloud environment, the challenge becomes how to derive context and make content discoverable across multiple disparate environments. While there are good tools that provide a technical foundation (AWS Glue, Cloudera Navigator, Apache Atlas), understanding the business context is what is most critical to promote business value and ultimately provide a return on investment (ROI) in the data lake. Without business context, business users are less likely to use the data lake and insights will be hard to come by. That’s why so many data lakes fail – not because of technical limitations but because they can’t be used by the people who are doing the analysis.
The Alation Data Catalog solves this problem by providing a single source of reference across your hybrid cloud environment, resulting in not only transparency and discoverability of data content, but most importantly business context. Alation’s native integration with file systems (S3 and HDFS), data processing engines such as Spark, Presto and Impala, BI tools (Tableau, Microstrategy, Salesforce Einstein Analytics), and relational data sources (Hive, Oracle, SQL Server, Teradata, etc) addresses the complexity of working with data lakes and provides a holistic view into the business context of your environment – whether it’s in the cloud or on-premises.
How to Catalog AWS S3 with Alation
With Alation’s new native integration with filesystems, cataloging AWS S3 is simple. The Alation Data Catalog will automatically crawl and catalog metadata in your S3 bucket(s).
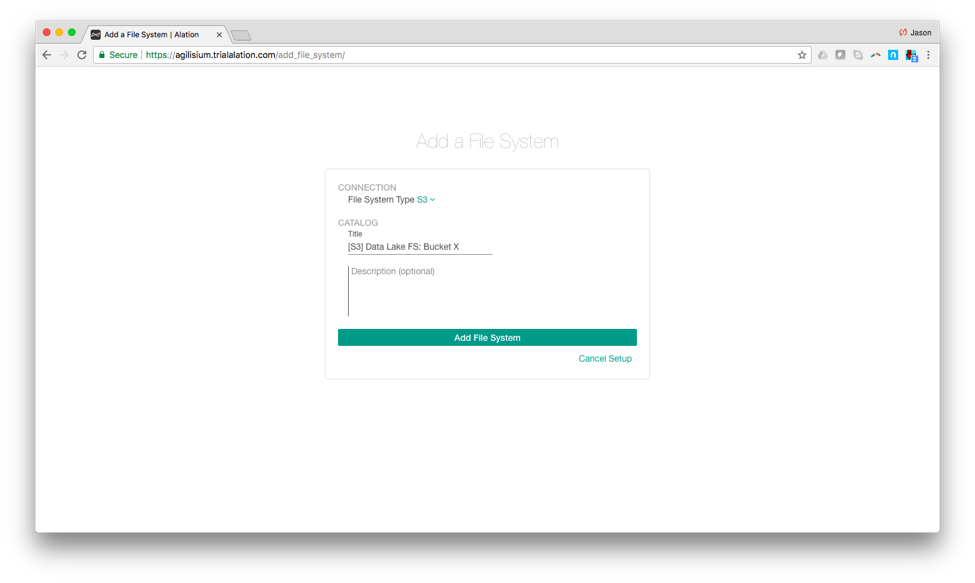
In The Alation Data Catalog adding S3 is simple. Just select the file system type as ‘S3’, add a title, and click ‘Add File System’.
Enter the following S3 credentials into Alation: ‘AWS Access Key ID’ and ‘AWS Access Key Secret’.
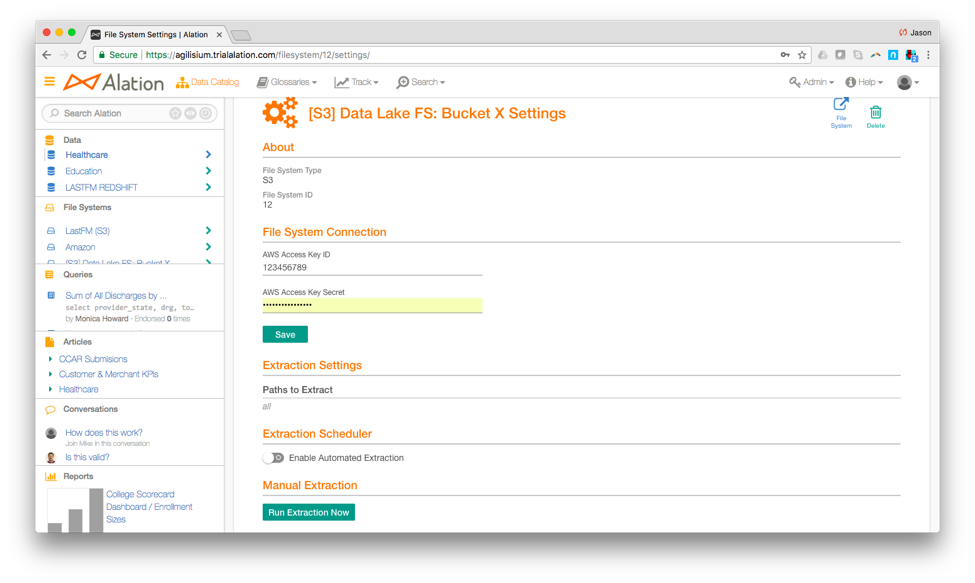
Here there is only one S3 bucket, but if there were additional buckets, The Alation Data Catalog would automatically catalog and extract metadata from all buckets. Once the proper credentials are entered, click ‘Run Extraction Now’ and The Alation Data Catalog will begin the automated metadata extraction process.
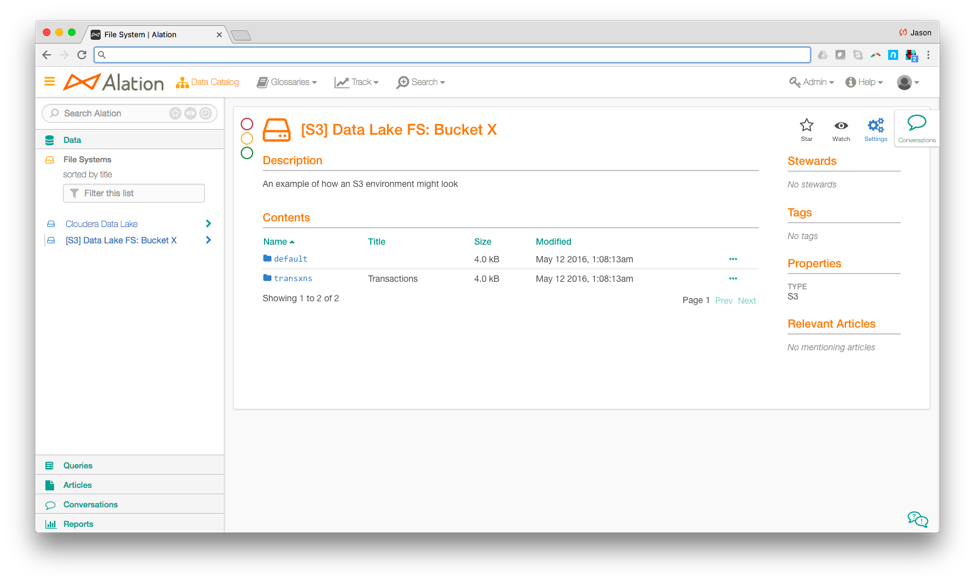
Once the metadata extraction process is complete, the cataloged S3 bucket is fully discoverable in The Alation Data Catalog.
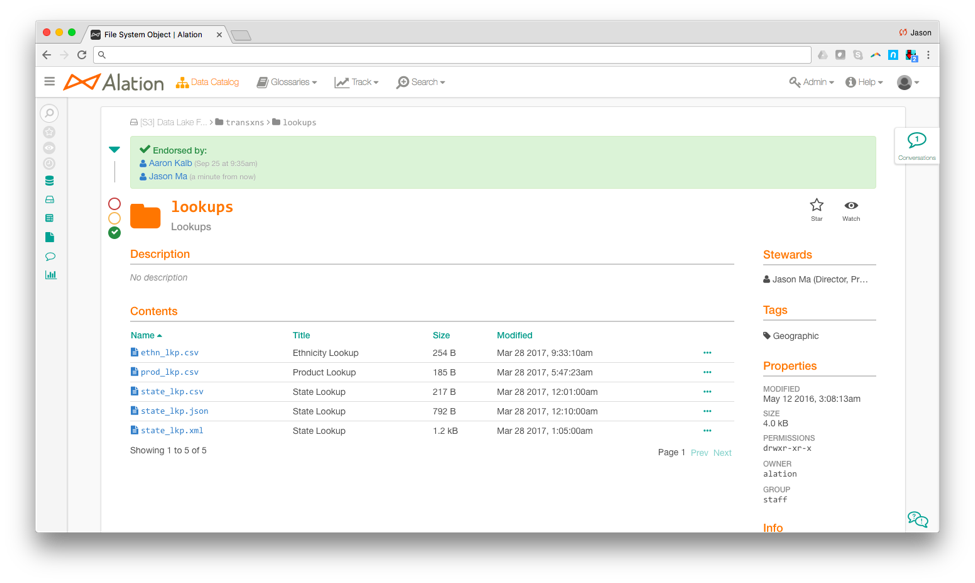
The Alation Data Catalog will provide information such as a list of directories and files, file size, modification date, permissions, tags, relevant articles, and stewards. Users can also collaborate through social curation. Here, pro-active recommendations, such as endorsements, are available in real-time and highlight that the S3 directory has been endorsed by people within the organization.
Alation customers, such as Chegg, use Alation’s Data Catalog as the single source of reference to search across data stored in the cloud (S3) and on-premises (HDFS/Hive). These customers are able to harness business context to drive usage, empowering insights and ultimately leading to increased ROI in the data lake.
In Conclusion
As enterprises shift more spend to AWS, and other cloud vendors, a hybrid cloud data lake will continue to gain popularity. The key for a successful hybrid cloud deployment is to enable users with the proper business context to find insights and innovate on the data lake. With more enterprise deployments both in the cloud and on-premises, The Alation Data Catalog will play an increasingly vital role as the single source of reference to drive ROI across these different consumption models.
- AWS Propelling Hybrid Cloud Environments
- The Problem with Hybrid Cloud Environments
- How to Catalog AWS S3 with Alation
- In Conclusion
Contents
Tagged with
Loading...