Why Easier Governance Is Superior Governance

By Arshkrit Chowdhury
Published on February 1, 2022

By Arshkrit Chowdhury, Guest Author
A new research report by Ventana Research, Embracing Modern Data Governance, shows that modern data governance programs can drive a significantly higher ROI in a much shorter time span. Historically, data governance has been a manual and restrictive process, making it almost impossible for these programs to succeed.
David Menninger, Research Director at Ventana Research, argues that traditional, restrictive governance costs organizations time, money, and valuable insights.
Data is valuable for the insights concealed within. Today organizations view data as the “new oil”, an asset that, if used wisely, can support innovation while providing a meaningful competitive advantage and a better customer experience.
And with data collection and replication growing so quickly, governance is more important than ever. It’s evident that a modern approach to governance is needed. Menninger states that modern data governance programs can provide a more significant ROI at a much faster pace.
Most traditional governance methods involve cumbersome manual processes; spreadsheets and human-led documentation of policies in numerous patchwork systems translate to a lot more searching, manual updating, and the risk of exposing one’s data.
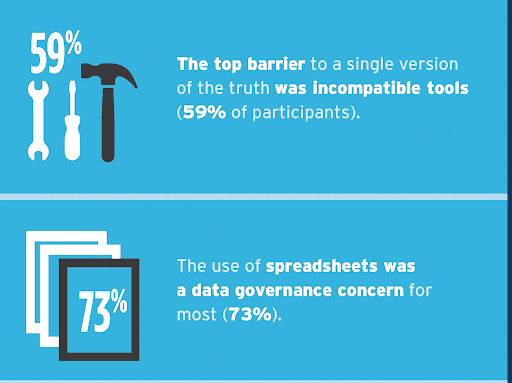
And those who practice these “old school” governance methods have little confidence in their efficacy: 73% of Ventana research participants stated that spreadsheets were a data governance concern for their organization, while 59% viewed incompatible tools as the top barrier to a single source of truth.
The Role of Automation in Data Governance
Automation is increasingly heralded as the panacea to these data woes. And it’s growing in popularity. Between 2016 and 2019, robot-vacuum cleaner sales jumped by 13% year over year. Everyone wants a cleaner home… but how many of us like cleaning our homes? The hope that we may automate tedious tasks, like vacuuming, has long animated the spirit of technological progress. But what could automation do for data governance?
Plenty. Automation makes data governance easier and more consistent. For instance, if the same or similar data is captured or represented in multiple ways, analysts may struggle to identify which data to trust. Data governance introduces tagging and labeling to address this challenge. Tags and labels clarify where a certain type of data, (say, address, for example) is grouped under the same name.

Those who work closely with data seek to automate tedious, time-consuming processes. About one-half of Ventana Research participants want to schedule data processes to run automatically & two-thirds seek to eliminate manual processes when working with data.

Sheer volume of data makes automation with Artificial Intelligence & Machine Learning (AI & ML) an imperative. Menninger outlines how modern data governance practices may deploy a basic repository of data; this can help with some level of automation. But to improve and automate complex processes, AI & ML are key.
AI & ML-powered data catalogs make centralizing policies and applying them at the point of usage just as easy as turning on a robot vacuum. Most organizations depend on institutional knowledge to populate data catalogs; without any form of automation, these leaders are forced to interview numerous people to find out who is the SME for a particular data set and have that person populate the catalog.
And simply finding and cleaning data gobbles the vast majority of the time of many analysts in large organizations. Ventana found that the most time-consuming part of an organization’s analytic efforts is accessing and preparing data; this is the case for more than one-half (55%) of respondents. Data catalogs can significantly reduce this burden by making it easier for analysts to find and access relevant information.
Data lakes are repositories where much of this data winds up. Data lakes are implemented with a vision of eliminating data silos. Nevertheless, when people dump all this data in a single place, a systematic, shared approach to analyzing it is key. Otherwise, we risk opening Pandora’s box.
Are we maximizing the benefits from data lakes?
Ventana research shows that 68% of those using data catalogs are satisfied with their data lakes, and only 39% of those who do not use data catalogs are satisfied with their data lake. So why is data catalog positively correlated with data lakes in this way?
Because a data catalog cuts down the time it takes to find and access data dramatically. Data catalog users can find data within the data lake with a quick google-like search. Catalogs can also containerize data, depending on which department or domain they belong to.

In this way, we can conclude that the best way to manage data governance is to maintain an automated repository of governance policies. We are also seeing growing popularity in following this approach. Eventually, keeping one’s data landscape clean and tidy will be eased with AI & ML, and as straightforward as flipping on the robot-vacuum.
Ventana Research, a respected advisory firm established in 2002, conducts unique and comprehensive research in the field of Analytics, Data, Digital technology, and Digital business. The report author, David Menninger, SVP & Research Director at Ventana, boasts more than 25 years of experience in combining data and analytics to support decision-making.
- The Role of Automation in Data Governance
- Are we maximizing the benefits from data lakes?
Contents
Tagged with
Loading...