Generative AI Needs Vigilant Data Cataloging and Governance

By Kevin Petrie (VP of Research at Eckerson Group)
Published on November 14, 2023

ABSTRACT: Data catalogs evaluate and control the accuracy, explainability, privacy, IP friendliness, and fairness of GenAI inputs.
Sponsored by Alation | Originally published by Eckerson
Our industry’s breathless hype about generative AI tends to overlook the stubborn challenge of data governance. In reality, many GenAI initiatives will fail unless companies properly govern the text files that feed the language models they implement.
Data catalogs offer help. Data teams can use the latest generation of these tools to evaluate and control GenAI inputs on five dimensions: accuracy, explainability, privacy, IP friendliness, and fairness. This blog explores how data catalogs support these tasks, mitigate the risks of GenAI, and increase the odds of success.
What is GenAI?
GenAI refers to a type of artificial intelligence that generates digital content such as text, images, or audio after being trained on a corpus of existing content. The most broadly applicable form of GenAI centers on a language model (LM), which is a type of neural network whose interconnected nodes collaborate to interpret, summarize, and generate text. OpenAI’s release of ChatGPT 3.5 in November 2022 triggered an arms race among LM innovators. Google released Bard, Microsoft integrated OpenAI code into its products, and GenAI specialists such as Hugging Face and Anthropic gained new prominence with their LMs.
Now things get tricky
Companies are embedding LMs into their applications and workflows to boost productivity and gain competitive advantage. They seek to address use cases such as customer service document processing based on their own domain-specific data, especially natural-language text. But text files introduce the risks of data quality, fairness, and privacy. They can cause LMs to hallucinate, propagate bias, or expose sensitive information unless they are properly cataloged and governed.
Data teams, more accustomed to database tables, must get a handle on governing all these PDFs, Google Docs, and other text files to ensure GenAI does more good than harm. And the stakes run high: 46% of data practitioners told Eckerson Group in a recent survey that their company does not have sufficient data quality and governance controls to support its AI/ML initiatives.
Data teams need to govern the natural-language text that feeds GenAI initiatives
Enter the data catalog
The data catalog has long assisted governance by enabling data analysts, scientists, engineers, and stewards to evaluate and control datasets in their environment. It centralizes a wide range of metadata—file names, database schemas, category labels, and more—so data teams can vet data inputs for all types of analytics projects.
Modern catalogs go a step further to evaluate risk and control usage of text files for GenAI initiatives.
Modern catalogs go a step further to evaluate risk and control usage of text files for GenAI initiatives. This helps data teams fine-tune and prompt their LMs with inputs that are accurate, explainable, private, IP-friendly, and fair. (See figure 1.)
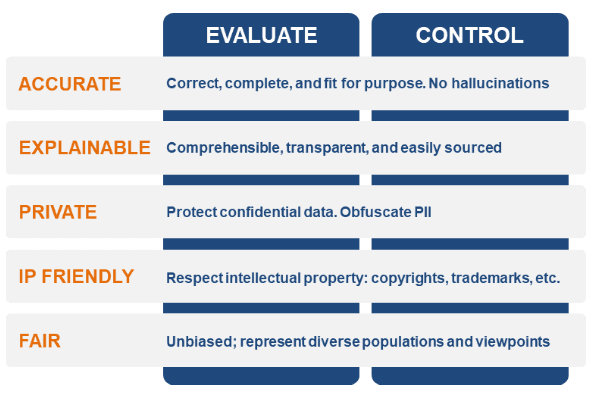
Figure 1. Data Catalog Controls for Gen AI
Catalogs help data teams govern LM inputs to be accurate, explainable, private, IP-friendly, and fair.
Accuracy. LMs need to minimize hallucinations—i.e., the fabrication of facts to compensate for gaps in training data—by using inputs that are correct, complete, and fit for purpose. Catalogs centralize metadata to help data teams evaluate data objects according to these requirements. For example, data engineers might append accuracy scores to text files, rate their alignment with master data, or classify them by topic or sentiment. Such metadata helps the data scientist select the right files for fine-tuning or prompt enrichment via retrieval-augmented generation (also read this blog to learn more about RAG). This helps control the accuracy of LM inputs and outputs, reducing the likelihood that LMs will make things up.
Explainability. LMs should provide transparent visibility into the sources of their answers. Catalogs help by enabling data scientists and ML engineers to evaluate the lineage of their source files. For example, the data scientist with a financial-services company might use a catalog to trace the lineage of sources for an LM that processes mortgage applications. They can explain this lineage to customers, auditors, or regulators, which helps them trust the LM’s outputs.
Privacy. Companies must maintain privacy standards and policies when using LMs. Data catalogs assist by identifying, evaluating, and tagging personally identifiable information (PII). Armed with this intelligence, data scientists and ML or NLP engineers can work with data stewards to obfuscate PII before using those files. They also can collaborate with data stewards or security administrators to implement role-based access controls based on compliance risk.
IP friendliness. Companies must protect intellectual property such as copyrights and trademarks to avoid liability risks. By evaluating data ownership and usage restrictions for text files, catalogs can help data engineers and data stewards ensure that data science teams do not overstep any legal boundaries as they fine-tune and implement LMs.
Fairness. GenAI initiatives cannot propagate bias by inadvertently delivering responses that unfairly represent certain populations or viewpoints. To prevent bias, data teams can evaluate, classify, and rank files according to their representation of different groups. By centralizing this metadata in a catalog, they can decide on a holistic basis whether they have the right balanced inputs for their LMs. This helps companies control the level of fairness.
Conclusion
Generative AI creates exciting opportunities for companies to make their workers more productive, their processes more efficient, and their offerings more competitive. But it also exacerbates long-standing risks such as data quality, privacy, and fairness. Data catalogs offer a critical platform for governing these risks and enabling companies to realize the promise of GenAI. And in a symbiotic fashion, GenAI can help catalogs achieve this goal. Check out Alation’s recent announcement to learn how its Allie AI co-pilot helps companies automatically document and curate datasets at scale.
- What is GenAI?
- Now things get tricky
- Enter the data catalog
- Conclusion
Contents
Tagged with
Loading...