From Raw Data to Data Products: Transforming JIRA Data for Enterprise Value

By Jake Magner
Published on May 19, 2025

In today's data-driven enterprise landscape, organizations often struggle to extract meaningful insights from operational tools like JIRA. While these platforms contain treasure troves of valuable data, transforming raw information into actionable intelligence requires thoughtful productization.
This post explores how to evolve raw JIRA data into enterprise-grade data products that can be easily consumed, trusted, and leveraged across your organization.
The challenge: Raw JIRA data is valuable but unoptimized
Most organizations use JIRA as an operational tool for planning, tracking, and executing work. However, when this data lands in your data warehouse, it arrives in a format optimized for application performance rather than analytics:

This raw data presents several challenges for analytics users:
Cryptic field names (like customfield_13633)
Complex JSON structures requiring parsing
Numeric identifiers needing translation into readable text
Hidden business context embedded within the data
Most critically, using this data effectively requires deep domain knowledge about how your organization specifically uses JIRA—information typically known only by JIRA administrators or power users.
The data product approach
A data product transforms raw data into a structured, documented asset explicitly designed for consumption, reliability, and reuse. For JIRA data, this means:
Structured representation that aligns with business concepts
Embedded business logic that clarifies meaning
Comprehensive documentation providing context
Reliability guarantees through data contracts
Step 0: Validating use cases and grasping use needs
Before diving into technical transformations, successful data products begin with a thorough understanding of user needs and potential value. This crucial first step involves:
Identify potential use cases: Meet with stakeholders across departments to understand how JIRA data could solve their specific problems. What questions are they trying to answer? What metrics do they need? For engineering leadership, this might be delivery predictability; for product managers, feature completion rates; for support teams, case resolution patterns.
Create and validate mock-ups: Develop visual prototypes showing how the transformed data might appear in reports or dashboards. These tangible examples help potential users envision the value and provide feedback before significant development begins. Ask questions like: "Would this view help you make better decisions?" or "What's missing from this report?"
Engage with JIRA power users: Spend time with the teams that actually use JIRA to understand their workflows, terminology, and how they structure their work. How do they use custom fields? What do different status values truly mean in their context? These conversations reveal critical business logic that must be encoded in your data product.
Only after validating that there's genuine demand and understanding the specific requirements should you proceed to the technical transformation work. As one data product manager told us: "I spent three weeks talking to users before writing a single line of SQL. Those conversations saved us months of building the wrong thing."
Step 1: Creating analytics-ready tables
The first step in transforming JIRA data into a product is restructuring it into a format aligned with how users think about the data. To return to our earlier example:
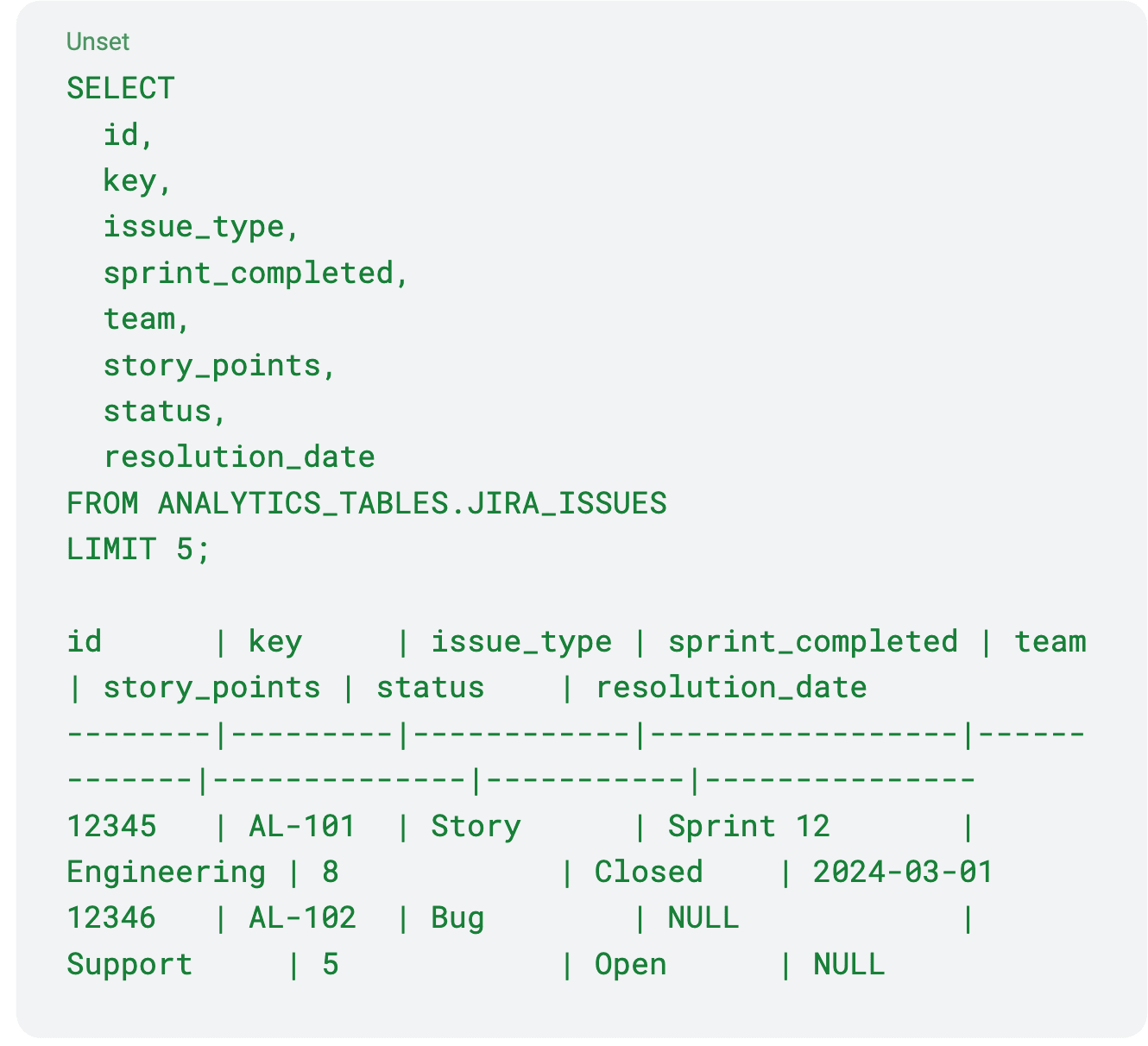
This transformation requires complex SQL that encodes business rules about how your organization uses JIRA. The result is a cleaner table with human-readable values—but it's still not enough.
Step 2: Adding semantic clarity
Even with better field names, users still need domain knowledge to correctly interpret the data. For example, a query counting "open support escalations" might look straightforward:

However, this query misses issues in states like "In Progress" or "Waiting for Customer" that aren't technically "Open" but are still unresolved.
A true data product adds semantic layers that abstract away these complexities:

This allows users to query without knowing status mapping intricacies:

This transformation requires complex SQL that encodes business rules about how your organization uses JIRA. The result is a cleaner table with human-readable values—but it's still not enough.
Step 3: Building context through documentation
Documentation is where data products truly shine. Each field should have comprehensive descriptions that include:
Business definitions
Usage patterns
Edge cases
Historical context
For example, here's a proper documentation for the sprint_completed field:
JIRA issues can be assigned to sprints. A sprint is a period of time that R&D teams organize their work into, typically 1-2 weeks long. Sprint Completed indicates the sprint the issue was in when it was moved to the closed state for the last time. Issues don't have to be in a sprint, and an issue closed while not in a Sprint will have NULL as its Sprint Completed. Different teams may have completely parallel sprint chronologies, though currently all R&D teams are standardized on the same sprints.
This rich context helps users understand not just the technical meaning but the business implications of the data.
Step 4: Ensuring quality through data contracts
A true data product isn't just well-structured and documented—it's reliable. This reliability comes through data contracts that guarantee:
Schema stability - Fields won't disappear unexpectedly
Semantic consistency - Business meanings remain stable
Freshness guarantees - Data will be updated on a defined schedule
Quality standards - Data meets defined validation criteria
The greatest challenge in maintaining these contracts comes from upstream application changes. When JIRA workflows or fields change, downstream data products can break. The solution is aligning ownership of data products with ownership of source applications, making data quality part of the application's responsibilities.
The compound value of data products
While we've focused on transforming a single data source, the real power of data products emerges when they're combined. By building new data products on top of source-aligned data products, organizations can:
Simplify common data combinations
Create reusable assets
Compound value over time through layered products
Key takeaways for data leaders
Data products represents an exciting opportunity to unify data and business goals, but they also demand a reorganization. To leverage them successfully, data leaders need to:
Think like a product manager, not just a data provider—focus on what users need to accomplish
Embed business context directly into your data models and documentation
Create semantic layers that abstract domain-specific complexities
Establish data contracts with clear quality guarantees
Align data product ownership with source application ownership
By transforming raw JIRA data into well-designed data products, organizations enable broader consumption, increase trust, and ultimately drive more value from their data investments.
Next steps
To begin your data product journey:
Identify your most-used but least-understood data sources
Engage with users to understand their analytical needs
Document the business context and rules embedded in your data
Create simplified semantic models that abstract complexity
Establish ownership and quality standards
The path from raw data to data products isn't simple, but the rewards—increased data adoption, reduced duplicated effort, and faster insights—make it well worth the investment.
To learn more:
Explore the Data Products Marketplace
Read the press releases: Alation Agentic Platform and Data Products Marketplace
Explore our professional services offering, the Data Products Playbook
- The challenge: Raw JIRA data is valuable but unoptimized
- The data product approach
- Step 0: Validating use cases and grasping use needs
- Step 1: Creating analytics-ready tables
- Step 2: Adding semantic clarity
- Step 3: Building context through documentation
- Step 4: Ensuring quality through data contracts
- The compound value of data products
- Key takeaways for data leaders
- Next steps
Contents
Tagged with
Loading...