12 Data Management Best Practices Worth Implementing
Published on July 17, 2025

Data is everywhere—your company creates, collects, and stores it every single day. But having lots of data doesn't automatically help your business. The real value comes from managing that data well.
Data management is the practice of organizing, storing, and protecting a company’s information to ensure its accuracy, accessibility, and security. When executed correctly, it helps teams make better decisions and work more efficiently. When neglected, it creates confusion and wastes time (and, ultimately, money).
Data management and data governance work hand-in-hand. Data governance defines how data should be gathered and used within an organization, addressing core questions about data definitions, location, accuracy requirements, access rights, and usage guidelines. Data management then puts those rules into action through daily processes and tools. Governance is the strategy, and management is the execution.
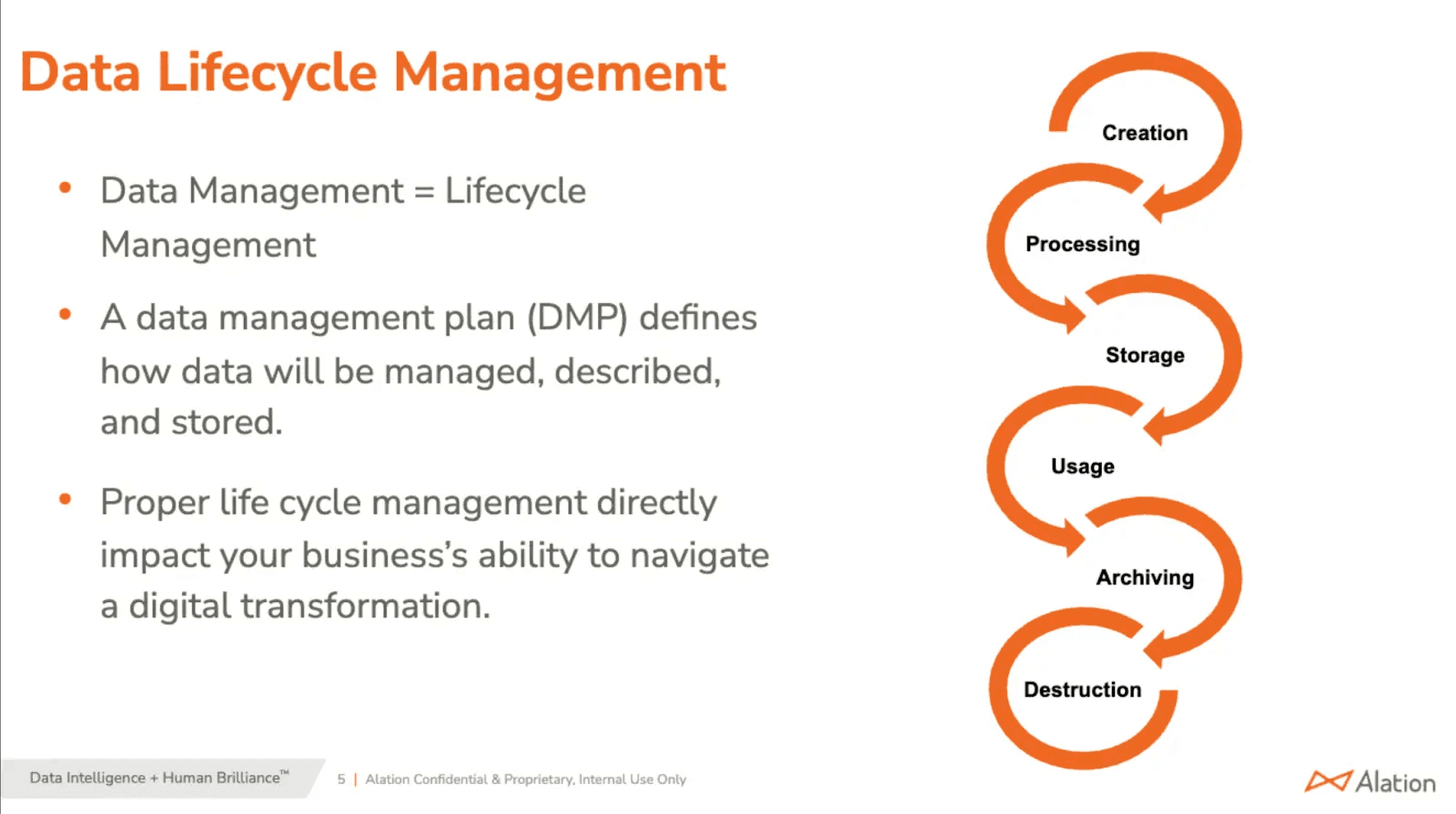
To better understand what effective data management entails, it helps to consider the data lifecycle—the series of stages data moves through, from creation and processing to storage, usage, archiving, and eventual destruction. The diagram below illustrates this progression. Managing each stage with intention is critical to maintaining data integrity and optimizing its value.
12 data management best practices
These best practices can help your organization maintain accurate, secure, and accessible data:
1. Assign data stewards
Data stewards are team members responsible for overseeing a subset of your organization's information to ensure its quality, integrity, and security. Note that data stewardship isn't often a full-time, dedicated position. Instead, these responsibilities are typically integrated into other roles as part of broader job functions. Find individuals who are capable of understanding your data sources, usage patterns, and potential issues that might arise.
Give them clear responsibilities, such as monitoring data quality metrics, approving access requests, and resolving data disputes. When problems arise, they'll make decisions about data remediation, temporary access restrictions, or escalation to IT teams.
Good stewards catch problems early, follow data governance best practices, and answer questions from other teams every day. Without dedicated stewards, data quality management can easily (and quickly) slip through the cracks.
2. Define critical data elements
Critical Data Elements (CDEs) are data points that your organization deems essential for core operations, decision-making, reporting, compliance, and risk management. If unavailable or inaccurate, these data elements could significantly disrupt business operations or regulatory compliance.
CDEs have grown in regulatory importance. For example, Australia's APRA requires financial institutions to identify their most critical data elements under Prudential Standard CPS230. Similarly, regulations like GDPR and CCPA have made certain data elements legally necessary to manage properly.
Start by identifying CDEs related to critical business processes, key reports, and regulatory requirements. Examples include customer identifiers, financial transactions, product data, and personally identifiable information (PII). Once identified, formalize these CDEs through clear definitions and documentation.
Create a clear list of these elements and share it with your team. Once priorities are established, develop a structured strategy where teams dedicate extra monitoring resources, enforce stricter quality controls, and implement swift incident response protocols to safeguard these critical data assets.
3. Standardize metadata
Inconsistent metadata practices create confusion and reduce data discoverability throughout your organization. While people across different roles and departments naturally describe information differently, standardized approaches help teams find and understand data more efficiently.
Set up clear rules for creating and organizing your metadata, including labels, descriptions, and classifications. Establish naming conventions like snake_case for technical fields, require business definitions alongside technical descriptions, and mandate data sensitivity classifications (public, internal, confidential). Following the best practices for managing metadata ensures all data assets maintain consistency, making it much easier to find, understand, and properly use your data across teams.
4. Catalog data assets
Without a data catalog, valuable data often stays hidden and unused. Your team needs a reliable way to keep track of what data exists, where to find it, and how to use it properly. You'll ultimately want one with advanced features like:
Automated lineage tracking: Captures data flow relationships without manual documentation overhead
ML-powered data profiling: Automatically identifies patterns, anomalies, and quality issues across datasets
Collaborative annotation capabilities: Enables crowdsourced metadata enrichment from business users and analysts
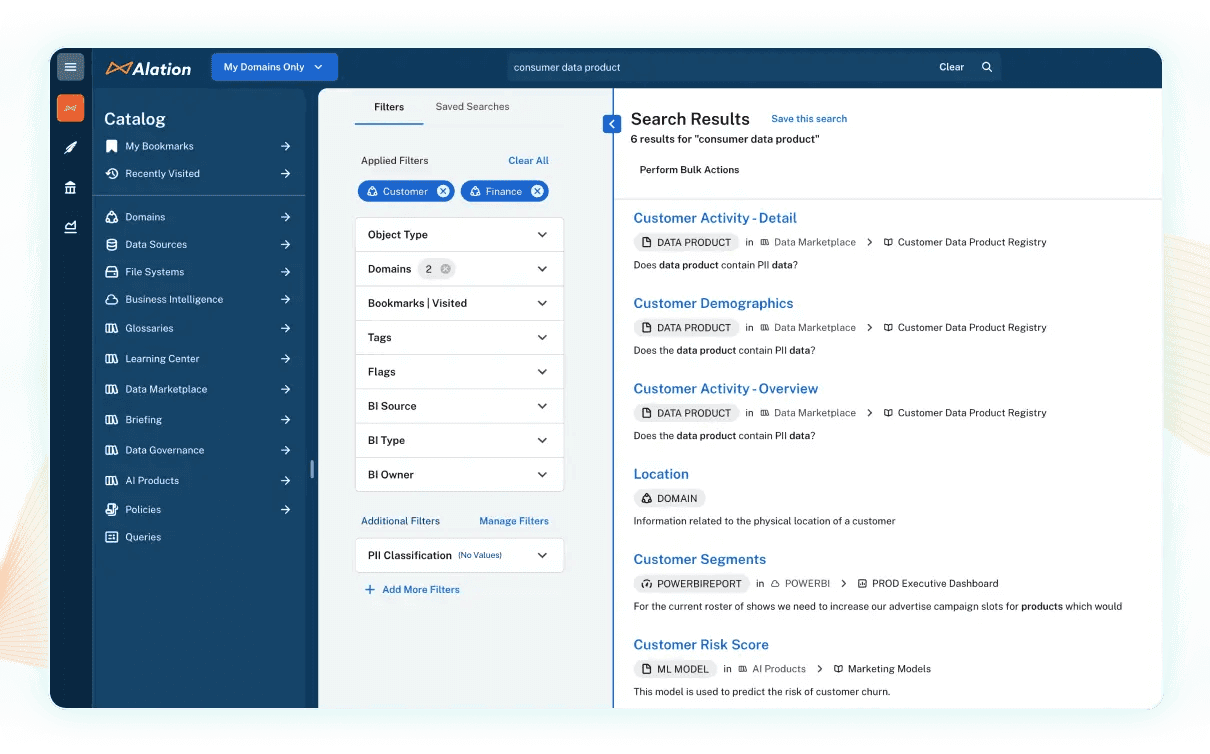
Advanced search filters within a catalog reference metadata to return the most relevant asset.
Put effective data cataloging best practices in place so your catalog stays current and useful. Regular updates and user feedback also help maintain accuracy and improve the overall experience, so be sure not to treat your data catalog as a one-and-done data initiative.
5. Enforce quality checks
Bad data in leads to bad data out, which ultimately results in bad business decisions. That's why data quality checks are essential at every stage of your data pipeline, with automated tests catching errors before they spread through your systems.
Quality checks should verify accuracy, completeness, and consistency. For example, check that phone numbers have the right format, required fields aren't empty, and duplicate records get flagged. These checks are (ideally) automated as data flows through your systems.
Problems may sometimes pop up, like customer segmentation campaigns targeting the wrong audiences or financial reports with inaccurate revenue calculations. To prevent this, implement proactive monitoring. Regular quality monitoring helps you spot issues early and fix them before they impact business operations.
6. Cleanse and normalize data
Real-world data is messy. Information comes from different data sources in different formats, creating inconsistencies that can cause major problems down the line. Data cleansing fixes these issues by standardizing formats and removing errors.
Beyond basic cleansing, normalization helps ensure that similar information is stored in the same way across all systems. For instance, addresses should follow the same format, dates should use consistent patterns, and names should be capitalized uniformly.
Another critical aspect of data cleansing involves effective deduplication, which requires both immediate cleanup and preventive measures. In addition to removing duplicate records where you can, establish automated rules—such as matching algorithms based on key identifiers, validation checks at data entry points, and regular monitoring processes—to prevent new duplicates from entering your system.
7. Secure sensitive information
Customer personal information, financial records, and proprietary business data (like trade secrets or strategic plans) should be secured with extra-special care. Implement Role-Based Access Control (RBAC) so people only access information they need for their specific jobs.
Use encryption to protect data—both when it's stored and when it's being transferred—to make the information unreadable to anyone who doesn't have the proper keys to decode it.
Further, implement data masking for non-production environments. Data masking obscures sensitive information so unauthorized users cannot access or understand it while keeping data usable for testing and analytics. For example, a credit card number like "4111 1111 1111 1234" becomes "4111 1111 1111 XXXX," letting teams test systems without exposing real customer information.
8. Set clear access controls
Decide who can see what data and stick to those decisions. Data access controls (such as the aforementioned RBAC) ensure that people only interact with information they need for their jobs while protecting sensitive data and reducing the risk of accidental changes or deletions.
Create user roles based on job functions rather than individual people. This makes it easier to manage permissions when people change roles or new employees join the company.
Regular access reviews help ensure permissions remain appropriate over time. Conduct quarterly reviews for all user access, plus immediate reviews when people leave or change roles. Remove access for people who no longer need it and update permissions when job responsibilities change.
9. Document data lineage
In-depth lineage documentation requires capturing both technical transformations and business context throughout your data pipelines. Focus on documenting complete history and relationships between data elements using automated tools that track schema changes, transformation logic, and dependency mappings.
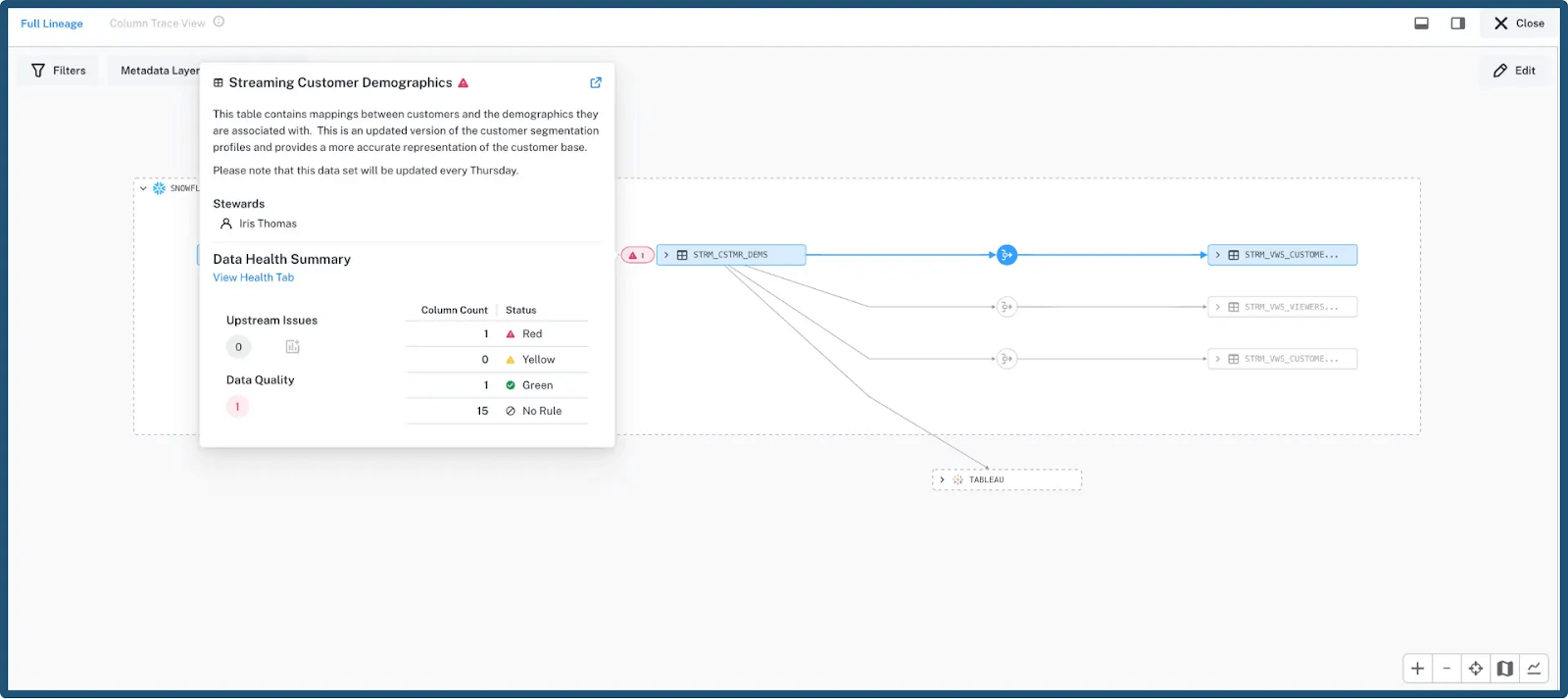
Maintaining high-quality and curated lineage documentation involves several things, including:
Establishing naming conventions for transformation steps
Validating lineage accuracy through regular audits
Ensuring business users can contribute contextual annotations
That way, when problems occur, you can trace them back to their source much more quickly.
This documentation also builds trust in your data. When people can see exactly where information comes from and how it's been processed, they're more confident using it for important decisions.
10. Schedule routine audits
Maintain the health of your data management program by scheduling:
Monthly automated audits of key data quality metrics—completeness, accuracy, and consistency—using tools such as data profiling software.
Quarterly manual reviews of security controls, including user access permissions and compliance policies, via governance dashboards.
These audits should look at both technical aspects (like data accuracy and system performance) and process aspects (like whether or not people are following established procedures).
Use audit results to make specific improvements: Implement additional validation rules for recurring quality issues, revoke unused access permissions, update outdated documentation, or provide targeted training for teams with compliance gaps. Don't just check boxes. Translate your findings into actionable changes that strengthen your data management program.
11. Archive or retire outdated data
Not all data needs to be kept forever (and in many cases, shouldn't). Old information takes up storage space, slows down systems, and can create confusion. Develop clear policies about how long different types of data should be retained. Financial records typically require seven years for tax purposes, though healthcare data follows HIPAA guidelines of six years minimum, while marketing analytics might only need two to three years.
Some data must be kept for legal or regulatory reasons, but other information can be safely deleted after a certain period. Create automated processes to move old data to cheaper data storage or delete it entirely when appropriate.
To implement effective retention policies, use data lifecycle management to automatically trigger actions based on when data was created, last accessed, and when regulatory requirements expire. This keeps your systems running efficiently while meeting compliance requirements.
12. Commit to continuous training
Data management tools and best practices keep evolving, so your team needs ongoing training to stay current with new technologies, regulations, and industry standards.
Hold regular training sessions that cover both technical skills and business processes. This will help your team understand not just how to use tools but also why good data management matters for the organization.
Encourage knowledge sharing between team members. Often, the best insights come from people who work with data every day and understand the practical challenges involved.
Costly data management mistakes to avoid
Even well-intentioned organizations can make expensive mistakes with their data. Here are some common pitfalls to watch out for:
Ignoring data governance can lead to inconsistent practices across teams. Without clear policies and procedures, different groups often develop their own silos and approaches, creating chaos instead of coordination.
Storing everything in data lakes without organization seems like a good idea until you need to find specific information.Managing a data lake effectively means creating organized folder structures, using consistent naming rules, keeping schema registries up to date, and automating cataloging processes. Simply dumping data in without any structure won’t cut it.
Neglecting master data management creates duplicate and conflicting records across systems.It maintains data accuracy by giving you a single, authoritative source of truth for critical business entities.
Failing to document data models leaves future team members guessing about how information is structured. Data modeling, along with the proper documentation, helps with consistency and makes maintenance easier.
Treating data security as an afterthought instead of building it into your processes from the start can lead to expensive breaches and compliance violations.
Avoiding these common mistakes helps organizations build stronger data foundations and prevent costly fixes down the line.
Optimize your data integrations and workflows
Strong data management requires smooth connections between different systems and processes. That being the case, your data pipeline (the series of steps that move and transform information) needs careful design and monitoring. What do those involve?
Automate data pipelines wherever possible. Manual processes are slow, error-prone, and difficult to scale, so automation helps maintain consistency and frees your team up to focus on higher-value activities.
Consider the relationship between data catalog and master data management when designing your workflows. These tools work together to provide comprehensive visibility and control over your information assets.
Monitor your pipeline performance regularly. Set up alerts for failures, delays, or quality issues so you can address problems quickly. The faster you catch issues, the less impact they have on downstream processes and business users.
By using the 12 best practices here, avoiding common mistakes, and continuously improving your processes, you'll build a strong foundation for data-driven success. Platforms like Alation's Data Catalog can help you do just that by automating many key practices, from metadata standardization to lineage documentation.
To see Alation in action and learn how it can help you master various aspects of data management, watch our on-demand demo.
- 12 data management best practices
- Costly data management mistakes to avoid
- Optimize your data integrations and workflows
Contents
Tagged with
Loading...