Data Lifecycle Management and the Role of the Data Catalog

By Joseph Perez
Published on June 25, 2025

What is data lifecycle management?
Data lifecycle management (DLM) is the systematic approach to overseeing and managing data throughout its entire journey, from initial creation and collection to secure destruction. DLM helps businesses turn big data from a risky, highly-regulated, critical mass of numbers into a powerful tool to drive growth. This comprehensive approach ensures that organizations can maximize the value of their data assets while maintaining compliance with evolving privacy regulations and security measures.
With global daily data creation projected to reach 463 exabytes by 2025, equal to about 212.8 million DVDs each day, implementing a robust DLM strategy has become essential for organizations of all sizes. Modern businesses generate massive datasets through various data sources, making it critical to establish clear data retention policies and automated processes to manage this exponential growth.
Benefits of data lifecycle management
Implementing effective data lifecycle management delivers significant advantages that directly impact business operations and compliance posture. Organizations with mature DLM practices can optimize data processing workflows, reduce storage costs, and ensure data integrity across all systems.
The compliance benefits are particularly compelling in today's regulatory environment. According to the HIPAA Journal, between 2009 and 2022, 5,150 healthcare data breaches involving 500 or more records were reported, leading to the leak of more than 382 million medical records. A comprehensive DLM strategy helps prevent such data breaches by implementing proper data protection measures, access controls, and automated data deletion processes when retention periods expire.
The phases of the data lifecycle
Understanding the distinct phases of data lifecycle management enables organizations to develop comprehensive strategies that address each stage's unique requirements and challenges.
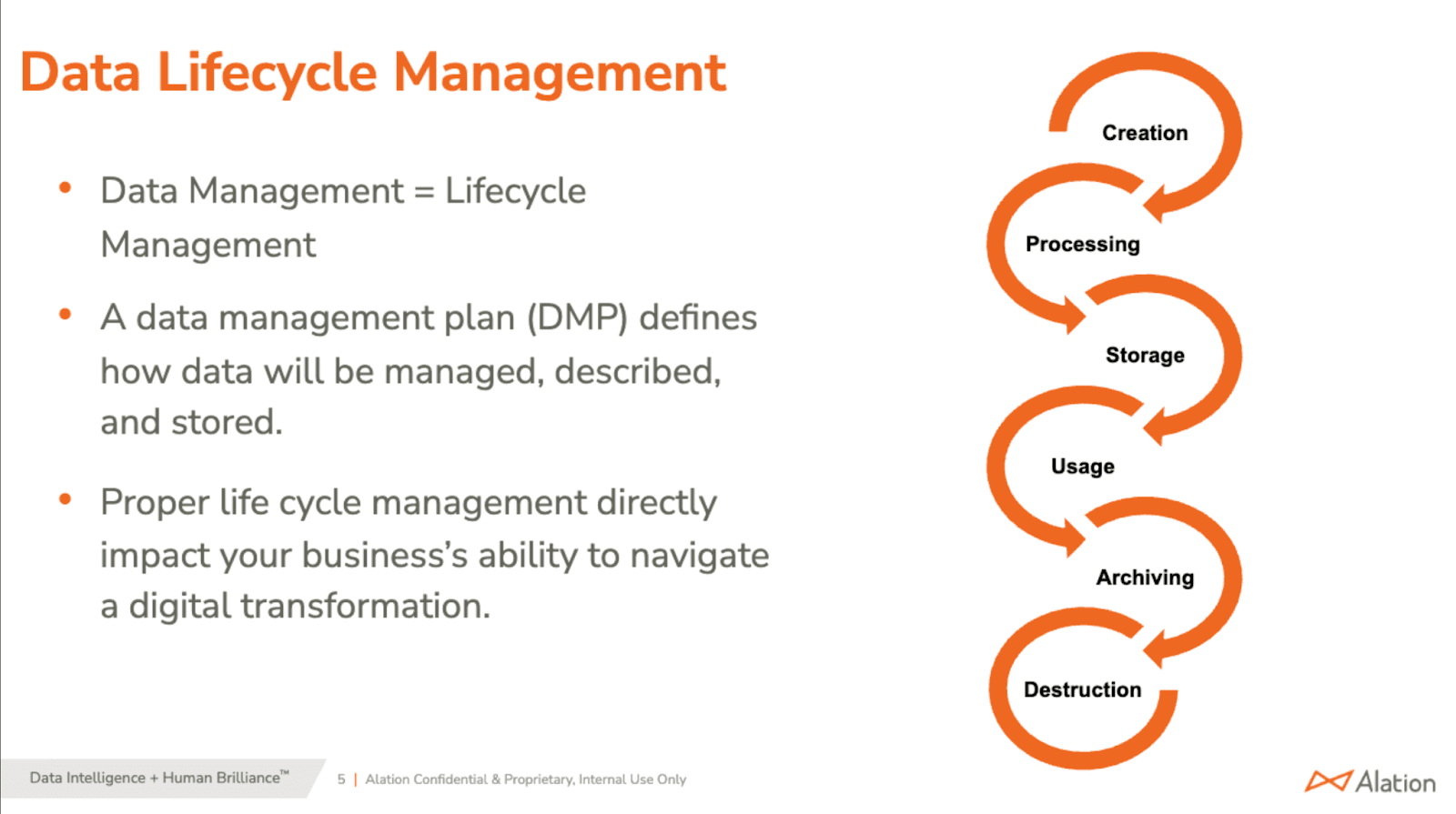
Ingestion: Capturing and integrating data
Data ingestion represents the initial phase where information enters your organization's ecosystem. This process typically occurs through three primary methods:
Data entry or creation: The most common approach involves humans or automated systems capturing information directly into databases or applications. For example, customer service representatives entering support tickets, IoT sensors recording environmental data, or web forms collecting user registrations.
Data acquisition: Organizations frequently obtain data from third-party providers such as Dun & Bradstreet for business intelligence, weather services for predictive analytics, or market research firms for competitive analysis. This requires careful evaluation of data sources and establishing proper data sharing agreements.
Data capture: Automated systems and sensors generate continuous data streams. Manufacturing equipment monitoring production metrics, retail point-of-sale systems tracking transactions, or mobile applications collecting user behavior data exemplify this category.
To optimize data ingestion processes, organizations should implement automated data validation checks, establish standardized formats for incoming data, and create comprehensive metadata documentation. A data catalog serves as the central repository for documenting data sources, lineage, and quality metrics, enabling stakeholders to make informed decisions about data utilization.
Processing: Transforming raw data for analysis
Data processing encompasses the transformation and enhancement activities that convert raw information into actionable insights. This phase includes extract-transform-load (ETL) operations, data cleansing, normalization, aggregation, and integration across multiple systems.
Modern processing workflows leverage machine learning algorithms to identify patterns, detect anomalies, and enrich datasets automatically. For instance, natural language processing can extract sentiment from customer feedback, while computer vision algorithms can analyze product images for quality control.
Organizations should establish data governance best practices during processing to ensure data integrity and maintain audit trails. This includes implementing version control for processing scripts, documenting transformation logic, and establishing data quality monitoring to catch errors before they propagate downstream.
Storage: Securing and organizing data assets
Strategic data storage decisions directly impact system performance, security, and compliance capabilities. Organizations must consider multiple factors when designing their storage architecture:
Location and environment: Data can reside in cloud platforms, on-premises infrastructure, or hybrid environments. Cloud storage offers scalability and cost-effectiveness, while on-premises solutions provide greater control for sensitive information. Hybrid approaches combine both benefits, allowing organizations to keep critical data locally while leveraging cloud resources for less sensitive workloads.
Security and access control: Implement robust security measures including encryption at rest and in transit, role-based access controls, and network segmentation. For organizations handling protected health information, HIPAA compliance requires specific technical safeguards, while GDPR mandates additional data protection measures for European residents' personal data.
Backup and disaster recovery: Establish comprehensive data backup strategies with multiple recovery points and automated testing procedures. Disaster recovery plans should include clear recovery time objectives (RTO) and recovery point objectives (RPO) to ensure business continuity.

A well-designed data management strategy addresses these storage considerations while maintaining optimal data access patterns and supporting analytical workloads.
Usage: Empowering data-driven decision making
The usage phase represents where organizations extract value from their data investments. This requires balancing data availability with security requirements while ensuring that users can discover and access relevant information efficiently.
Data discovery and cataloging: Implement comprehensive data cataloging solutions that enable users to find, understand, and trust available datasets. Catalogs should include business-friendly descriptions, data quality metrics, and usage examples to accelerate adoption.
Access management and certification: Establish clear processes for data access provisioning, including self-service capabilities for approved users and datasets. Implement data certification workflows that validate data quality and authorize specific use cases.
Usage monitoring and optimization: Track data access patterns, query performance, and user feedback to optimize data availability and identify improvement opportunities (many data catalogs automate these processes, making it easy). This information helps prioritize infrastructure investments and guides future data collection strategies.
Archival: Compliant and cost-effective storage
Data archival becomes necessary when information is no longer actively used but must be retained for compliance, legal, or business continuity purposes. Effective archival strategies balance cost optimization with accessibility requirements.
Archival triggers and criteria: Establish clear criteria for identifying data ready for archival, such as lack of access for specific periods, completion of business processes, or regulatory requirements. Automated systems can monitor usage patterns and trigger archival workflows based on predefined rules.
Storage optimization: Migrate archived data to lower-cost storage tiers while maintaining appropriate access capabilities. Cloud providers offer various storage classes optimized for different access patterns, from immediate retrieval to long-term archival with retrieval delays.
Compliance and audit readiness: Maintain detailed records of archived data, including retention periods, access logs, and retrieval procedures. This documentation supports regulatory audits and ensures organizations can locate and access archived information when required.
Organizations should develop effective data retention policies that specify archival requirements for different data types and business functions.
Retirement: Secure data destruction and removal
The final phase of data lifecycle management involves permanently removing data that has reached the end of its useful life. This process requires careful planning to ensure complete data destruction while maintaining compliance with legal and regulatory requirements.
Data destruction policies: Develop comprehensive policies that specify when data must be destroyed, approved destruction methods, and verification procedures. These policies should address various data types, storage media, and regulatory requirements.
Secure deletion procedures: Implement secure deletion methods that ensure data cannot be recovered after destruction. This includes cryptographic erasure for encrypted data, physical destruction of storage media, and multi-pass overwriting for traditional storage devices.
Verification and documentation: Maintain detailed records of data destruction activities, including timestamps, methods used, and verification procedures. This documentation supports compliance audits and provides evidence of proper data lifecycle management.
How data governance supports data lifecycle management
Data experts will recognize DAMA—the Data Management Association—as the global authority on best practices in data management since 1980. At the heart of DAMA’s framework is the Data Management Body of Knowledge (DMBOK), which defines the principles, processes, and standards across areas such as data architecture, quality, security, and most notably, data governance.
Data governance is placed at the center of the DMBOK’s data management wheel for a reason: it serves as the foundation for every other data management function. Rather than treating governance as a standalone activity, modern organizations should embed governance into every phase of the data lifecycle—from collection to processing, storage, sharing, and eventual retirement.

Policy templates and standardization: Effective governance begins with well-defined, standardized policy templates that guide how data is collected, processed, and retained. These policies should align with global and industry-specific regulations such as GDPR, HIPAA, SOX, and Basel III. Standardization helps ensure regulatory compliance, reduces risk, and builds trust across the organization.
End-to-end metadata stewardship: Strong governance also depends on comprehensive metadata management. Capturing technical, business, and operational metadata—including data lineage and impact analysis—helps teams understand how data flows, where it originates, and how it's transformed over time. Automated metadata discovery further accelerates insight and enables more accurate, consistent decision-making.
Automated governance processes: Automation elevates governance by enforcing policies at scale. Automated systems can monitor data quality, flag violations, trigger approval workflows, and produce audit-ready compliance reports—all without manual intervention. This level of operational efficiency ensures that governance is not a bottleneck, but an enabler of business agility.
Zooming out, governance also underpins critical operational tasks—like storage management, security enforcement, and even content classification. It ensures teams align on shared terminology and documentation (e.g., terms, glossaries, articles, and documents), reducing friction in collaboration. As someone who’s worked as a DBA, I’ve seen firsthand how a lack of clarity around these assets can hinder even the most talented data teams.
In platforms like Alation, data governance is not an add-on—it’s woven into every function. The catalog acts as a governance layer across the entire data estate, helping organizations confidently manage the data lifecycle while staying compliant and agile.
How to build your data management plan in 5 steps
For those just starting out with a data catalog, here are the steps I recommend you take to kick off your data management lifecycle.

Step 1: Identify the data to be collected
Begin by conducting a comprehensive data inventory that catalogs all data sources, types, and volumes within your organization. This assessment should include structured data from databases, unstructured data from documents and media files, and streaming data from IoT devices or applications.
Volume and growth estimation: Analyze current data volumes and project future growth to inform infrastructure planning and budget allocation. Consider seasonal variations, business expansion plans, and new data collection initiatives that may impact storage requirements.
Data classification and sensitivity: Categorize data based on sensitivity levels, regulatory requirements, and business criticality. This classification guides security measures, access controls, and retention policies throughout the lifecycle.
Source system integration: Document all systems generating data, including their formats, frequencies, and dependencies. This information supports data collection strategy development and integration planning.
Step 2: Define how the data will be organized
What tools will you need throughout the data’s lifecycle, and which environment will support their usage? You might consider a data warehouse, on-prem, a cloud data lakehouse, or a hybrid environment. Also consider the types of data you seek to leverage, and the regulations governing their analysis. Understanding the implications of these choices will enable to you define your governance policies.
Technology stack selection: Choose storage and processing technologies that align with your data types, access patterns, and scalability requirements. Consider data warehouses for structured analytical workloads, data lakes for diverse data types, and specialized databases for specific use cases.
Data modeling and standards: Develop standardized data models that promote consistency and interoperability across systems. Implement naming conventions, data types, and quality standards that facilitate data sharing and analysis.
Master Data Management integration: Establish master data management practices to ensure data accuracy and consistency across systems. This includes defining authoritative sources, data stewardship responsibilities, and synchronization processes.
Step 3: Document your data storage and preservation strategy
Create comprehensive documentation that defines storage requirements, backup procedures, and preservation policies for different data types and business functions.
Storage architecture design: Document storage tiers, retention periods, and migration policies that optimize cost while meeting performance and availability requirements. Include specifications for backup frequency, recovery procedures, and disaster recovery capabilities.
Data storage and operations planning: Establish operational procedures for storage monitoring, capacity planning, and performance optimization. Include automated alerting for storage issues and clear escalation procedures for critical problems.

Compliance documentation: Maintain detailed records of storage configurations, access controls, and audit trails that support regulatory compliance and security assessments.
Step 4: Define data policies
Is the data you’re collecting pursuant to licensing and sharing agreements or restrictions? For example, is the analysis of sensitive data restricted for legal or ethical reasons? Ensure that data is clearly labeled so newcomers remain compliant in their usage.
Develop policies that govern data usage, sharing, and protection throughout the organization. These policies should address legal requirements, business needs, and risk management considerations.
Privacy and protection policies: Establish clear guidelines for handling personal data, implementing privacy controls, and responding to data subject requests. Include specific procedures for GDPR compliance, HIPAA requirements, and other applicable regulations.
Data sharing and usage guidelines: Define approved data sharing mechanisms, usage restrictions, and approval processes for internal and external data sharing. Include guidelines for data monetization, research partnerships, and vendor relationships.
Security and access control Policies: Implement comprehensive security policies that address authentication, authorization, encryption, and monitoring requirements. Include incident response procedures and regular security assessment requirements.
Step 5: Define roles and responsibilities
How will you keep the data lifecycle train rolling and on time? By recognizing people who are already stewarding data, for example, you can build your team of data stewards (without having to hire new folks). Whatever the case, you’ll need to establish clear organizational structures and accountability frameworks.
Data stewardship program: Identify and formalize data steward roles with specific responsibilities for data quality, documentation, and policy compliance. Provide training and tools that enable stewards to perform their duties effectively.
Cross-functional collaboration: Define collaboration models between IT, business units, legal, and compliance teams that support data governance objectives. Include regular communication channels and decision-making processes for data-related issues.
Performance metrics and accountability: Establish key performance indicators (KPIs) that measure data lifecycle management effectiveness, including data quality metrics, compliance rates, and user satisfaction scores. Use these metrics to drive continuous improvement and accountability.
Those just starting out on their data management journey have a lot to consider! A data catalog (AKA a data intelligence platform) like Alation is a critical foundation for data management, as it serves as a trusted gateway to certified, curated data for a range of users across an organization.
Conclusion: Make data lifecycle management a competitive advantage
As data volumes explode and generative AI accelerates innovation, the stakes for effective data lifecycle management have never been higher. Analysts project the data and analytics market could reach $17.7 trillion—with an additional $2.6 to $4.4 trillion generated by generative AI applications alone. To seize this opportunity, organizations must manage their data not just securely, but strategically.
Implementing strong data lifecycle practices—grounded in governance, automation, and accountability—sets the stage for AI and ML success. Platforms like Alation make it possible to catalog critical assets, automate governance, and empower users with trusted, self-service access to data—all while staying compliant.
Ready to operationalize data lifecycle management? Schedule a demo to see how Alation helps organizations drive smarter decisions, faster innovation.
- What is data lifecycle management?
- Benefits of data lifecycle management
- The phases of the data lifecycle
- How data governance supports data lifecycle management
- How to build your data management plan in 5 steps
- Conclusion: Make data lifecycle management a competitive advantage
Contents
Tagged with
Loading...