The Role of AI and ML in Model Governance

By Neil Raden
Published on June 2, 2022

In part one of this series, I discussed how data management challenges have evolved and how data governance and security have to play in such challenges, with an eye to cloud migration and drift over time. In part two of this series, I’ll dive more deeply into AI/ML and data lineage, in the cloud and otherwise, and discuss how data governance and security can support these critical use cases, wherever they reside.
Governing and Tracking ML/AI: The Rise of XAI
Organizations have attempted to manage the data they use for analytics for decades with techniques that have failed to keep up with the volume of data. But progress has been made, with better methods backed by better tools. Data management is not yet a solved problem, but modern data management is leagues ahead of prior approaches.
However, governance processes are equally important. These include tracking, documenting, monitoring, versioning, and controlling access to AI/ML models. And until recently, such governance processes have been fragmented. Currently, models are managed by modelers and by the software tools they use, which results in a patchwork of control, but not on an enterprise level. Governance is frequently administered at the tool, modeler, or departmental level.
A key benefit of model governance is identifying who owns a model as a company changes over time. For example, if someone worked on a project but has left the company, model governance keeps track of the new model owner, how the model is performing, and any security issues.

With model governance, organizations can closely control model inputs and begin understanding all the variables that might affect their results. In this way, model governance supports Explainable Artificial Intelligence (XAI), which is developing rapidly and showing some maturity. There are mathematical explanations, such as K-LIME SHAP and Disparate Impact Analysis. These methods and their results need to be captured, but how? A data catalog is a central hub for XAI and understanding data and related models.
Recently, Alation CEO Satyen Sagani spoke about the importance of trusted data and how Alation's Data Intelligence Platform helps organizations manage their data on Bloomberg Technology. Listen below to check out the insights.
Other Technologies
While “operational exhaust” arrived primarily as structured data, today’s corpus of data can include so-called unstructured data. Unpacking this data requires other AI tools, such as Recurrent Neural Networks (RNNs) and Attention Neural Networks, which allow data to exhibit temporal (time) dynamic behavior. Unlike feedforward neural networks, RNNs can use their internal state (memory) to process sequences of inputs. This makes them applicable for tasks such as streaming sensor data or comparing incoming data to data that’s already been processed.
Data management can never be a pure, complete process. It requires trade-offs and ruthless prioritization; leaders must pick the issues that have the most significant centrality to the organization’s strategies and provide the most protection against danger while ensuring the organization can be as effective and competitive as possible. The challenge? The cadence of technology innovation surpasses most organizations’ ability to implement each new or improved technique before the next one arrives.
Machine Learning Technology
Many have heralded ML as a promising new frontier. ML uses massive amounts of data to learn, which was not economically possible until the last ten years. All Machine Learning uses “algorithms,” many of which are no different from those used by statisticians and data scientists. The difference between traditional statistical, probabilistic, and stochastic modeling and ML is mainly in computation.
While ML solves problems with gradient methods (optimization), classic statistical modeling is mostly mathematical equation solving. Recently, Judea Pearl said, “All ML is just curve fitting.” He means that ML is not AI because it is not intelligent. It solves problems by brute force. But that doesn’t mean the problems it solves are trivial.
How Data Lineage Is a Use Case in ML
Data lineage is one example of a use case in which ML can play a pivotal role. Data lineage is the process of recording and visualizing data flowing from data sources to consumption. Data lineage uncovers the life cycle of data, revealing its origin, transformation, and lifecycle as it flows. Data lineage allows companies to troubleshoot errors in data processes.
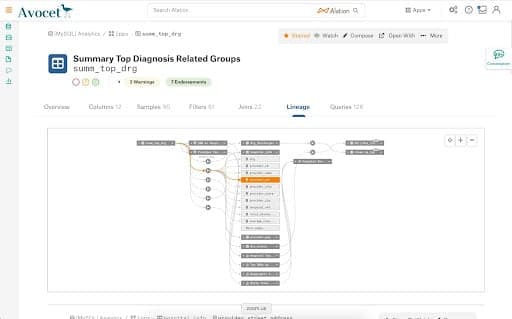
Who created this data? What assumptions were made? Data lineage software can track everything that happens to data once it is identified, but its prehistory may remain a mystery. The only proven technique to deal with this is triangulating the data with other data sources to understand conflicts or inconsistencies.
Conclusion
Data catalogs energize metadata for the entire process of data integration, data preparation, data quality, and many other data management activities, including recommendations. These advanced data catalogs can speed the process and discover relationships and entities impossible with manual methods. Data governance plays a crucial role by activating data stewards around these processes and ensuring compliance. And while ML and AI can assist in essential use cases, such as data lineage, it’s people that are genuinely at the heart of an effective data governance initiative.
- Governing and Tracking ML/AI: The Rise of XAI
- Other Technologies
- Machine Learning Technology
- How Data Lineage Is a Use Case in ML
- Conclusion
Contents
FAQs
What is Data Lineage?
Data lineage shows the history of the data you’re looking at today, detailing where it originated and how it may have changed over time. It’s a reflection of the data life cycle, the source, what processes or systems may have altered it, and how it arrived at its current location and state.
Why is Data Lineage Important?
Data lineage helps you holistically understand the data you intend to use. Was it updated? Did it go through a particular process? Has the quality been evaluated or improved? Was it used by a specific team or in a specific report? The more you know about data lineage, the better decisions you can make about data usage.
Tagged with
Loading...