Why Implementing a Data Mesh Architecture Benefits Your Organization
Published on July 17, 2024

As data continues to grow exponentially, organizations are seeking new ways to manage, access, and leverage this valuable resource. Traditional data architectures often struggle to keep up with the scale and complexity of ever-changing data-driven organizations.
Enter data mesh, a paradigm shift that promises to revolutionize how we handle data. In this blog, we'll explore data mesh, its historical context, the challenges it addresses, and the benefits it offers across various industries. We'll also dive into key use cases, core principles, and practical steps for building a data mesh. Finally, we'll highlight why a data catalog (also known as a data intelligence platform) is essential for a successful data mesh implementation.
What is data mesh?
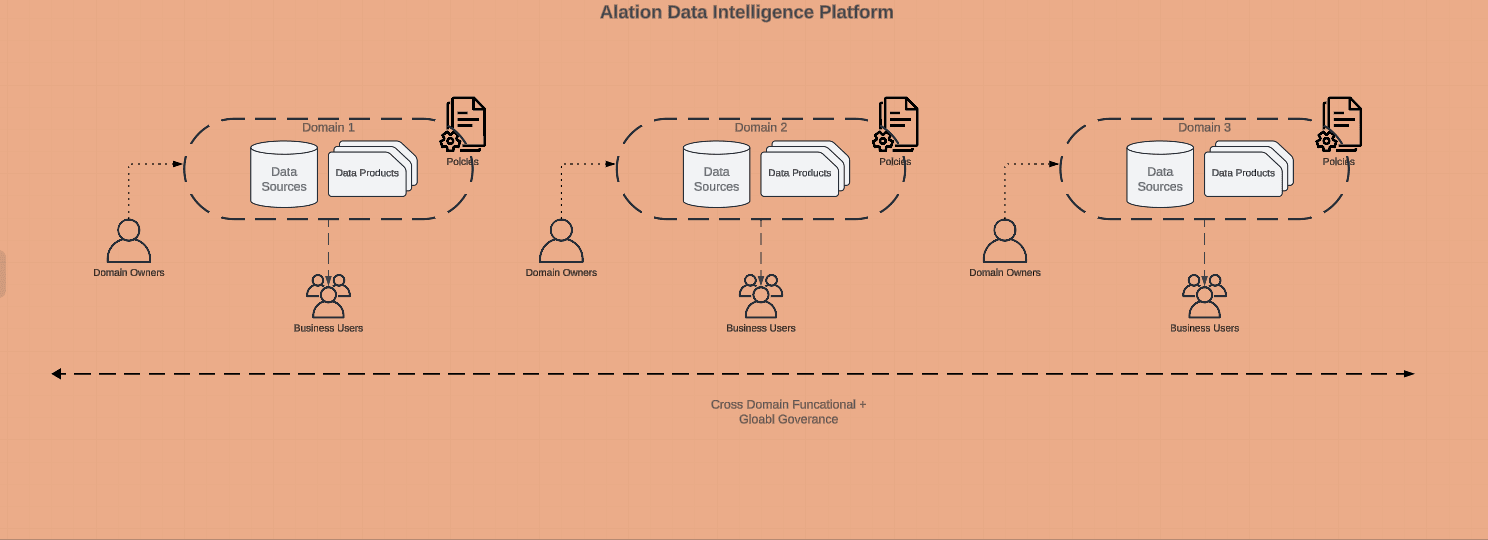
Data mesh is a decentralized approach to data architecture that aims to make data more accessible, manageable, and useful across an organization. Unlike traditional data architectures, which often rely on a centralized data lake or data warehouse, data mesh treats data as a product and assigns ownership of these data products to specific domain teams. This shift empowers domain experts to manage, govern, and use their data more effectively.
Key features of data mesh include:
Domain-oriented decentralized data ownership: Each domain team owns and is accountable for its data products.
Data as a product: Data is treated as a product with clear ownership, quality standards, and usability. These products are consumer-centric, offering useful details to guide usage and address user needs.
Self-serve data infrastructure: Infrastructure is designed to be accessible and usable by domain teams without needing constant support from a central IT team.
Federated computational governance: Governance is distributed but follows a set of standards and policies to ensure consistency and compliance.
A brief history of data mesh
The concept of data mesh was introduced by Zhamak Dehghani in 2019. Dehghani, a principal technology consultant at ThoughtWorks, identified the limitations of traditional data architectures in the face of growing data volumes and complexity. She proposed data mesh as a solution to address these limitations by decentralizing data ownership and promoting a more flexible, scalable approach to data management.
“The current state of affairs is that developers are building applications to satisfy a certain function of the business,” Dehghani elaborates. “And many of those functions today are built without being informed about the data or augmented by intelligence or ML informed by the data. So application developers say, ‘I'm building a GUI. I'm building an e-commerce application, whatever else. I'm building a microservice. My relationship to the data is to store the current state of the data, to satisfy my application's behavior, and optimally store that so I have a really fast read for my application refreshing this screen…’
“So the data is modeled and hidden away behind the application, optimized for a particular feature. And the more we decentralize kind of the application world with microservices-type architectures, the more fragmented that data becomes because that data is only keeping the current state of that application. And that's perfectly fine from an application developer.”
“On the other hand,” she continues, “we said, ‘Okay, actually we need to have this other team, other parts of the organization, dealing with gathering insights, training machine learning models so that we can intelligently act upon some of these transactions and respond and optimize, personalize the user's behavior... and so on.” To overcome these challenges, data mesh aims to make data more sharable and usable for all data users directly at the source.
What obstacles does a data mesh help to overcome?
Traditional data architectures often face several challenges:
Scalability issues: Centralized data lakes and warehouses can become bottlenecks as data volumes grow.
Data silos: Different departments may have their data silos, leading to fragmented data and inconsistent insights (as in Dehghani’s app-developer example).
Dependency on central IT teams: Centralized data management creates bottlenecks and delays as domain teams wait for IT support to access data.
Governance complexities: Ensuring data quality, compliance, and security can be challenging in a centralized model.
All of these challenges make data tough to find, understand, and share across teams. “What data mesh tries to create is some sort of a meta-architecture for data sharing — not pure data sharing, but data as a product sharing and connecting these data products to create higher-value products,” Dehghani points out. “So a scale-out, network-based value-creation model that is purely about data sharing.”
Data mesh addresses these obstacles by decentralizing data ownership, promoting data as a product, and providing self-serve infrastructure, thereby enhancing scalability and shareability, reducing silos, and improving governance.
Benefits of data mesh by industry
Implementing a data mesh architecture offers distinct advantages tailored to the unique needs of different industries. By decentralizing data ownership and promoting data as a product, organizations can achieve improved scalability, better decision-making, and enhanced collaboration. In this section, we will explore how data mesh benefits three key industries: retail, healthcare, and financial services. Each industry faces specific challenges that data mesh addresses, leading to more efficient operations, improved customer experiences, and robust compliance.
Retail
In the retail industry, data mesh can help companies:
Improve customer experience: By providing domain teams with ownership of customer data, retailers can create more personalized and timely customer experiences.
Optimize inventory management: Decentralized data ownership allows for more accurate and responsive inventory management.
Enhance marketing strategies: Data as a product enables more effective and targeted marketing campaigns.
Healthcare
Healthcare organizations can benefit from data mesh by:
Enhancing patient care: Decentralized data ownership allows for better integration and use of patient data across departments.
Improving operational efficiency: Self-serve data infrastructure enables quicker and more accurate decision-making.
Ensuring compliance: Federated governance ensures that data privacy and security standards are maintained.
Financial Services
In the financial sector, data mesh can:
Enhance risk management: Decentralized data ownership allows for more comprehensive and timely risk assessments.
Improve customer insights: Data as a product enables deeper and more accurate customer insights.
Streamline compliance: Federated governance ensures that regulatory requirements are consistently met.
By recognizing and leveraging the benefits of data mesh within their specific contexts, organizations in these industries can drive significant improvements in their data management practices, ultimately leading to better business outcomes and a competitive edge.
Key data mesh use cases
Data mesh's decentralized approach and emphasis on data as a product unlock numerous opportunities for organizations. From real-time analytics to machine learning, data mesh empowers domain teams to leverage data more effectively and efficiently. In this section, we will examine some of the most impactful use cases for data mesh, demonstrating how this modern data architecture can drive innovation, enhance decision-making, and promote data democratization across the organization.
Real-time analytics: Data mesh enables domain teams to access and analyze data in real-time, leading to faster and more informed decision-making.
Machine learning: By decentralizing data ownership, data mesh facilitates the training and deployment of machine learning models across different domains.
Data democratization: Data mesh promotes data accessibility and usability across the organization, empowering more employees to leverage data in their work. (Having domain teams own and steward their own data also supports democratization, as they tend to have the expertise necessary to make that data comprehensible and useful to other departments).
These use cases illustrate the versatility and power of data mesh, highlighting its potential to transform how organizations interact with and derive value from their data. By adopting data mesh, organizations can unlock new possibilities and stay ahead in a data-driven world.
Core principles of data mesh
The success of a data mesh architecture hinges on adherence to its core principles. These guiding tenets ensure that data is managed, governed, and utilized in a way that maximizes its value. In this section, we will go into the four fundamental principles of data mesh: domain-oriented decentralized data ownership, data as a product, self-serve data infrastructure, and federated computational governance. Understanding and implementing these principles is crucial for any organization looking to harness the full potential of data mesh.
The core principles of data mesh are:
Domain-oriented decentralized data ownership: Empower domain teams to manage their data products.
Data as a product: Treat data with the same care and attention as a product, focusing on usability, quality, and reliability.
Self-serve data infrastructure: Provide domain teams with the tools and infrastructure they need to manage and use their data independently.
Federated computational governance: Maintain governance standards across the organization while allowing domain teams the flexibility to manage their data.
Embracing these core principles allows organizations to build a strong foundation for their data mesh architecture, ensuring that it delivers on its promises of scalability, flexibility, and enhanced data management.
It’s important to note that data mesh requires a shift in human behavior. In fact, data mesh “is not a physical layer,” Dehghani clarifies. “It's a logical layer concern. And philosophically I think it’s in conflict with this idea that [people can] ‘keep doing whatever you want to do, unintentionally share data, and then some magical AI will make sense out of it.’ In fact… my kind of value system puts responsibility on humans in saying, ‘In fact, let's get the human in the loop to intentionally build data as a product to emit design and emit the right metadata to serve meaningful data.’"
How to build a data mesh
Building a data mesh architecture involves more than just a shift in technology; it requires a transformation in how data is perceived and managed within an organization. This section provides a step-by-step guide to implementing data mesh, from identifying domains and establishing data products to building self-serve infrastructure and implementing governance standards. By following these steps, organizations can create a robust data mesh that fosters a data-driven culture and drives business success.
Steps to build a data mesh:
Identify domains: Define the key domains within your organization and assign data ownership to the respective teams.
Establish data products: Work with domain teams to identify and define data products, focusing on usability and quality.
Build self-serve infrastructure: Develop the tools and infrastructure that domain teams need to manage and use their data.
Implement governance standards: Create and enforce governance policies to ensure data quality, security, and compliance across domains and the wider organization.
Foster a data-driven culture: Promote a culture that values data and empowers employees to leverage data in their work.
By carefully planning and executing these steps, organizations can successfully transition to a data mesh architecture, unlocking the full potential of their data and driving innovation and growth in today's competitive landscape.
Why a data catalog is a key foundation for data mesh
A data catalog is essential for a successful data mesh implementation because it:
Provides a centralized repository: A data catalog offers a single source of truth for data products, making it easier to find, understand, and use data, particularly outside your domain.
Enhances data discoverability: By cataloging data products, organizations can make data more accessible and usable across domains.
Improves data governance: A data catalog helps enforce governance standards by providing visibility into data lineage, quality, and usage.
Facilitates collaboration: By providing a single place to find and understand data products, a data catalog promotes collaboration and data sharing across domains.
For more information on how a data catalog can support your data mesh implementation, join us for a demo.
Are you already a customer – and looking for help implementing a data mesh? Reach out to your account team to see how professional services can help.
Tagged with
Loading...