Data Mesh Architecture and the Data Catalog

By Talo Szem
Published on May 21, 2025

The “data textile” wars continue! In our first blog in this series, we define the terms data fabric and data mesh. The second blog took a deeper dive into data fabric, examining its key pillars and the role of the data catalog in each. In this blog, we’ll do the same with data mesh, unpacking the four key pillars, with a few notes on the role of the data catalog.
While data fabric takes a product-and-tech-centric approach, data mesh takes a completely different perspective. Data mesh inverts the common model of having a centralized team (such as a data engineering team), who manage and transform data for wider consumption. In contrast to this common, centralized approach, a data mesh architecture calls for responsibilities to be distributed to the people closest to the data. Zhamak Dehghani of Thoughtworks defined data mesh in 2019, tying it to domain-driven design and calling upon data users to “embrace the reality of ever-present, ubiquitous, and distributed nature of data.”
Indeed, decentralization is at the core of domain-driven design (DDD), which divides a large domain into different zones, to be managed by the stakeholders who know those zones best. (This is a software-design approach favored by software leaders, and it’s quickly gaining traction for data leaders of all kinds.) In other words, under a data mesh framework, domain product owners are responsible for delivering data as a product.
But why is such an inversion needed? Because those closest to the data are best equipped to manage it capably. Furthermore, centralization creates bottlenecks. Middlemen — data engineering or IT teams — can’t possibly possess all the expertise needed to serve up quality data to the growing range of data consumers who need it.
As data collection has surged, and demands for data have grown in the enterprise, one single team can no longer meet the data demands of every department. The growing interest in data mesh signals an organizational (rather than technological) shift.
Yet technology still plays a key enabling role in making this shift a reality. So how can you seize the data mesh, and up-level your data management and governance practices to catalyze business success? In this blog, we’ll answer that question by exploring the four underpinning principles of data mesh, according to Dehghani:
Domain-oriented decentralized data ownership and architecture
Data as a product
Federated computational governance
Self-serve data infrastructure as a platform
Then, we’ll also explain how a data catalog plays an instrumental role in supporting a data mesh, particularly as they jointly support all data users with a self-serve platform. We’ll discuss data mesh and its relation to data democratization, challenges and solutions of data mesh, best practices of data mesh, how to avoid common data mesh pitfalls, and more.
Understanding the 4 principles of data mesh
In the following sections, we’ll cover each principle, and provide practical examples of their relevance in real-world enterprise applications.

Principle #1: Domain-driven ownership and scalable data architecture
The challenge of centralized data ownership comes down to lack of depth and breadth of expertise. When the central team lacks the expertise of, say, a marketing function — yet are tasked with serving up marketing data — the quality of that data becomes suspect, and distrust in that data is likely to become a problem. That lack of expertise may lead to bottlenecks in service, as distributors struggle to understand the nature of the request and serve up the data best equipped to address it.
The first principle of data mesh springs from a simple concept: those closest to the data should be responsible for that data. By “responsibility,” we mean the manipulation (creation and transformation), maintenance, and distribution of the data to the consumers who need it within the organization. This stands in contrast to the de facto models of data ownership (lakes and warehouses), in which the people responsible for the data infrastructure are also responsible for serving the data.
Data mesh supporters argue that this centralized model is no longer tenable in the expanding data universe of the enterprise. As data landscapes grow more wild, vast, and complex, centralized data ownership has become unwieldy and impossible to scale.
Remember the idea that those who build the data infrastructure are best positioned to manage its distribution? That model has failed to support rapid data growth. And the central responsible party has grown far removed from the data it is tasked with managing and sharing.
An example of domain-driven ownership is when each team is responsible for its own data domains. For instance, Finance owns financial data, Sales owns sales data, and on and on. Each team manages the ingestion, transformation, and serving of its data, ensuring that the data is accurate, up-to-date, and easily accessible for its specific needs. This promotes accountability and ensures that data is managed by those who understand it best.
A data mesh architecture distributes responsibility of data ownership to those who know that domain of data best. Making the experts responsible for service streamlines the data-request pipeline, delivering higher quality data into the hands of those who need it more rapidly.
A scalable data mesh architecture makes the data easily accessible for various uses across the organization. For example, large volumes of data would be stored in its native format to provide flexibility and scalability. Standard APIs would be used to provision data to other applications and services in support of real-time analytics, artificial intelligence (AI) and machine learning (ML) applications, and other advanced data operations.
Yet some potential downsides to this model exist. Some argue that data governance and quality practices may vary between domains. Duplication of data, too, may become a problem, as siloed patterns emerge unique to the domains that host them. Yet these challenges can be mitigated by putting the appropriate technology in place (more on that later).
Scaling data mesh: common pitfalls and how to avoid them
Scaling data mesh architecture presents unique challenges, including managing inter-domain dependencies, ensuring data consistency, and maintaining robust governance. Common pitfalls include inadequate documentation, lack of cross-domain collaboration, and insufficient automation for quality assurance.
To avoid these common pitfalls, organizations should establish standardized processes, encourage regular audits, and invest in scalable data infrastructure that can evolve with business growth. Addressing these pitfalls ensures that data mesh can scale successfully, supporting a dynamic and resilient enterprise data ecosystem.
The role of data catalogs in data mesh architecture
Data catalogs are a foundational element within data mesh architecture, providing a clear inventory of data assets across distributed domains. In a data mesh setup, the data catalog acts as a crucial bridge, offering metadata and lineage tracking that enables seamless data discovery and use.
By centralizing information on where data resides, who owns it, and how it’s processed, a data catalog strengthens data governance and empowers teams to find and leverage data efficiently.
Key differences between data mesh and data lake architectures
As a quick aside, let’s be sure to understand the differences between data lakes and a data mesh.
While data lakes aim to centralize large quantities of data for analysis, data mesh takes a decentralized approach that allows individual teams to own and manage data within their domains. Unlike data lakes, where data governance and management may become bottlenecks, data mesh addresses scalability challenges by promoting domain-level ownership.
Principle #2: Data as a product
Thus far, we’ve borrowed language from the world of economics to describe the challenge at hand. Data consumers need access to data products they can trust, and distributors play a key role in delivering the best quality data as quickly as they can to serve that need. Small wonder that the idea of “data as a product” has taken off, as demand for great data within the enterprise has surged.
Let’s dive into this idea and unpack how data as a product is a key principle to the value of data mesh.
Physical products make up the fabric of our lives. Let’s take a real-world example in blue jeans. What’s important to buyers (i.e., consumers) of blue jeans?
Purchase experience. How easy is it to find your size and click “buy”? Are there reviews or useful details that inform your decision? How satisfied are you overall with the purchase experience?
Speed of delivery. How quickly did the jeans arrive? If delayed, did you get updates on when to expect them?
Quality of the product. Once purchased, did the jeans tear easily? (setting current fashion aside). Did they shrink two sizes after the first wash? Are they just for this season, or an article you can rely on for life?
To ensure consumer satisfaction, the jeans producer (e.g., Levi’s, etc.) needs to think about all of the above — and then some!
Now let’s apply the same principles to data. If we consider data as a product, the data producers must ensure that their data products check the following boxes (with credit, again, to Dehghani for enumerating these boxes).
What makes a valuable data product?
Discoverable. Easy to find in natural language.
Addressable. Easy to access (once found), assuming the end user has permissions. If they don’t have permissions, it’s vital they have a means to request access, or work with someone granted access.
Trustworthy and truthful. Signals around the quality and integrity of the data are essential if people are to understand and trust it. Data provenance and lineage, for example, clarify an asset’s origin and past usages, important details for a newcomer to understand and trust that asset. Data observability — comprising identifying, troubleshooting, and resolving data issues — can be achieved through quality testing built by teams within each domain.
Self-describing. The data must be easily understood and consumed — e.g., through data schemas, wiki-like articles, and other crowdsourced feedback, like deprecations or warnings.
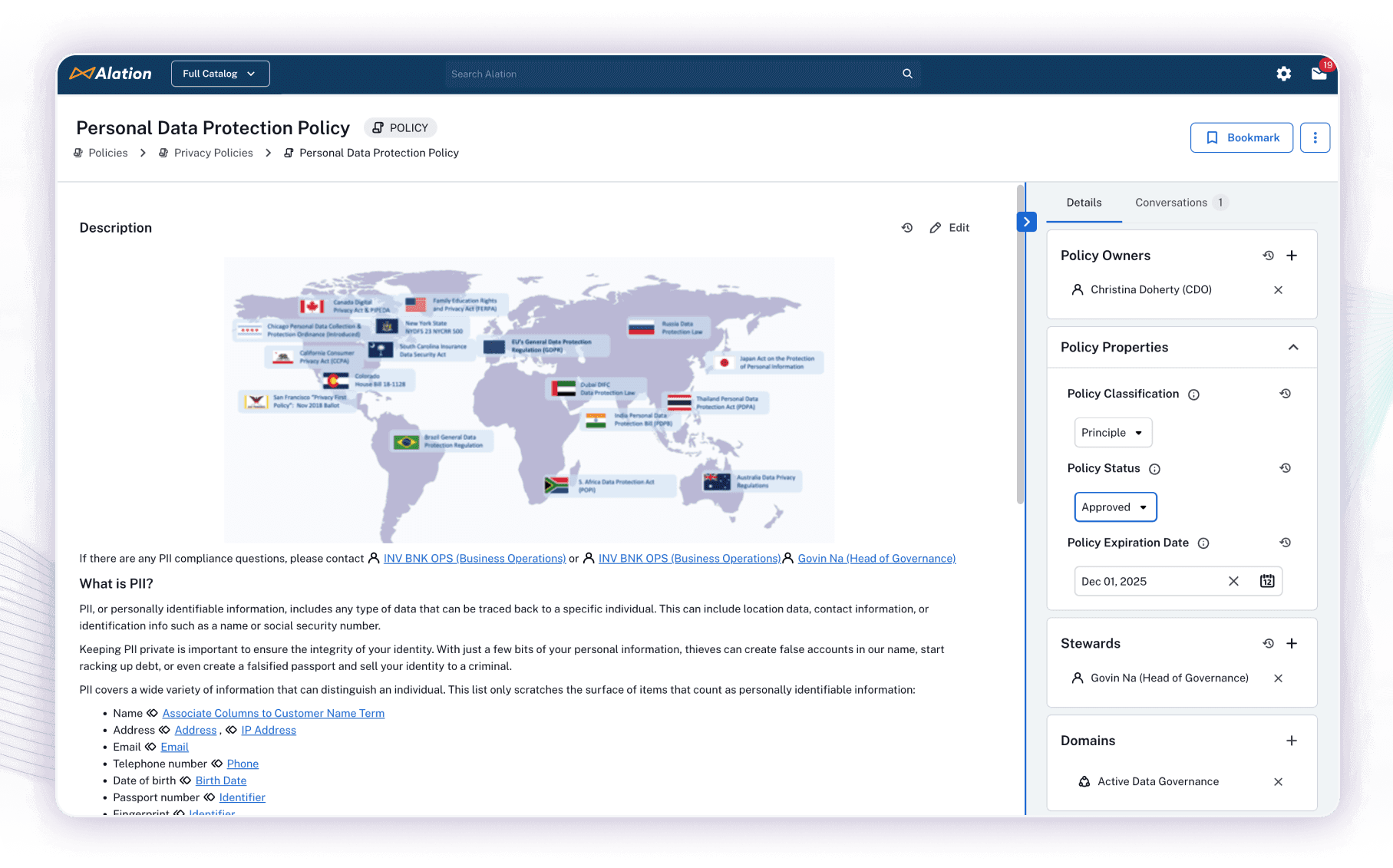
Interoperable and governed by global standards. With different teams responsible for data, governance will be federated (more on this later). But everyone must still abide by a global set of rules that reflect current regulatory laws that respect geography.
Secure and governed by a global access control. Users must be able to access data securely — e.g., through role-based access control (RBAC) policy definition.
Readers may notice these attributes echo other data management frameworks. The ‘FAIR Guiding Principles for scientific data management and stewardship’ is one such framework. FAIR emphasizes that data must be Findable, Accessible, Interoperable, and Reusable to benefit humans and machines alike. Similar to the data-as-a-product approach outlined here, the goal of applying FAIR principles is to optimize the reusability of data. “To achieve this,” the report argues, “metadata and data should be well-described so that they can be replicated and/or combined in different settings.”
A data catalog is essential for several of these capabilities, according to Thoughtworks. In the last section, we’ll tie these key points to data catalog features to demonstrate how they support a self-service data environment.
How data mesh empowers data democratization in enterprises
Data mesh supports data democratization by decentralizing data ownership and making data more accessible across departments. Rather than relying on a centralized IT team, data mesh enables business units to handle their own data, encouraging data fluency and usage. This empowers users across the organization to access insights faster and make data-driven decisions, fostering a data-first culture that is crucial in today's competitive environment.
Best practices for designing self-serve data infrastructure in data mesh
A well-designed self-serve data infrastructure empowers users to access and analyze data independently within a data mesh framework. Key best practices include using intuitive interfaces, providing comprehensive documentation, and implementing secure, scalable storage solutions that meet the diverse needs of various domains. Additionally, integrating automated tools like data catalogs and pipeline builders enhances usability and reliability.
A user-friendly self-serve platform reduces dependency on IT, promotes efficient data use, and fosters a truly data-enabled organization.
Principle #3: Federated computational governance
The problem of data ownership has its roots in the overlap between data management and governance. Historically, data governance and data management were conflated. This is changing. Gartner argues:
Many IT practices proceed from the false assumption that centralized governance also means centralized data management.
As compliance laws grow more onerous, and data landscapes more complex, the need to separate management and governance into distinct disciplines grows pronounced. A data mesh emphasizes human expertise as the engine that drives these disciplines — and interweaves them into a coherent whole.
Indeed, a core appeal of a data mesh and fabric is the implication of interwoven technologies. And as Dehghani points out, “to get value in forms of higher order datasets, insights, or machine intelligence, there is a need for these independent data products to interoperate.”
As previously stated, a data mesh decentralizes the management of data to the relevant subject matter experts. As such, a data mesh implementation “requires a governance model that embraces decentralization and domain self-sovereignty, interoperability through global standardization, a dynamic topology, and, most importantly, automated execution of decisions by the platform.” In this way, a conflict arises: which rules are universal, and which are centralized? Which practices are universal, and which must be tailored by domain?
This is a difficult task to unpack. It demands “maintaining an equilibrium between centralization and decentralization.” It also requires that data governance leaders determine “what decisions need to be localized to each domain and what decisions should be made globally for all domains.” Again, the expertise of those closest to the data is a crucial guiding light to these decisions. These experts will have a comprehensive view of what it takes to produce data of value, and deliver it to consumers in such a way as to guarantee their success.
The future of federated governance
Automation, AI, and ML will play an increasingly vital role in this realm. After all, governance policies and their standards are associated with root data assets, jurisdictions, data locations, consumer locations, and intended uses.
Those associations ‘tell’ data owners who produce products what can and can’t be done — both from a regulatory viewpoint and a best practices one. Rules can be automated based on these associations. These automated rules, in turn, ‘tell’ consumers who request product access that they must adhere to a contract of usage (like a Data Sharing Agreement). Such rules can monitor behavior and ‘tell’ the governing body if everyone is in compliance (and who’s breaking the rules!) These are valuable systems for enterprise risk management. Automation is rapidly making these use-case visions a reality.
Yet traditional data governance has been a challenging legacy to shake off. It forced a top-down, centralized approach to compliance that over-burdened IT, creating data bottlenecks (and frustrated consumers). What’s needed today is a global view of all data, alongside the policies that dictate its appropriate usage.
Ideally, folks have access to the data they need, with just-in-time governance guardrails that guide smart, compliant use. In this way, the regulatory and compliance needs of the business are met, but so too are the needs of data consumers who seek to use data wisely and compliantly.
Principle #4: The self-serve data infrastructure as a platform
We’ve discussed expertise and domain ownership and how this supports data as a product. Now, we turn our attention to technology. What role does technology play in the data mesh? And how can technology utilize a mesh infrastructure to support a self-service environment? Let’s answer this question by persona needs.
What personas benefit from a self-service data mesh?
For producers: Producers need a place to manage their data products (store, create, curate, destroy, etc.) and make those products accessible to consumers.
For consumers: Consumers need a place to find data products, within a UI that guides how to use these products compliantly and successfully.
But to what use case does this apply? Storage? Compute? Networking? Data development environment? Discovery environment? Yes to all use cases!
Three separate planes are needed for both producers and consumers within the self-serve data platform, according to Thoughtworks.
The three technology planes of a self-service data mesh are:
Plane 1: Data Infrastructure Plane. Addresses networking, storage, access control. Examples include public cloud vendors like AWS, Azure, and GCP.
Plane 2: Data Product Developer Experience Plane. This plane uses “declarative interfaces to manage the lifecycle of a data product” to help developers, for example, build, deploy, and monitor data products. This is relevant to many development environments, depending on the underlying repository, e.g., SQL for cloud data warehouses.
Plane 3: Mesh Supervision Plane. This is a consumer-facing place to discover & explore data products, curate data, manage security policies, etc. While some may call it a data marketplace, others see the data catalog as the mesh supervision plane. Simply put, this plane addresses the consumer needs discussed above: discoverability, trustworthiness, etc. And this is where the data catalog plays a role.
How does the Alation Data Catalog support data consumers and producers?
To answer this question, let’s tie data catalog features to our initial points around what makes a valuable data product?
Here are 3 ways a data catalog supports data consumers and data producers:
#1: Discoverability: Google-like search connects consumers to the data products most relevant to their search and project. Producers can influence search rankings by endorsing data, indicating that it’s of high quality and fit for use for a wider audience. And query log processing determines popularity, thereby lightening the producer’s load.
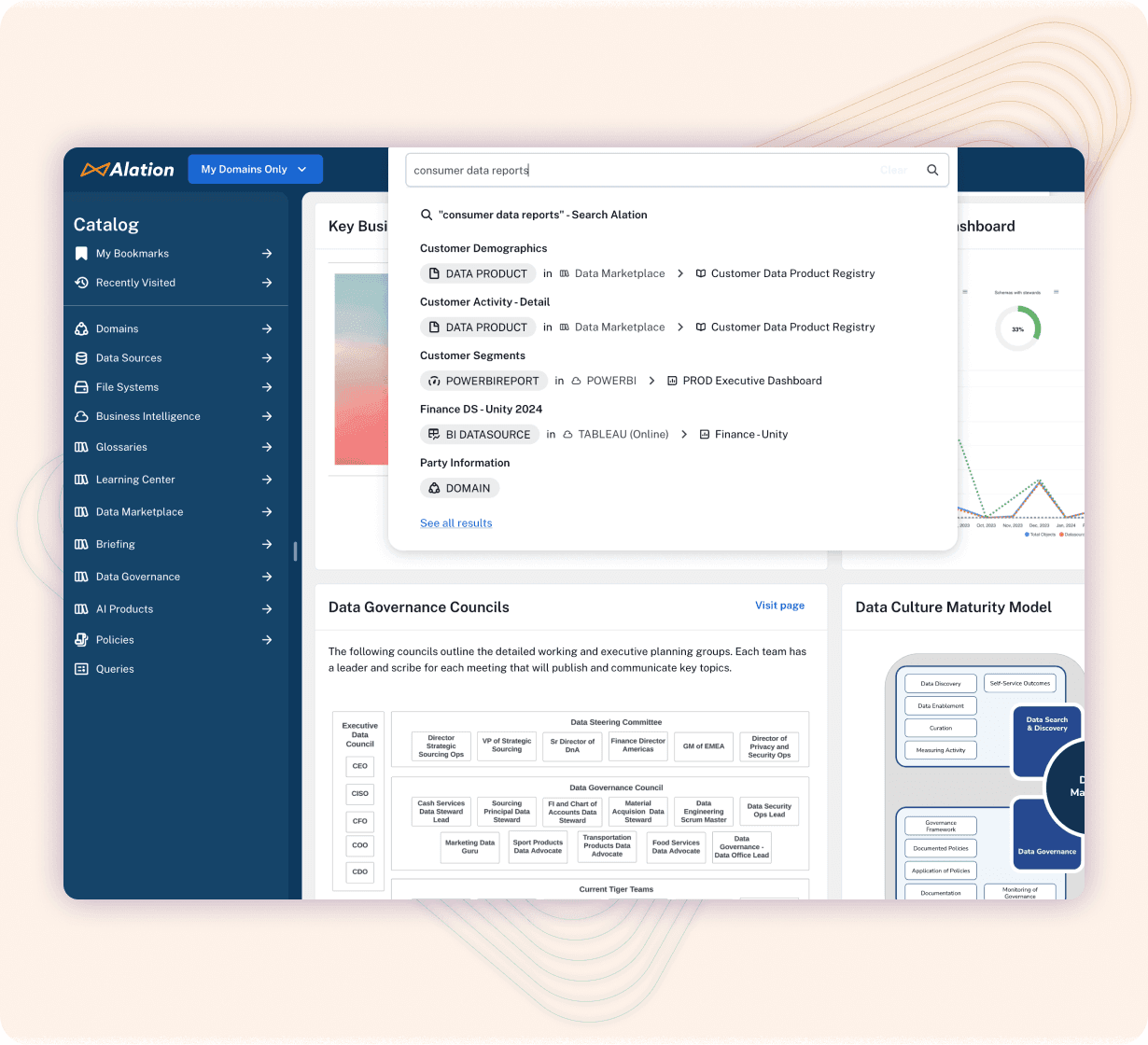
#2: Addressability: Consumers can use the data products they’ve found by referencing the consumable API endpoints, which appear in the data catalog. Producers get the lineage details they need to create models and new assets that don’t break.
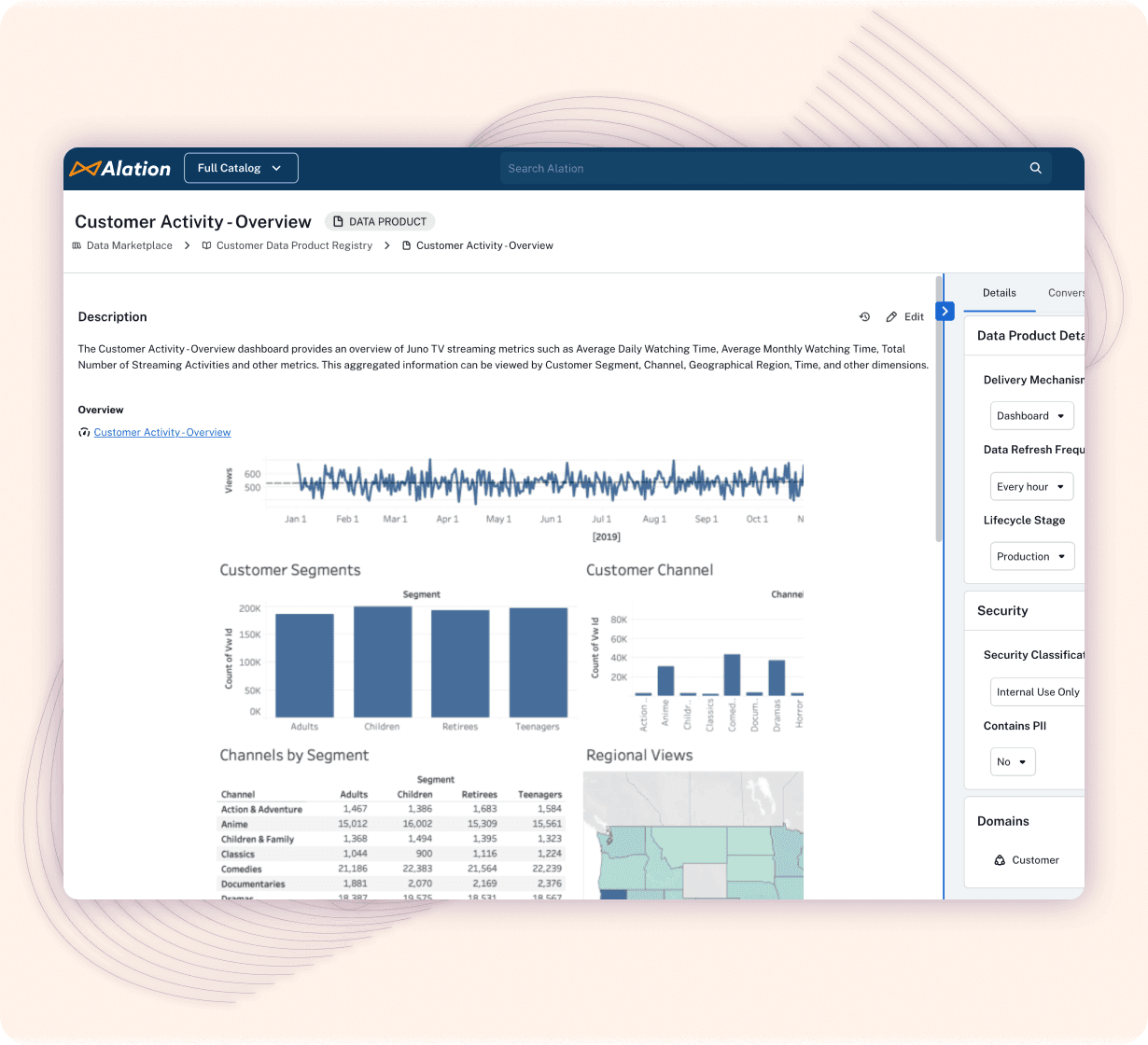
#3: Trustworthiness: Data lineage flags assets that may have issues. The producer can use manual lineage to signal where data came from and whether it should be trusted. The consumer views lineage to understand the trustworthiness and provenance of supplied data.
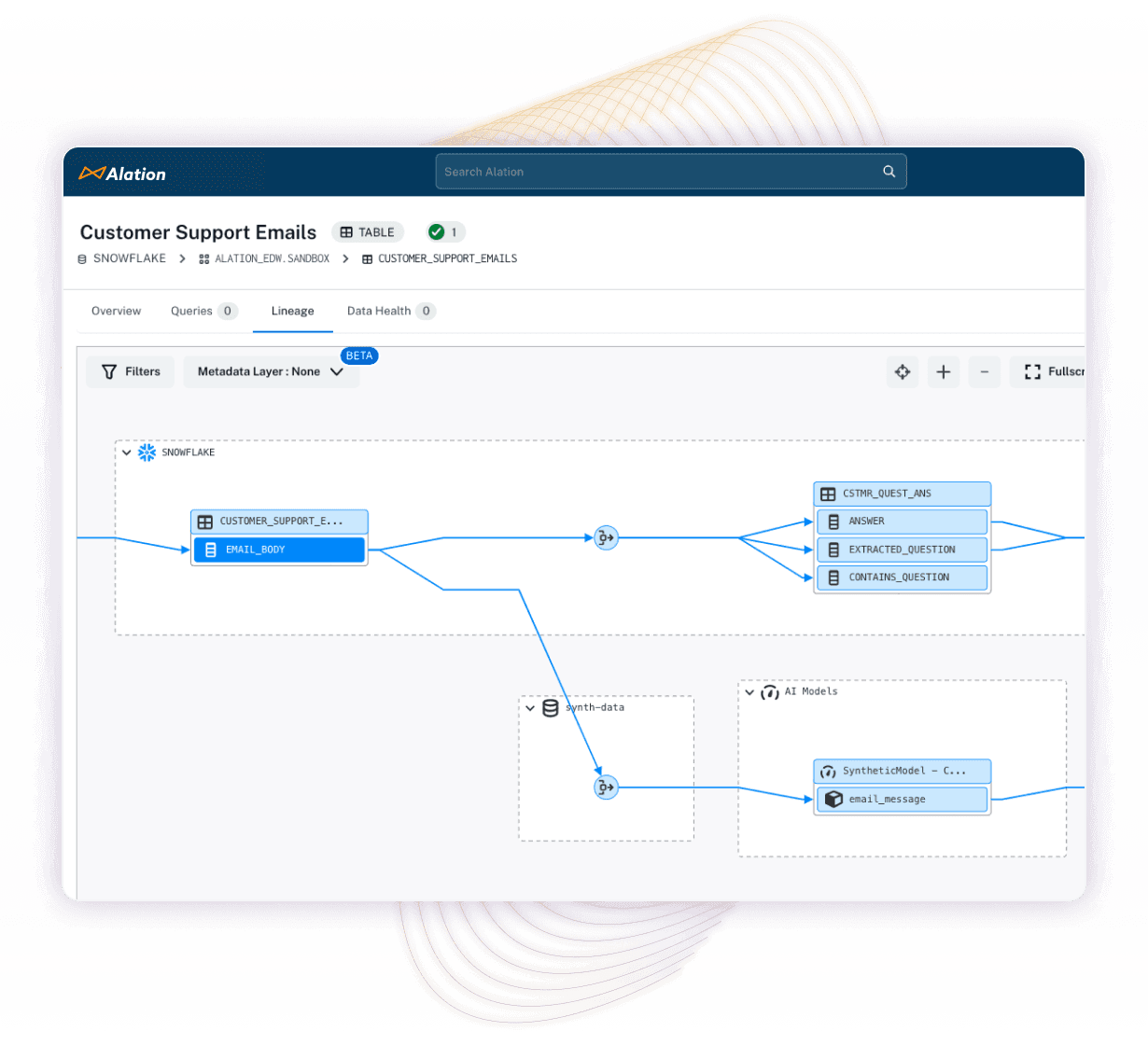
Dashboard of a data catalog displaying how compliance demands are satisfied by capabilities like data lineage.
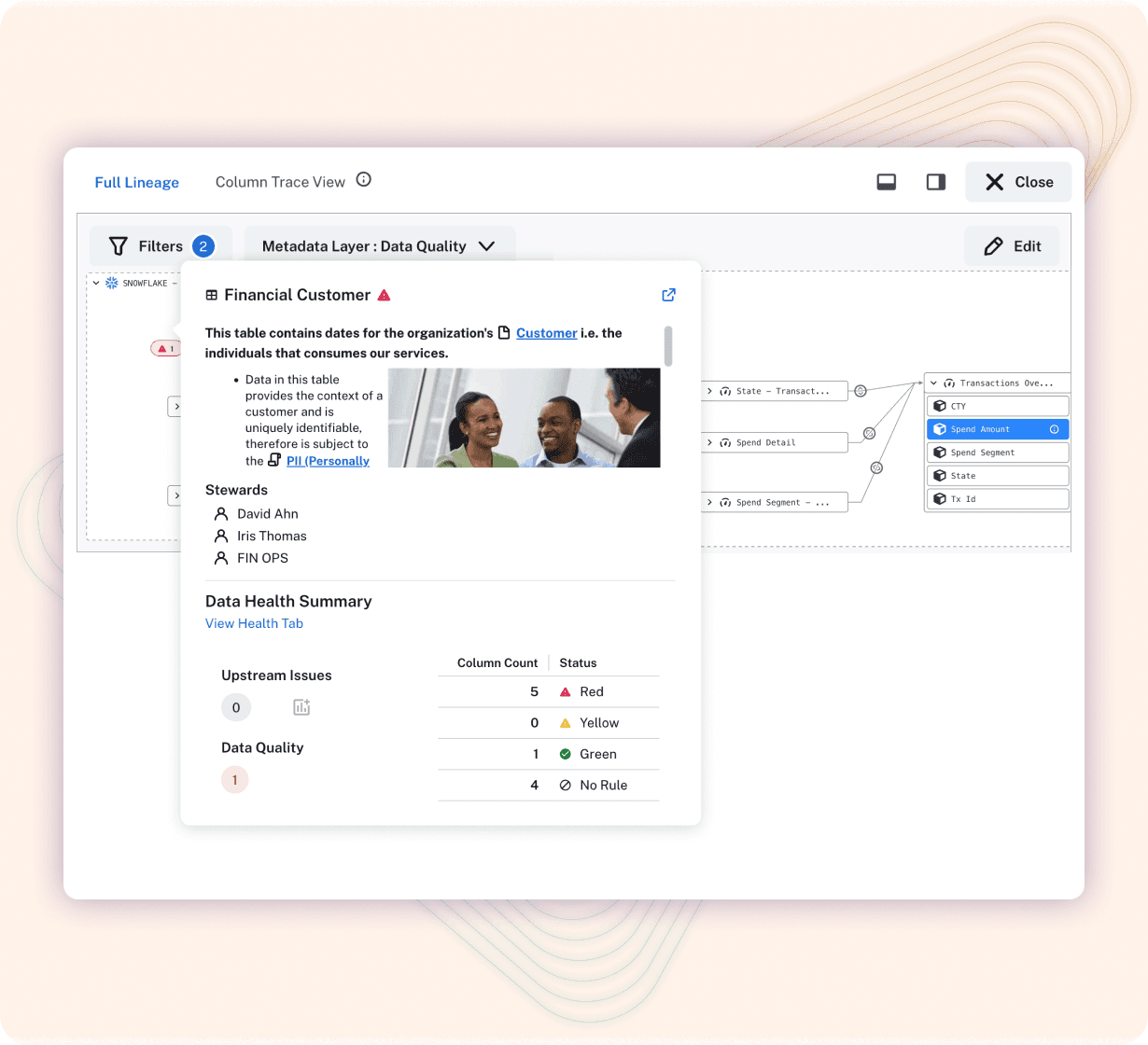
Self-describing data surfaces valuable metadata so consumers and producers alike can holistically understand an asset before using it for analysis.
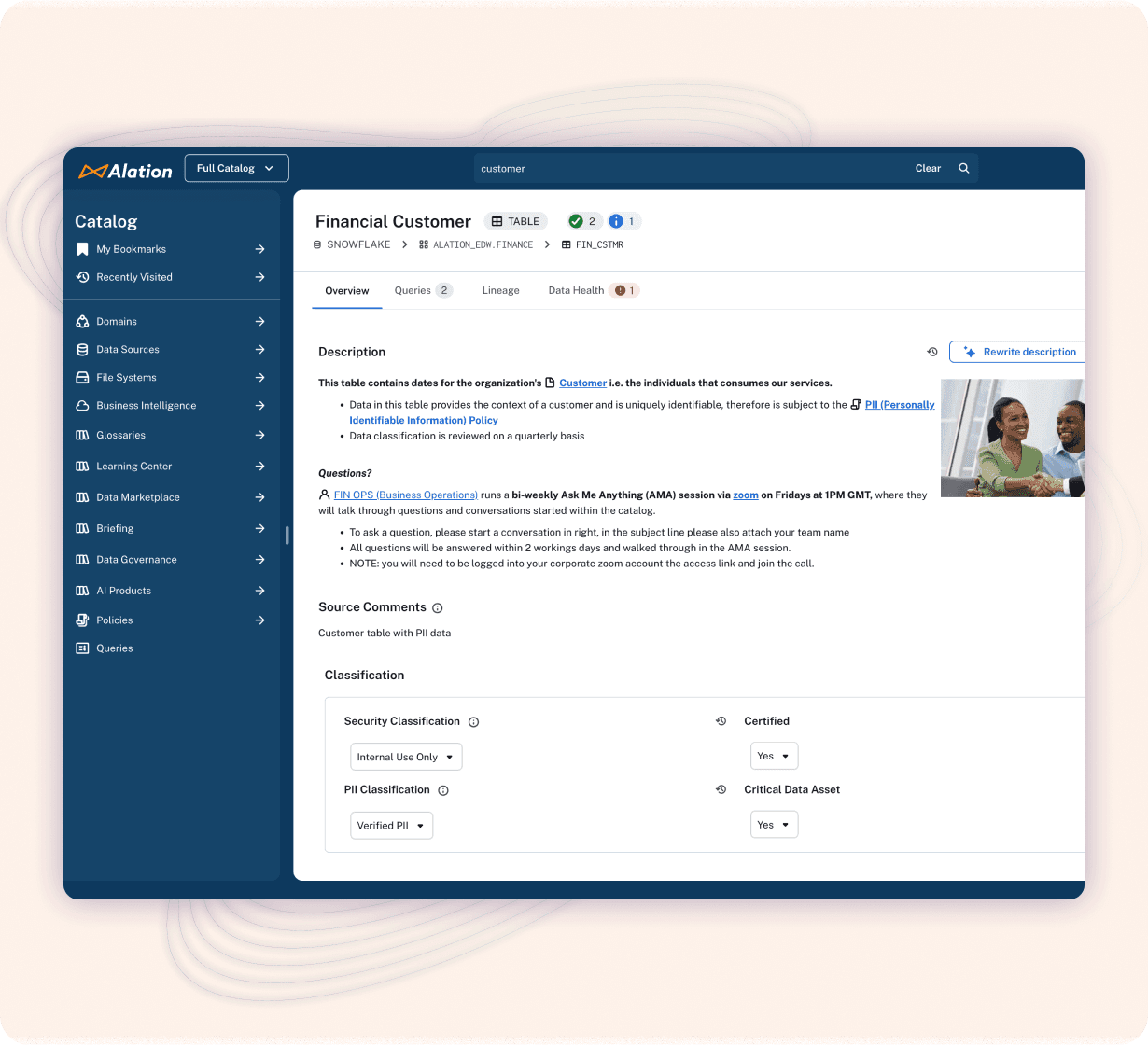
Secure, interoperable, and governed data adheres to global access control & standards and enforces policies. This empowers consumers to use data compliantly, and helps producers do the same.
When do you need a data mesh?
Upon achieving a certain level of data maturity, every organization will need a data fabric. At that stage, some will require a data mesh to complement the data fabric. If your organization has a decentralized structure and boasts mature, agile governance processes, which can be federated, then you should consider a data mesh.
It’s also vital that you consider the people who manage your data. How far along is the maturity of your data management team? Are they overwhelmed and inundated by requests to distribute data? Is quality suffering because your engineers are responsible for distribution?If so, a data mesh can help decentralize those painful processes, and connect data consumers to the right experts (serving as data producers) more quickly.
Challenges and solutions in implementing data mesh in large organizations
Implementing data mesh in large organizations can be challenging due to factors like cultural resistance, technology shifts, and the complexity of managing distributed data ownership. Key strategies to overcome these challenges include starting with pilot programs, investing in cross-functional training, and establishing clear governance frameworks that support consistency across domains.
Adopting an incremental approach and addressing potential roadblocks proactively helps organizations achieve a smooth transition to data mesh architecture, ensuring scalability and long-term success.
The business benefits of data mesh for enterprise decision-making
Data mesh offers significant business benefits by enabling faster, more effective decision-making across enterprises. With decentralized ownership and data managed as a product within each domain, decision-makers gain direct access to relevant, high-quality data tailored to their specific needs. This structure accelerates insights, reduces data bottlenecks, and fosters a proactive, data-driven culture.
Enhancing agility and enabling targeted data use through a data mesh allows enterprises to respond more effectively to business challenges and market opportunities.
Ensuring data quality and compliance in a data mesh model
Maintaining data quality and compliance within a decentralized data mesh model requires robust data governance policies and automated quality checks. Federated computational governance allows each domain to adhere to organizational standards while preserving autonomy.
By implementing quality monitoring tools and embedding compliance protocols directly into the mesh, organizations can maintain high data standards, ensuring that all data used is reliable, accurate, and compliant with industry regulations—essential for building trust in a distributed data environment.
Integrating data catalogs into the data mesh framework
In data mesh architecture, data catalogs play a critical role by enhancing data accessibility and traceability within each domain. A well-integrated data catalog provides vital metadata, lineage, and ownership details that empower teams to discover and understand data assets across domains.
By centralizing this information, data catalogs support federated governance, facilitate compliance, and reduce time spent on data discovery. This ensures that each domain can maintain ownership while contributing to an interconnected and well-governed enterprise data ecosystem.
Here is a great example of a company using a data mesh and a data catalog:
Kroger, the largest retail grocery chain in the US by revenue, built a data mesh architecture to support unique domains, with data fabric "connective tissue" to enable interoperability and data sharing of data products between them.
Using Alation together with Databricks, Kroger has a common language around data, with standardized governance and SLAs for products, as well as automated data profiling, classification, and access control. Data users at Kroger now benefit from a unified view of data assets across the entire enterprise.
Learn more about Kroger’s data mesh and data catalog in this case study.
Data mesh and AI: leveraging AI in a decentralized data architecture
As mentioned above, AI will play an increasingly vital role in federated governance.
Integrating AI into data mesh architecture enables organizations to leverage advanced analytics while maintaining a decentralized data structure. AI enhances the data mesh by automating tasks like data discovery, quality checks, and predictive analytics, providing powerful insights across domains.
With AI models embedded into each domain, organizations can drive real-time analytics and improve decision-making, making data mesh a valuable foundation for AI-driven innovations in a scalable, flexible data architecture.
Conclusion
A surplus of data has led to a surplus of concomitant challenges. To many, data mesh is a promising solution. And as demand for AI-driven applications and data-driven decision making surge, so too does the need for trustworthy data products that can fuel those initiatives. Business teams are tired of waiting on IT to deliver data they can use quickly. And as Gartner puts it, “A data mesh is a solution architecture for the specific goal of building business-focused data products without preference or specification of the technology involved” (emphasis added).
It’s tempting to think that technology alone can solve the challenges of the modern data landscape. Proponents of the data mesh architecture see things differently. They realize that human expertise — with the right supporting technology — is a powerful means of solving modern data challenges. Data catalogs, which offer global standards around compliant data use, alongside data labeling, curation, and valuable crowdsourced feedback, leverage human signals and expertise at all levels to guide smarter human usage. Policy interpretation, meanwhile, is left to the domain owners who know best.
1. https://www.go-fair.org/fair-principles/
- Understanding the 4 principles of data mesh
- Principle #1: Domain-driven ownership and scalable data architecture
- Principle #2: Data as a product
- Principle #3: Federated computational governance
- Principle #4: The self-serve data infrastructure as a platform
- Challenges and solutions in implementing data mesh in large organizations
- Integrating data catalogs into the data mesh framework
- Data mesh and AI: leveraging AI in a decentralized data architecture
- Conclusion
Contents
Tagged with
Loading...