Delete All the Code: Why We Ditched Our Multi-Agent Architecture for a Leaner, Smarter SQL Agent

By David Kucher
Published on September 1, 2025

The only constant in our journey at Numbers Station has been change—specifically, the ongoing need to rebuild our core architecture to keep pace with the accelerating progress in AI models and tooling. This challenge is most visible in our work on our Query Agent. Think of this as ChatGPT for your enterprise data: a system that allows users to describe tasks or ask questions in natural language like “What was our revenue last quarter?” and instantly receive answers grounded in their unique data estate.
But keeping that experience relevant and reliable is no small feat. The rapid evolution of foundation models demands equally rapid innovation from those building on top of them. Staying static means falling behind—so we’ve had to be hands-on and iterative to ensure our software evolves as fast as the underlying models do.
Over the years, we have rewritten a seemingly simple query agent three times. Each rewrite peeled back earlier assumptions and architectural constraints—many of which were once essential to making the system work, but had become blockers as models grew more capable. Our early versions leaned heavily on rules-based parsing and lightly fine-tuned LLMs, with tightly constrained output vocabularies to avoid syntax errors. But as models improved in reasoning and generalization, those same constraints started to limit both accuracy and flexibility as we expanded the Query Agent’s capabilities.
Our latest rewrite removed most of the hierarchical multi-agent architecture we had built just a year earlier – when a single agent was insufficient – and replaced it with a leaner (less mutli-agent) design. The new system is simpler for engineers to extend and maintain, yet it already returns more accurate results in production, and customers have noticed the difference.
Crucially, this rewrite is designed to take advantage of today’s reasoning-centric foundation models. OpenAI’s o3 family, for example, marries chain-of-thought planning with rapid tool calls and rivals far larger models on math and coding tasks—perfect for SQL generation and debugging. Our old multi-agent stack was unable to seamlessly take advantage of these gains; simply swapping in better models delivered no lift because the architecture couldn’t tap their strengths. The new design lets the model handle long-horizon reasoning while we focus on providing streamlined, high-value tools.
In this post, we will walk through each phase of that evolution: what worked, what broke, and what we learned. We will also share benchmark results on our toughest structured-data tasks and offer practical guidance for anyone looking to design and deploy LLM agents for real-world SQL generation.
Single-shot text-to-SQL
Fundamentally, a SQL query generation system accepts a data-related, natural language question or task, and outputs a table with the data that addresses that task. The system must:
Determine the intent of the question or task, in the context of the available data to the user or entity asking the question;
Generate SQL which precisely answers that question, including the necessary filters and correct expressions, and finally
Execute the SQL and return the result table
The simplest approach available was to use a sequence-to-sequence model, which would convert a question to a SQL query. However, our first attempt at generating SQL for data tasks was riddled with failures. Syntax and compilation issues galore, hallucinated columns, joins that explode the number of rows or are invalid to begin with. Back in 2021, generating real customer queries from scratch was a daunting task.
That said, LLMs were powerful enough to understand semantic concepts, like relationships between columns, aggregations, and filters, and how to map those to generic text instructions. Since text-to-SQL failed outright, we dumbed down the problem – SQL-as-classification would do. We found success by borrowing a popular abstraction from charting and visualization tools: creating modular dimensions and metrics that can be combined to create a SQL query. All the LLM would do is select the dimensions, metrics, and filters necessary for a task, then a query engine would deterministically synthesize SQL from the tables and joins we statically defined. See a simplified diagram of the architecture below:
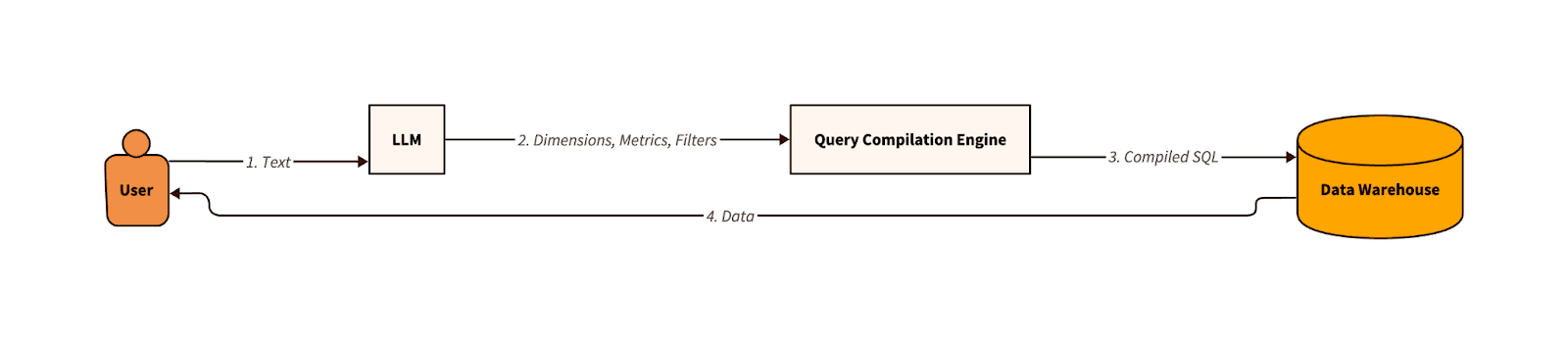
This solved our immediate problems, but the victory was short-lived. The approach was a great start since it was easy to understand and debug, but within six months, we hit roadblocks using this approach for some real use cases. While simple queries worked fine, we failed to generalize to realistic queries, like nested aggregations, pivoting or partitioning results, and using intermediate queries or CTEs to get a final result:
Supported SQL:
SELECT
"Year",
SUM("Sale Amount")
FROM "Table"
WHERE
"Year" IN (2024, 2025)
AND "Returned" = False;
Unsupported SQL:
WITH cte_2024 AS (
SELECT "Sale Amount"
FROM "Table"
WHERE "Year" = 2024
),
cte_2025 AS (
SELECT "Sale Amount"
FROM "Table"
WHERE "Year" = 2025
)
SELECT -- This uses subqueries and CTEs to create a pivoted table
SUM(cte_2024."Sale Amount") AS "2024 Sales",
SUM(cte_2025."Sale Amount") AS "2025 Sales";
Further, many user questions were non-starters to begin with and needed clarification. Additionally, the approach wouldn’t scale since the model couldn’t easily create new metrics to address one-off requests. Single-shot LLM calls are just not viable for a satisfying user experience, which is why we abandoned this approach early on.
Agentic text-to-SQL
There were 2 components that led us to use agents: more powerful models and the ability to provide tools to an LLM. Agents are just a way to use LLMs and tools together to solve a task. The LLM works in a loop: it responds to the user request, using a combination of text and tools until it completes the request, or fails trying. This approach, along with a more powerful model (namely GPT-4), challenged our assumption that generating SQL directly was impossible, so we took the plunge.
Surprisingly, newer models were capable of generating correct SQL across a variety of schemas! Well, for the most part. Introducing many tables and joins was too complex, but the model could faithfully repeat metric expressions, and even make new ones given the templates we provided. If a SQL Agent could be this powerful, how much more would a suite of agents, composed together to complete a wide variety of data tasks? The one remaining question was: How should we architect the interaction of multiple agents?
Hierarchical agents
Our initial agentic approach followed a hierarchical design pattern and the division of responsibility.
A central planner agent orchestrated a set of independent expert agents with unique responsibilities. The planner breaks down a request into sequential sub-tasks, which it accomplishes with the help of the appropriate sub-agent. Consider the following request: “Make a chart of the number of products sold by product category”. The planner would first need to search among available datasets to find one with relevant data, construct and execute a query, then infer an appropriate chart and generate one, each of which requires a separate sub-agent:
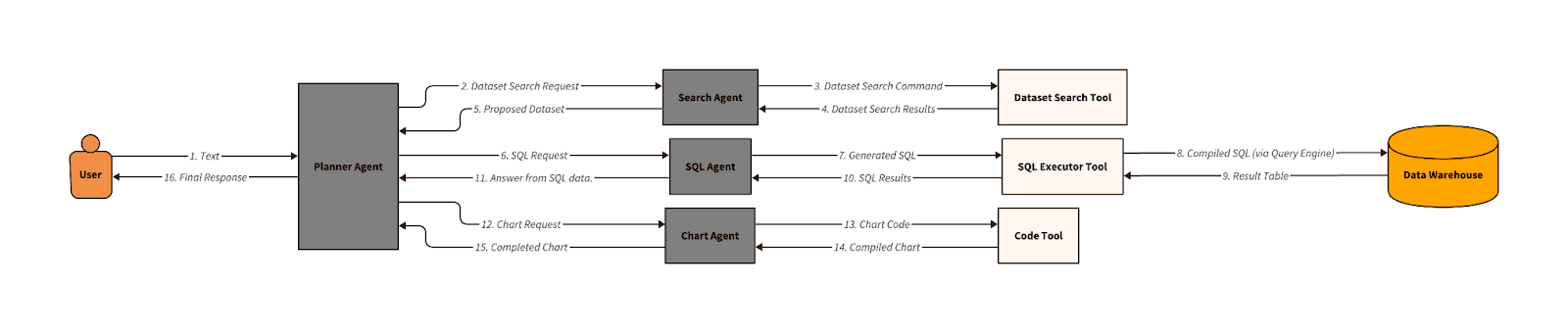
If a user's question was too vague (“Which products have the best sales?”), the planner could let the user know, asking which columns or metrics it should use to measure “best” or “sales”. If the agent generated SQL with a syntax issue or compilation error, our SQL Executor tool responds with an error message, and the agent would rewrite the query, aware of the problems with the last one. This was a leap forward in capability and allowed us to create agents that could be composed for all sorts of data tasks, like chat or pre-defined workflows.
Fast-forward another 12 months, and we recently hit the limits of our architecture yet again. While we had built amazing user experiences from these agents, addressing new types of questions with ease, we failed to handle advanced use cases well. Among these were exploratory questions, where the Query Agent would first need to profile a warehouse to find relevant values, then include only the relevant columns and filter values based on those queries. This required long-term planning and exploring multiple approaches to address data tasks.
While the hierarchical model worked well for straightforward tasks, it consistently struggled with complex, multi-step queries. Despite extensive tuning, the system often failed to balance two needs: delivering quick answers for simple questions and enabling the deeper, exploratory behavior required for harder ones. With multiple agents to adjust, it was also unclear where fixes should be applied—should the planner give more detailed instructions, or should the agents themselves act more autonomously? These limitations ultimately pushed us to explore a new approach.
Advanced reasoning
We observed that different questions required different levels of investigation. Some were trivial (“How many customers bought milk last quarter?”), others were complex (“Of the customers that purchased milk last quarter, break down their spending patterns by product category as a percentage”).
Inspired by Anthropic’s deep research system, we maintained a multi-agent approach, but transformed how we executed planning and division of responsibility. This new design used a lead agent, which could create a number of sub-agents, depending on the complexity of the task. The lead agent and sub-agents have access to the same tools, which allows the lead agent to respond to trivial questions or explore multiple approaches to a problem via its sub-agents. This lends itself well to read-heavy operations, where the agent will execute many exploratory queries to understand the dataset and build evidence for a final response. Instead of using independent sub-agents with unique responsibilities, the planner could investigate multiple approaches for the same question with replica sub-agents. Below is an example of a request involving two subagents, along with a direct call to the chart tool:
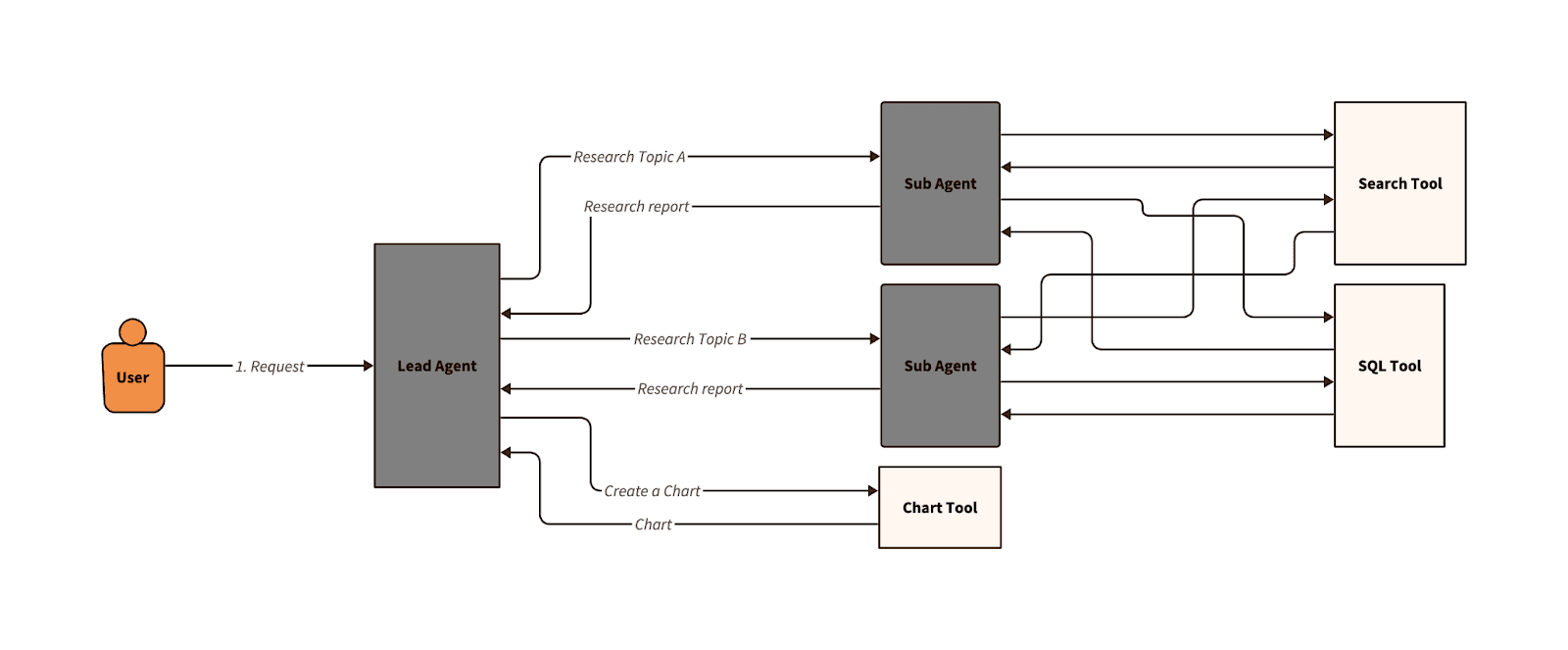
While this approach solved our issues with exploratory queries, it still had the same drawback as the first multi-agent design – it was difficult to maintain and optimize.
Scaling test-time compute for SQL agents
One of the most exciting advancements in agents is scaling test-time compute and deep research systems. These involve using chain-of-thought reasoning, iterative refinement, and investigating multiple paths to solve a problem. All of these generate many more tokens, but in return produce much more impressive answers. If we could rely on the generic problem-solving abilities of a reasoning model, then we could significantly reduce the implementation complexity of our agents, making it easier to maintain and debug requests.
Further, this approach enables our system to improve along with the improvements to problem-solving in the latest and greatest model release. We are excited to take advantage of the rapid pace of improvement in the span of just a few months to years, illustrated by the impressive performances of reasoning models on difficult benchmarks such as Humanity’s Last Exam.
Choosing an agentic architecture
Excellent resources are available on agentic architectures and the pros and cons of each one. Yet we found it helpful to try a number of them, so here is a summary of our experience. (We omit single-shot LLM calls since they are only suitable for trivial tasks.)
Hierarchical agents
Hierarchical agents benefit when there are multiple, independent tasks to complete that do not require synchronization and will not overlap with each other. Examples include separating out prompts for a search agent, query agent, email agent, charting agent, etc.
Advanced reasoning
On the other hand, advanced reasoning allows for scaling up and down complexity for a given task and investigating multiple approaches to the same task. This is great for fostering exploration when the approach to a task is not straightforward.
While multi-agent architectures have benefits, they also have significant overheads, like difficulty debugging errors, reproducibility, and robustness across task complexity. Starting with a single agent is likely the best approach, and only scaling up to multiple agents if the task requires it.
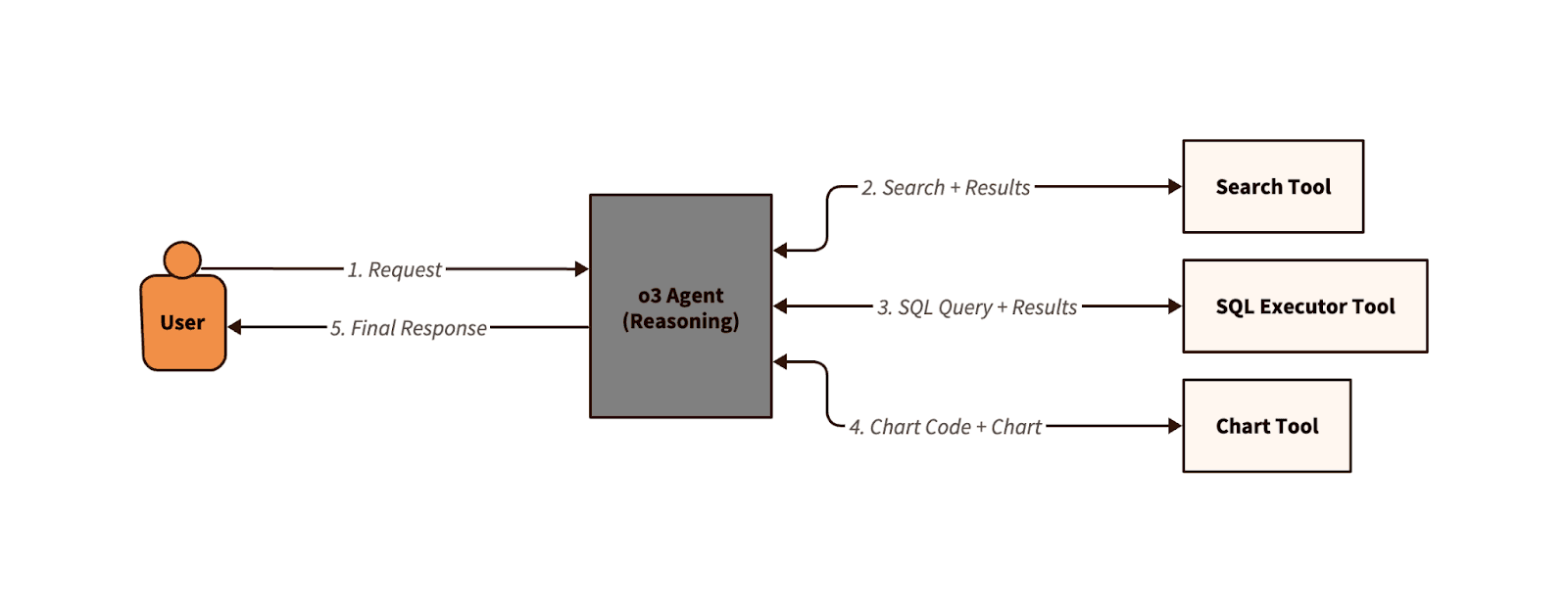
o3 Agent
While early models struggled to handle long-term planning, more recent models like OpenAI’s o3 (and even 4.1 with the right prompt) are fantastic at chaining tools and using them in parallel to accomplish tasks. With proper tool design and context management, these are a simple and effective starting point for user applications and most tasks. (Note that “tools” may in fact be agents themselves, but they are much more limited in scope than a single agent, and do not use a reasoning model. Only consider multi-agent systems if there are independent instructions/tools required for different sub-tasks, or when a single agent fails to accomplish the task.)
Our experimental results below compare the 3 viable agentic approaches across Accuracy (using a hybrid LLM as a judge), Runtime, and Number of Tokens. To differentiate the approaches, we used a benchmark of our hardest SQL tasks:
Metric | Hierarchical agents | Advanced reasoning | o3 Agent |
Accuracy (higher is better) | 59.87% | 72.37% | 77.63% |
Average End-to-End Runtime (s) (lower is better) | 22.06 | 32.04 | 39.91 |
Average Number of Completion Tokens (Rounded to the nearest token) (lower is better) | 393 | 1038 | 1259 |
The experimental results confirm that scaling test-time compute, as measured by the number of generated tokens, correlates with higher accuracy. While different architectures each have their own strengths and weaknesses, we found that the simplest approach is often the best – completing the circle from our first approach years ago. While multi-agent architectures have their advantages, a reasoning model designed for solving tasks can outperform them.
The exciting news is that models and reasoning architectures will only continue to improve. Our task is to make excellent tools and agents for structured data, and our capabilities will only expand rather than be hindered by simplified architectural choices. The key we’ve learned is to design our tools such that they grow with models – not plateau. Today’s hiccups will be trivial tomorrow, so re-use rather than rebuild!
Curious to learn more about using AI agents for data management? Book a demo with us today.
- Single-shot text-to-SQL
- Agentic text-to-SQL
- Hierarchical agents
- Advanced reasoning
- Scaling test-time compute for SQL agents
- Choosing an agentic architecture
Contents
Tagged with
Loading...