
A data catalog is a repository of data assets with information about that data. By aggregating metadata—“data about data”—in one place, it helps users discover, understand, and trust dashboards, reports, files, and databases. Each asset is enriched with descriptive, technical, operational, and governance details, giving people the context they need to use data effectively.
In the age of AI agents, this role has become even more critical: a well-governed catalog doesn't just help humans find datal; it gives AI agents the context they need to reason accurately, act reliably, and produce outputs an enterprise can defend.
In large enterprises, where ecosystems are vast and fragmented, a catalog unifies sources into a single view. This eliminates silos and enables users to search, explore, and share data with confidence.
Modern catalogs use automation and AI to keep metadata current, enable plain-language search, and map relationships across assets. These features accelerate discovery while supporting data governance, compliance, lineage, data quality, and self-service analytics. Today, the data catalog acts as the control center for enterprise data intelligence, driving cross-team collaboration and informed decision-making at scale.
The significance of data catalogs
The role of data catalogs has evolved significantly over the years. Once limited to housing data dictionaries and business glossaries, today they have grown to become a unified knowledge layer that helps everyone in an organization better understand and use data. Far from static repositories, modern data catalogs actively support people and business processes to become more data-driven.
Organizations that have adopted data catalogs consistently outperform their peers who have not yet implemented one. According to the McKinsey Global Institute, data-driven companies are 23 times more likely to acquire customers, six times more likely to retain them, and 19 times more likely to be profitable. These benefits stem from their ability to leverage data more effectively, improving everything from operational efficiency to customer experience and strategic decision-making.
That advantage is now accelerating. As enterprises deploy AI agents to automate decisions, speed up analysis, and power intelligent applications, the data catalog has become the critical dependency. An agent is only as accurate as the knowledge it draws from. Without a governed catalog providing trusted metadata, business definitions, and institutional context, AI initiatives stall: agents hallucinate, use the wrong metrics, and produce outputs that can't be traced or defended. For these reasons, organizations that already have strong catalog foundations are discovering they can move from AI pilot to AI production significantly faster than those starting from scratch.
Still, many companies are determining what a data catalog is and why they need one. Let’s address these questions by exploring the core capabilities of a data catalog, starting with metadata management.
What is metadata?
Fundamentally, metadata is “data about data.” Metadata helps people understand the data's content, physical structure, and purpose, making it easier to organize and describe it to others so they can use it. Metadata can be employed with various data formats, encompassing documents, images, videos, databases, and beyond.
Metadata is everywhere. Take digital photos as an example. While the actual photo might be considered the data asset, robust metadata describes it. This includes technical details about the camera model, aperture, shutter speed, date/time, filesize, and more. From a descriptive perspective, metadata may consist of captions, people, location, etc. This metadata provides additional practical details that support comprehension.
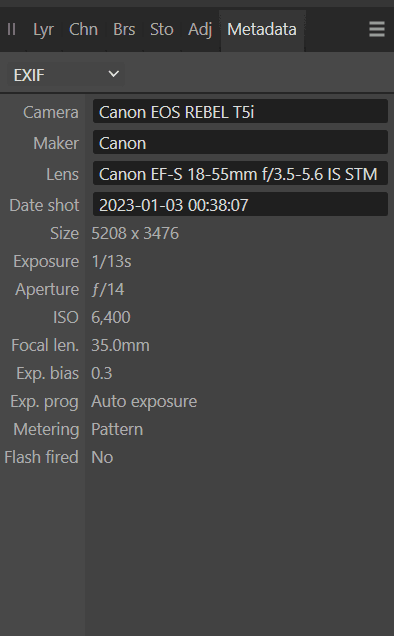
For a data asset like a photograph, metadata may include the camera, lens, size, exposure, and more.
Data catalogs for metadata management
Data catalogs have become the gold standard for metadata management. Unlike the more limited metadata stored in BI and other data-related tools, today’s metadata is far more expansive and supports more intelligent data analysis. A data catalog primarily focuses on data assets and products, providing an inventory of available dashboards, reports, databases, files, etc. It enriches these data assets with valuable metadata to guide and inform data users.
As organizations increasingly manage data on-premise and in the cloud, having a centralized source of metadata is essential for visibility into data assets, no matter where they are stored. This visibility supports day-to-day analysis and enhances critical data management functions such as governance, quality control, and migration. In a rapidly evolving data landscape, where new technologies and concepts continually emerge, a data catalog serves as a reliable, consistent tool for managing data efficiently and ensuring organizations can derive maximum value from their data.
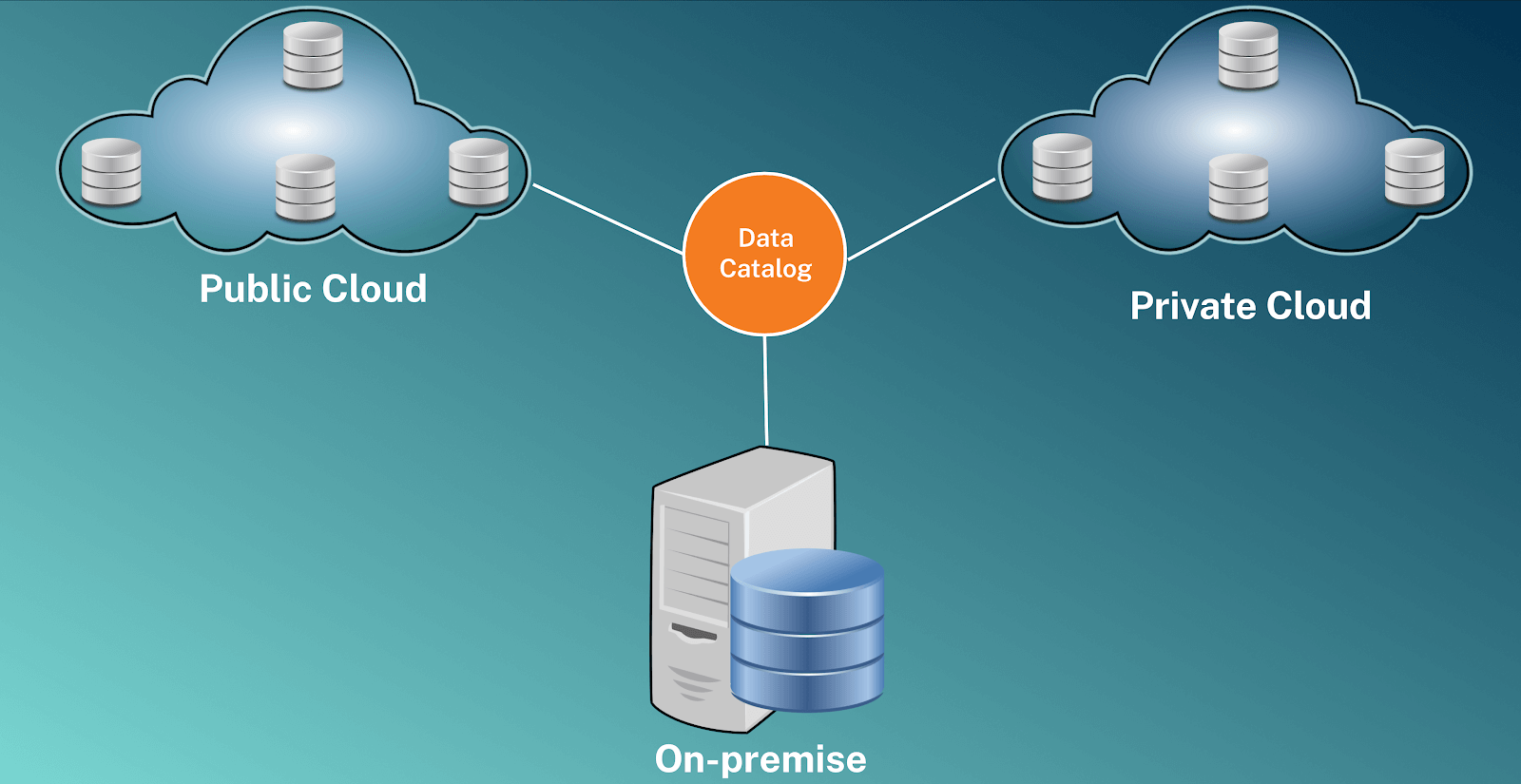
The data catalog unifies metadata from key assets from various sources.
Data assets are the dashboards, reports, files, and tables that data workers need to find and access. They may reside in a data lake, warehouse, business intelligence system, master data repository, or any other shared data resource, making discovering them in an organization challenging. A data catalog connects people to the contextualized, trusted data they need by centralizing the metadata.
Types of metadata
There are many types of metadata. Some standard metadata categories include:
Descriptive
Technical
Governance
Operational
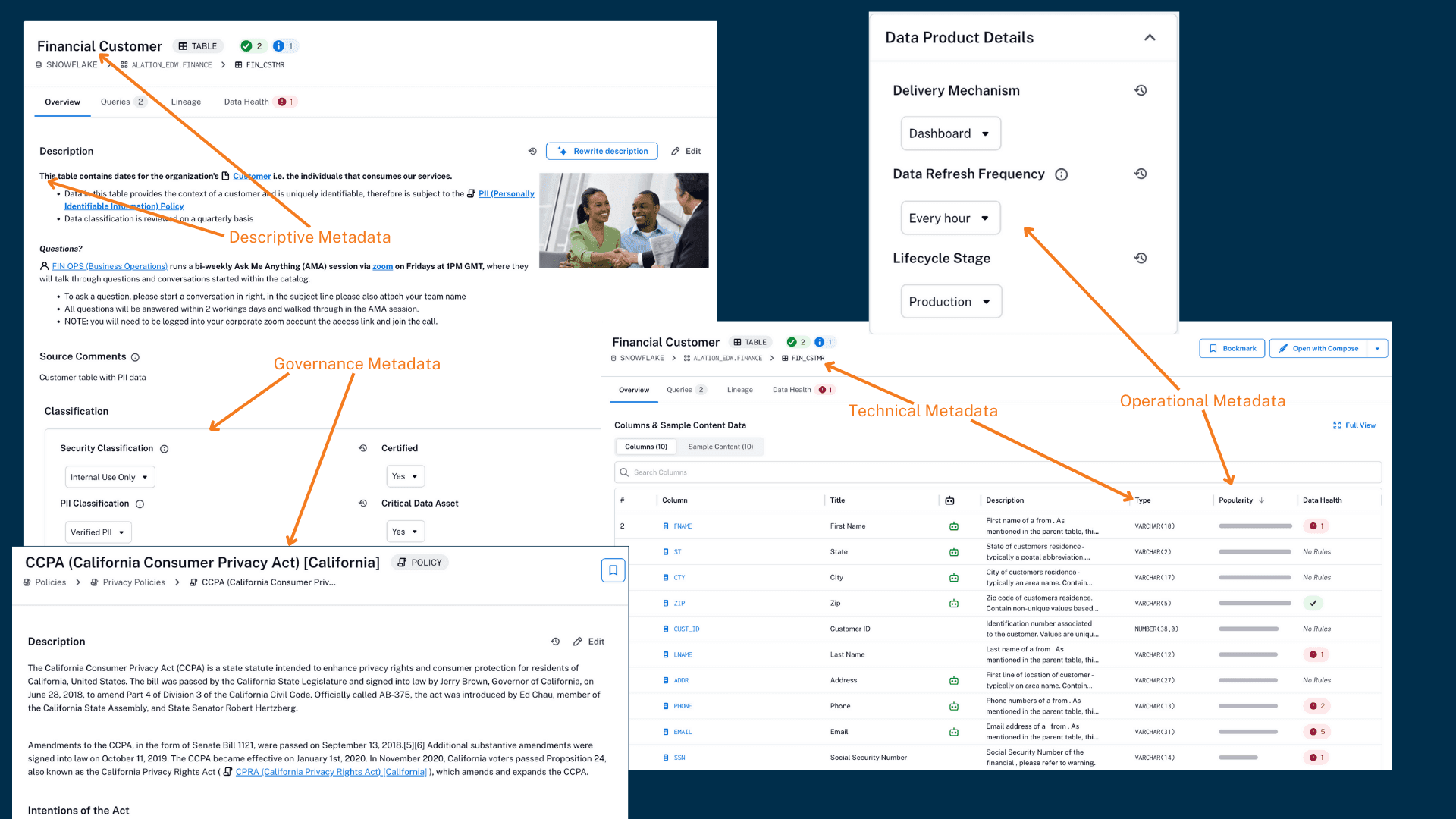
Examples of various types of metadata as they appear in the data catalog
Descriptive metadata includes business titles, definitions, tags, keywords, and other details that describe a data asset, as well as the names and roles of those who have previously worked with that asset.
Technical metadata details the physical structure of data assets such as databases, schemas, tables, and columns. It helps technical roles understand crucial implementation characteristics of data assets, such as data types and formats.
Governance metadata focuses on data governance policies, compliance, and data quality. Examples include data quality metrics, lineage, classification, and regulations (ex. GDPR, HIPPA).
Operational metadata focuses on the information about the processing and usage of the data asset, including the frequency of updates, performance metrics, and usage statistics like popularity, top users, etc.
Institutional knowledge is perhaps the most valuable (and hardest to capture) layer of metadata. It represents the reasoning, expertise, and decision-making logic that exists in your organization: why a particular data source is trusted over another, which definition of 'revenue' applies to which workflow, what a specific anomaly in the data typically signals. For human analysts, this knowledge lives in Slack messages, emails, and the heads of experienced employees. For AI agents, it needs to be documented, governed, and attached to the data assets it describes. Modern data catalogs provide the framework for capturing and maintaining institutional knowledge at scale, making it accessible to both people and the agents they build.
The collection of the metadata types described above must be automated to provide active metadata for people to use and processes to consume. A critical aspect of metadata management is tracking relationships and being able to display them. In addition, the catalog must allow custom metadata to be added.

What does a data catalog do?
A modern data catalog helps organizations centralize their data assets' metadata to provide a single pane of glass for discovering, organizing, managing, and governing those assets. It is the platform that helps both people and AI agents find, understand, and trust the data they need to make accurate, defensible decisions. In practice, this means the catalog serves two audiences simultaneously: the analyst who needs to know which dataset to query, and the agent that needs to know which definition to apply, which source to trust, and which policy governs its use.
The high volume, variety, veracity, and velocity of enterprise data today make manual cataloging very difficult and automation necessary. Automated discovery of data assets is essential for the initial catalog build and ongoing discovery of new assets. Using AI and machine learning (ML) for metadata collection, semantic inference, tagging, and classification is vital to getting maximum value from automation and minimizing manual effort.
At the heart of any data catalog is robust metadata management. Some of the other essential features and functions include:
Data discovery and search
Advanced search capabilities include searching by natural language (semantic), keywords, tags, and other business metadata such as domain. Natural language search capabilities are invaluable for non-technical users. The ranking of search results should consider relevance, frequency of use, and user ratings (endorsements).
Data lineage
Data lineage helps track the flow of data from its origin to its destination and includes metadata about the data assets and transformations. The visualization allows people to understand and trust the data. An example would be to map how a critical data element moves throughout an organization. Because of the extensive metadata, engineers can conduct impact analysis when planning a change and communicate to the owners of any impacted data assets.
Data quality
A data catalog supports quality profiling, documenting quality rules, and displaying data quality metrics so that data consumers grasp its quality and know whether they can trust it before use.
AI and data governance
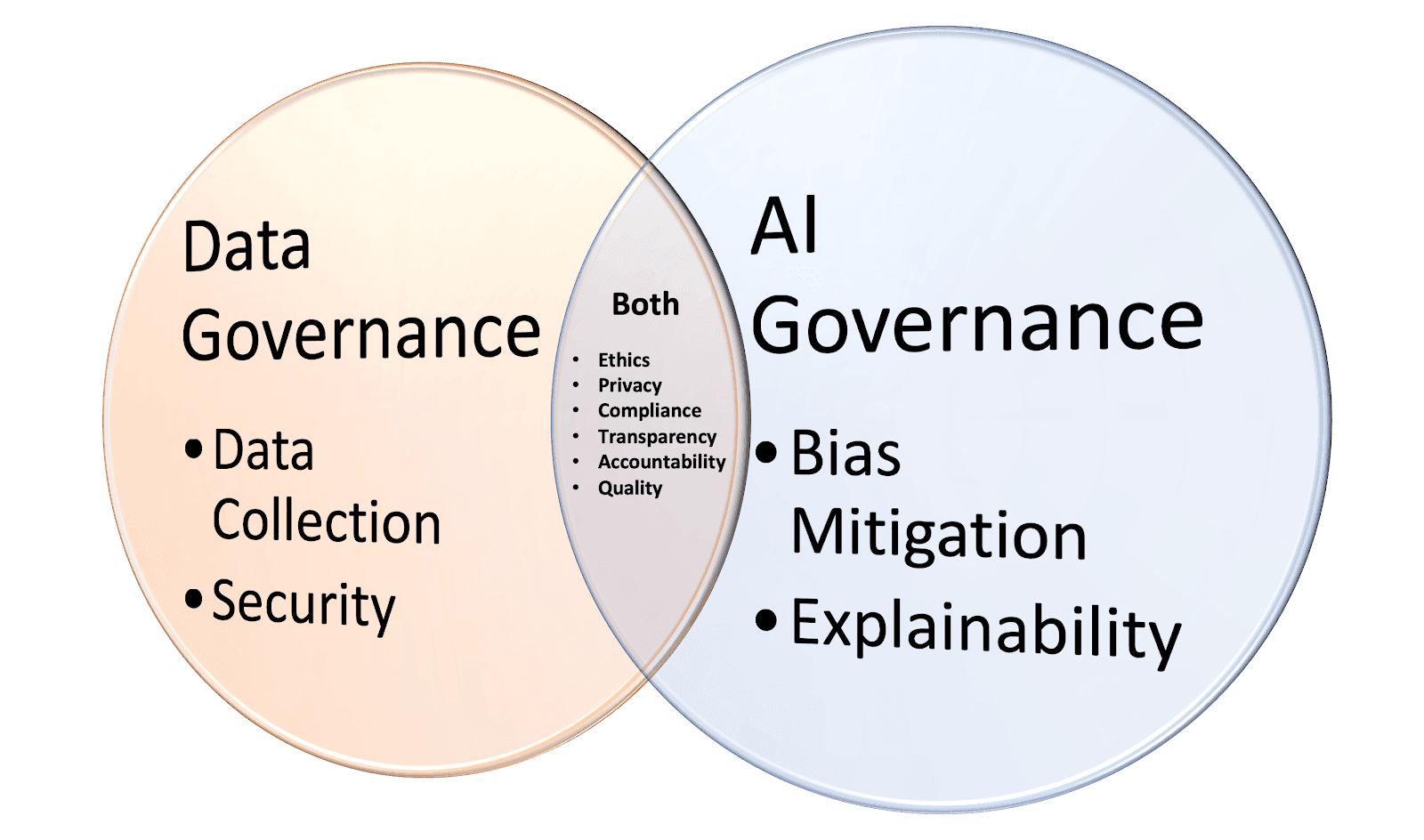
Data catalogs provide the means to classify data and assign the appropriate policies to ensure its compliant use. One benefit of having AI and data governance policies in a data catalog is the ability to conduct compliance audits. While there are similarities between AI and data governance, each discipline can also have a different focus.
For example, transparency in data governance often refers to data processes and what is happening as the data flows throughout the organization, including its quality. Data quality is critical for business processes such as reports and AI models.
For AI, transparency is about understanding how models are built, trained, and deployed.
It is important to note that AI requires more transparency and traceability in the training datasets and the explainability of the outputs from the model.
Self-service analytics
Data catalogs support self-service by providing one place where people can find, understand, trust, and use data without always relying on IT to access or understand data. The data catalog acts as an internal data marketplace where users can request and gain access to data products and data assets. Data access covers security, privacy, and compliance with sensitive data.
Supports collaboration
A data catalog provides an ideal platform for collaboration around data. It facilitates ongoing conversations, where questions and answers are tied directly to the data, enabling everyone to benefit from shared knowledge. Additionally, features like reviews and ratings of data assets allow users to gauge the quality and relevance of data, helping others understand its value and usefulness more effectively.
A data catalog should provide many other capabilities, including support for data curation, classification, usage tracking, and other features.

Data catalog as the foundation for AI agents
As organizations deploy AI agents to automate analysis, generate reports, answer business questions, and support decision-making, the data catalog has taken on a new role: providing the knowledge layer that enables agents to deliver accurate outputs.
An AI agent consuming enterprise data needs more than a schema. It needs to know which version of a metric is certified, which data source the system of record is, what policy governs access to a particular dataset, and whether there are known quality issues. Without this context (typically housed in a governed data catalog), agents produce outputs that are confident but wrong.
This is what practitioners mean by 'AI-ready data': data that is not just accessible, but enriched with the technical metadata, business context, and institutional knowledge an agent needs to reason accurately. The data catalog is where that enrichment happens and where it is maintained as data evolves.
Organizations building agentic AI workflows on top of a mature data catalog find they can achieve higher eval scores — the measure of whether an agent's outputs are accurate enough to act on — faster than those building agents without a governed knowledge foundation.
Benefits of a data catalog
Improved data efficiency
Data catalogs improve productivity by reducing people's time searching for data and granting them more time to analyze it. This reduces the likelihood of duplicating work and gives newcomers a view into the most trusted data assets and how they are most often leveraged. Moreover, a data catalog delivers helpful context via business metadata, data quality details, and collaboration features, leading to more accurate, timely insights.
Better data context
Data catalogs boost data understanding with detailed information about data assets. This includes where they come from, their quality, who uses them, and how they can or should be used. This information makes it easier for users to grasp the data's meaning, importance, and suitability. As a result, users can perform better decision-making and analysis. This same context is what AI agents consume to make accurate decisions, making a well-maintained catalog the prerequisite for any enterprise AI initiative.
Accelerated innovation
Data catalogs help accelerate the development of new products and services across all industries. Improved data context speeds up the discovery process and increases collaboration between teams, enabling quicker delivery.
Boost data governance and compliance
Data catalogs help centralize critical AI and data governance policies an organization uses. Having policies assigned to data assets helps users understand how to use the data compliantly. In addition, data lineage supports policy traceability and auditing, reducing risk.
Enable accurate, trustworthy AI
As AI agents take on more consequential tasks, such as drafting analysis, prioritizing decisions, and triggering actions, the accuracy of their outputs depends directly on the quality of the context they consume. A governed data catalog ensures agents work from certified, current, and correctly defined data. It also creates the audit trail needed to trace and explain agent decisions, which is essential for regulated industries and for maintaining organizational trust in AI-generated outputs. In this sense, the data catalog isn't just infrastructure for human analysts; it's the trust layer that makes enterprise AI safe to deploy at scale.
How data catalogs transform data use across industries
While data catalogs deliver value across any data-driven organization, their impact becomes even clearer when viewed through the lens of specific industries. Financial services, healthcare, and technology each face unique challenges—yet all rely on trusted, well-governed data to operate at scale. Modern catalogs provide the connective tissue that enables teams to find, understand, and confidently use data in high-stakes environments.
In financial services, speed and precision define competitive advantage. At Discover Financial Services, thousands of employees rely on Alation to sift through more than a million cataloged datasets and accelerate model development. By capturing active metadata and centralizing context, the catalog reduced data discovery from days to minutes—saving more than 200,000 hours and empowering engineers to build high-quality financial and behavioral models faster. The result is a stronger ability to balance innovation with the rigorous governance required in banking and credit risk.
In healthcare, trust is paramount. Children’s Hospital of Philadelphia (CHOP) uses its branded data catalog, nicknamed “Gene”, as a single front door for lineage, definitions, and governance signals that clinicians, researchers, and operations teams can rely on. Gene enables CHOP’s patient-centered custodianship approach—ensuring that teams working on AI initiatives can see how data is sourced, how often it refreshes, and which policies apply. This transparency is essential for producing AI-ready data that reflects real clinical complexity, not sanitized approximations.
In technology, scale and self-service are mission-critical. At NTT DOCOMO, where 7,000 employees access vast customer and digital service datasets, Alation transformed an “entangled” environment into a harmonized one. Analysts now find and reuse governed data quickly, driving a 10x boost in productivity and strengthening trust in the data fueling DOCOMO’s GenAI initiatives.
Across industries, the pattern is clear: a data catalog turns fragmented data into a shared, trusted resource—accelerating insight, reducing risk, and enabling innovation at scale.
Evolution of data catalogs
Data catalogs have evolved to meet the changing needs of modern data management. Before 2000, data catalogs were manual inventories of an organization’s data. The primary contents of name, location, and description were often stored in documents or spreadsheets. Some companies referred to them as their data dictionaries.
As organizations started using databases and data warehouses, enterprise data catalogs were created to provide descriptive metadata as a guide. The early solutions were often built in-house, storing the contents in a database so the contents could be searched. In addition, data management systems (DBMS) at that time had some capabilities but focused on technical metadata and only the contents of its database.
These catalogs grew to include data assets (datasets and reports), making it easier for users to find specific data elements in these systems.
In the early 21st century, the need for thorough metadata management led to catalogs that provided information about data lineage, quality, connections, and business context. These catalogs became crucial for data governance.
Between 2000 and 2015 the age of big data gave rise to self-service analytics. Data catalogs evolved to handle different data sources and became vital for finding and preparing data. Business users sought self-service capabilities to avoid relying on technical data teams during this period, strengthening the need for data catalogs.
Data catalog companies would emerge to offer platforms to manage data assets, business glossaries, and data governance capabilities.
The modern data catalog era began in 2015 and continues today. Modern catalogs use AI and ML to automate metadata creation, accelerate curation, and enhance data discovery. Today’s data leaders use modern data catalogs to manage the ever-changing data ecosystem, including integrating into more data management processes such as data quality and data governance.
As data technology changes and new concepts, such as the modern data stack, data fabric, and data mesh, the data catalog is the one constant part of the data ecosystem that organizations can rely on.
In short, data catalogs have evolved from simple lists to the knowledge foundation for enterprise AI. The next phase of that evolution is already underway: catalogs are becoming the systems of record not just for human analysts, but for the AI agents those analysts build and deploy. As agents proliferate across enterprise workflows, the catalog's role in governing what they know, what they can access, and whether their outputs can be trusted will become the defining capability of any mature data platform.
What changes when you implement a data catalog?
A data catalog brings key improvements to data management by making metadata more accessible and useful. Its true value, though, is often most noticeable in how it enhances analysis across business, engineering, and data science activities.
We work in an age where self-service analytics is a must. IT organizations can’t provide all the data needed by the ever-increasing numbers of people who need to analyze it. But today’s analysts and data scientists are often working blind, without visibility into the data assets that exist, the contents of those data assets, or their quality and usefulness.
They spend too much time finding and understanding data, often recreating existing data assets. They frequently work with inadequate data, resulting in incorrect analysis and model training. The illustration below shows how analysis processes change with a data catalog.
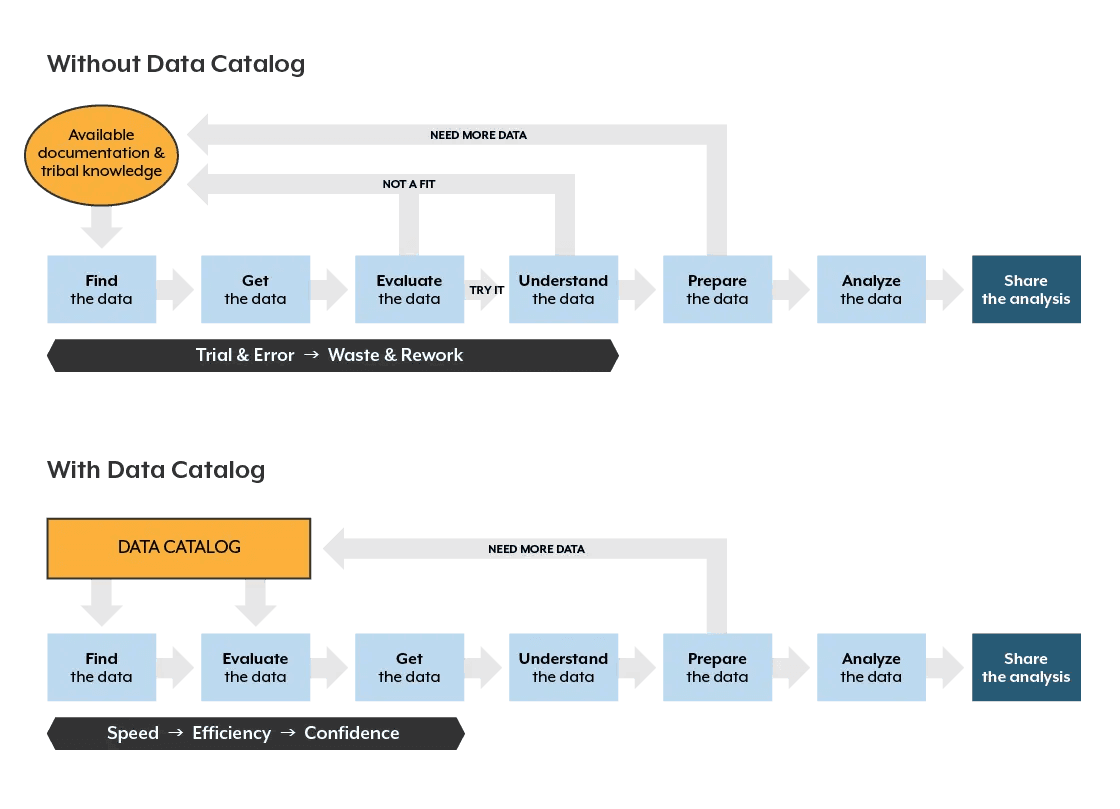
Without a catalog, analysts look for data by sorting through documentation, talking to colleagues, relying on tribal knowledge, or simply working with familiar data assets because they know about them. The process is fraught with trial and error, waste and rework, and repeated dataset searching, often leading to working with “close enough” data as time passes.
With a data catalog, the analyst can search and find data quickly, see all available datasets, evaluate and make informed choices for which data to use, and perform data preparation and analysis efficiently and confidently. It is common to experience a shift from 80% of time spent finding data and only 20% on analysis to 20% finding and preparing data with 80% for analysis. The quality of analysis is substantially improved, and the capacity of organizational analysis increases without adding more people.
User adoption strategies for a data catalog
To make the most of a data catalog and ensure it becomes an integral part of your data-driven journey, users can adopt a data catalog effectively through these strategies:
User training and onboarding
Launch thorough training and onboarding programs to teach users how to use the data catalog effectively. Offer workshops, tutorials, videos, and documentation to help users learn the way they like to. Keep the onboarding information content or links to the content in the catalog for easy access.
Encourage collaboration
Foster teamwork in the organization. Urge users to comment on data assets, share ideas, and work together on data projects using the catalog. Recognize and reward contributors and highlight team achievements. Consider hosting "curation power-hour" events where teams can share their knowledge, making the platform better for everyone. This builds a sense of community and shared data knowledge.
Highlight real-world use cases
Highlight real-life examples of how the data catalog has made a big difference in finding, preparing, and analyzing data. Share success stories and how the catalog helps various teams and projects. This shows how useful it is and encourages more people to use it.
These strategies help users welcome the data catalog as a valuable tool for their data tasks and encourage its effective use across the organization.
Conclusion
A data catalog is no longer optional infrastructure. It is the knowledge layer that determines whether your organization's data — and the AI built on top of it — can be trusted.
By centralizing technical metadata, business context, and institutional knowledge in one governed system, a modern data catalog gives both analysts and AI agents what they need to produce accurate, defensible outputs. It reduces the time teams spend hunting for data, raises the quality of every analysis, and provides the audit trail that regulators, stakeholders, and enterprise risk teams require.
With Alation, your organization gets a catalog built for the demands of both today's analysts and tomorrow's AI agents: connected to every major data platform, enriched with 14 years of governance depth, and designed to compound in value as your data and AI initiatives grow.
See how Alation customers are using a governed data catalog to accelerate AI initiatives alongside traditional analytics.

- The significance of data catalogs
- What is metadata?
- Data catalogs for metadata management
- Types of metadata
- What does a data catalog do?
- Data catalog as the foundation for AI agents
- Benefits of a data catalog
- Evolution of data catalogs
- What changes when you implement a data catalog?
- User adoption strategies for a data catalog
- Conclusion
Contents
FAQs
What is a data catalog?
A data catalog is a collection of metadata, combined with data management and search tools, that helps analysts and other data users to find the data that they need, serves as an inventory of available data, and provides information to evaluate fitness of data for intended uses.
How do organizations measure ROI for data catalogs?
Organizations measure ROI of data catalogs by assessing factors like time saved in data discovery, reduction in errors, improved decision-making, and enhanced collaboration. They may also consider cost savings from avoiding duplicate data efforts and increased efficiency in data analysis processes.
What are common challenges in adopting data catalogs?
Common challenges include ensuring data quality, gaining user adoption, integrating with existing systems, and addressing privacy and security concerns. Overcoming resistance to change and ensuring proper training and support for users are also critical for successful implementation.
In which industries do data catalogs have the most impact?
While data catalogs benefit various sectors, industries with complex data ecosystems like finance, healthcare, and retail often see substantial impacts. Additionally, sectors undergoing digital transformation or heavily reliant on data-driven decision-making find data catalogs particularly valuable.
Tagged with
Loading...