Turnkey Cloud DataOps: Solution from Alation and Accenture

By John Wills
Published on March 22, 2022

Data people face a challenge. They must put high-quality data into the hands of users as efficiently as possible. DataOps has emerged as an exciting solution. As the latest iteration in this pursuit of high-quality data sharing, DataOps combines a range of disciplines. It synthesizes all we’ve learned about agile, data quality, and ETL/ELT. And it injects mature process control techniques from the world of traditional engineering.
As pressures to modernize mount, the promise of DataOps has attracted attention. People want to know how to implement DataOps successfully. In fact, DataOps (and its underlying foundation, Data Fabric), has ranked as a top area of inquiry and interest with analysts over the past twelve months.
But alas! As with any next big thing, there is no free lunch. DataOps requires an array of technology to automate the design, development, deployment, and management of data delivery, with governance sprinkled on for good measure. This means that preparing for DataOps takes work. And while most organizations have a vast array of heterogeneous tools to meet a range of needs, complex environments, from mixed, to on-prem to cloud and hybrid architectures, only complicate the challenge.
In fact, DataOps places an outsized burden on data management teams. To prepare for DataOps, they must patch together and integrate many technologies, which were never engineered to interoperate… at least not in the way that delivers on the end-to-end promise and automation of DataOps. This is a time-consuming and costly project to undertake.
So, how can you quickly take advantage of the DataOps opportunity while avoiding the risk and costs of DIY? Accenture and Alation have collaborated to provide the answer. Together, they provide a pre-engineered DataOps platform. This platform can be implemented in a cost-effective serverless cloud environment and put to work right away.
Accenture’s DataOps Leap Ahead
DataOps requires a very specific foundation. Accenture calls it the Intelligent Data Foundation (IDF), and it’s used by dozens of enterprises with very complex data landscapes and analytic requirements.
Simply put, IDF standardizes data engineering processes. Let’s dig into that a bit to understand how IDF sets you up for DataOps success. Take a look at figure 1 below. It shows all the bare minimum capabilities needed to have a complete DataOps solution.
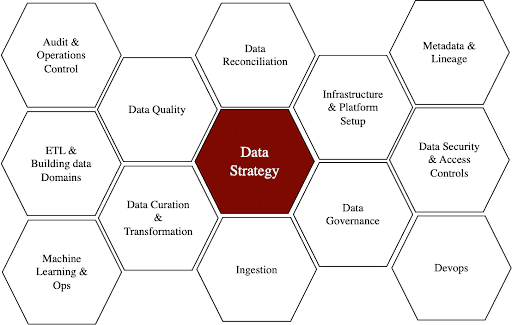
Setting this up is expensive and time-consuming. Accenture has a pre-built solution. They created each capability as modules, which can either be used independently or together to build automated data pipelines. This accelerates the output of accuracy of analytics projects and enables engineering teams to scale up successful analytics more quickly.
IDF works natively on cloud platforms like AWS. It leverages the power of serverless (and managed) services to automate and build data and analytics pipelines; IDF uses a point-and-click, zero-code approach with pipeline blueprints (patterns), such as the one below.
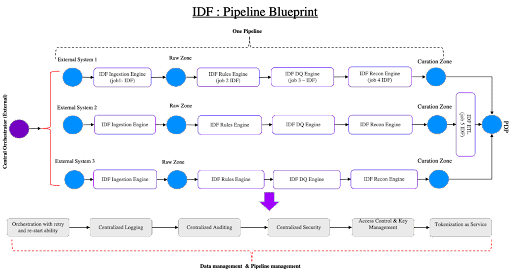
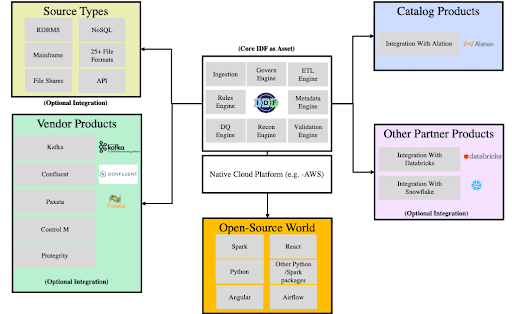
In addition to being cloud-native, IDF has also pre-integrated a wide array of partner tools at the API level, so most organizations will find that there are no sunk-tool or switching costs. They can simply continue to use the same tools but with a greater level of capability and productivity.
Alation’s DataOps Role
DataOps is critically dependent on robust governance and cataloging capabilities. This is exactly the role that Alation, the industry leader in both, plays for IDF.
Alation’s governance capabilities include automated classification, profiling, data quality, lineage, stewardship, and deep policy integration with leading cloud-native databases like Snowflake. These features give data engineers using IDF the ability to explore data, understand its quality, trace lineage for root cause analysis, and enforce policies like encryption & masking. This significantly improves analyst efficiency, increases the accuracy of analytics, and drives up user confidence in the data supplied for decision-making.
More specifically, IDF has been integrated with Alation at an API level; this means that all generated pipeline code, metadata attributes, configuration files, and lineage are automatically synced (representing a huge time savings).
As an example, consider when IDF creates tables across staging and curated zones. The table details are extracted from the IDF pipeline information, which then syncs details like column, table, business, and technical metadata. This produces end-to-end lineage so business and technology users alike can understand the state of a data lake and/or lake house.
Alation’s data catalog and user-friendly interface give DataOps teams a way to publish data sets so that business analysts can easily search for data, understand its usage with descriptive metadata, and even explore the data by reviewing its profile or querying it. In essence, Alation is acting as a foundational data fabric that Gartner describes as being required for DataOps.
How the IDF Supports a Smarter Data Pipeline
Many IDF customers have sought solutions to common-yet-complex data problems. They need guidance on how to best manage a searchable and central repository of data, pipelines, rules, checks, validations, metadata, and data lineage.
IDF provides a focused, business-driven solution. Transparency is key. By making the entire process trackable, from source to target, the IDF empowers users to gain new insights. They can better understand data transformations, checks, and normalization. They can better grasp the purpose and use for specific data (and improve the pipeline!)
IDF is compatible with Alation in two key ways. First, as a central data engineering solution, Alation users can build dedicated connectors. Such connectors may enhance the management, governance, and cataloging of all data. Second, Alation is a module-based platform that tracks all auditable data characteristics. This means users can custom-design a central, reliable view of data lineage. They can then enrich their data pipelines with that captured context. And they can automate these tasks to run on their own – and even improve with time.
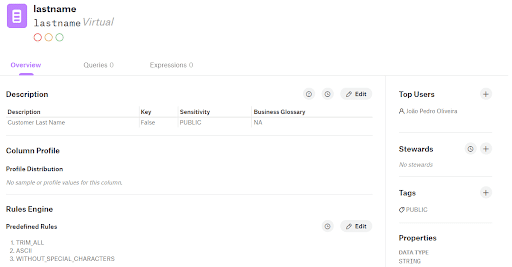
Displaying the data lineage in Alation’s Data Catalog
In the future, Accenture plans to take this integration further and promote initiatives to achieve an even more integrated and symbiotic solution, together with our customers. In this way, the IDF will become more complete in terms of data governance and cataloging, and, on the other hand, customers will be able to better take advantage of this core solution, accelerating, transforming, and digitalizing their businesses.
Wrapping it up
Organizations face feast and famine both when it comes to data. Data management teams are overwhelmed by data while their business consumers starve. DataOps has emerged as an enticing solution for both sides of the table.
And as with any new approach, organizations must choose to act or wait. Data management teams face a choice: how long do we sit on the fence — and when do we dive in, and test the waters?
With the IDF, Accenture has granted organizations an easier choice. IDF represents a low-risk way to wade in earlier and start leveraging the benefits of DataOps quickly. Otherwise, already-overwhelmed data teams face a mountain of work to prepare. With Accenture, teams can avoid the costly investment of integrating a broad array of cloud services. Instead, they can hit the ground running with DataOps from day one.
Learn more about the Alation Partner Network
- Accenture’s DataOps Leap Ahead
- Alation’s DataOps Role
- How the IDF Supports a Smarter Data Pipeline
- Wrapping it up
Contents
Tagged with
Loading...