Data Catalogs vs Metadata Management: Key Differences?
Published on January 30, 2025

We define a data catalog as “a repository of data assets with information about that data.” It is, literally, a catalog that users, analysts, data scientists, and others can browse to find, understand, evaluate fit for purpose, and access trusted data.
But how does a data catalog actually catalog data? That’s where metadata comes in: it’s data about data. Metadata is information that describes other data. It’s a critical component of modern data management, and it’s how workers quickly gain the context they need to leverage data effectively.
From modest beginnings as a means to manage data inventory and expose datasets to analysts, the data catalog has grown in functionality, popularity, and importance to today’s data-driven organizations of all sizes.
Modern data catalogs continue to meet the needs of analysts and have expanded their scope to enable easy data access to non-technical data consumers, enforce data governance policies and guardrails, enable data stewardship, data curation, and data governance, and much more. All of these activities are dependent on metadata, which is how data catalogs deliver huge benefits.
In this article, we’ll explain how data catalogs work, the crucial importance of metadata and effective metadata management, and how you can build a robust data catalog and accompanying metadata management practices in your organization.
What is a data catalog? Your central hub for data discovery
A data catalog provides information about data. For enterprises and even midsized organizations with huge volumes of data, data catalogs provide a single window through which workers can find and understand available data. As data’s value increases and new artificial intelligence (AI) and machine learning (ML) innovations rely on access to more information, data catalogs are the key to using data effectively.
Think of a data catalog as similar to a traditional retail catalog. Instead of information about products, it contains metadata—and data management and search tools—to serve as an inventory of available data and provide information evaluating its fitness.
How a data catalog uses metadata
Imagine a physical home furniture catalog you receive in the mail. You grab it from the mailbox, plop down on your sofa, and flip through the pages until you spot sofa photos. You use that visual information to slow your flipping until you see the sectional sofas.
When a particular sofa catches your eye, you read the detailed information in the description, browse the fabric options, consider the dimensions, evaluate the price, and decide if it’s the right sofa for you. All of those product options, visual or written, are metadata about that particular sofa.
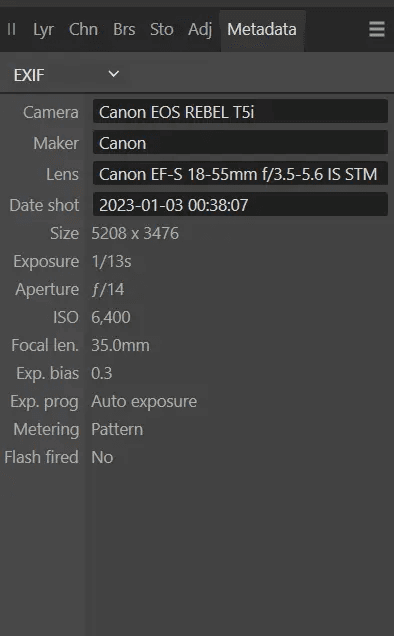
A more specific example of metadata is the Exchangeable Image File Format (EXIF) standard for image and sound data from digital cameras. It captures information about the camera model, lens type, date of photo, image size, and other image details. Modern cameras, such as those in mobile phones, also add GPS-sourced location and other metadata.
When a photographer organizes and searches for photos, the metadata is invaluable for locating images taken at a longer exposure on February 14 at that fancy restaurant downtown or finding images from a trip to a particular nature park.
That’s all metadata, and the app you use to search through the metadata is analogous to a data catalog.
Metadata management is the key to unlocking data’s potential
With an understanding of data catalogs and how they use metadata, it’s easy to understand why metadata must be managed effectively to get the most value from a data catalog.
Metadata management is not just a concept; it is an important function that encompasses capturing, inventorying, and categorizing metadata so organizations can empower users to search for, discover, and govern data. Metadata management also helps data consumers to evaluate data and its relevance and applicability to their needs.
A robust metadata management program connects data consumers with data owners, data curators, and data stewards to answer questions and provide guidance. It also spans data governance to apply data access and usage policies, data quality to ensure data is fit for specific needs, data lineage so users can track where data originated and how it has been processed, and more.
Creating a metadata management program is similar to embarking on any organizational initiative. An example process on how to get started with metadata management includes:
Assigning a metadata team
Defining a metadata strategy
Adopting metadata standards and creating a framework
Deploying a metadata management tool
Scaling metadata management
To learn a methodology for understanding the role a metadata management program plays, read the “Metadata Management Methodology” white paper.
Active metadata vs. passive metadata: What’s the difference and why it matters
Let’s explain the differences between active and passive metadata management:
Passive metadata management is manual metadata management, entailing manual data collection, controls, and monitoring. Like most manual processes, it’s error-prone and time-consuming, two things that burden organizations and slow data-hungry innovations like AI and ML.
Active metadata management modernizes the practice through automation, integrations, and continuous monitoring. By connecting different data sources, tools, and applications, active metadata management provides automated alerts, insightful dashboards, streamlined collaboration, and proactive data governance.
With active metadata management, a data catalog captures and stores metadata while adding solutions for management and collaboration (saving time and speeding up productivity). Active metadata management also captures metadata in real-time to automatically update data catalogs and intelligently parse metadata context using AI, ML, and automation.
Data catalog vs. metadata management: Understanding key differences
A good way to separate a data catalog from metadata management is to understand that a data catalog is a tool or an application while metadata management is a process or function.
Put another way, effective metadata management processes use a data catalog application to store metadata for data search and discovery, governance, and collaboration. A data catalog makes metadata management possible.
Evolving metadata management: Modern strategies for a data-driven era
It seems that everyone wants data management, but most want to avoid metadata management. The distaste for metadata management is an artifact of past metadata approaches with disparate metadata collected by a variety of tools using proprietary formats and without integration.
Metadata management is essential to data management, especially in the age of AI. Just as you need data about finances for effective financial management, you need data about data (metadata) for effective data management. You can’t manage data without metadata.
As data management becomes more complex with the plethora of data-related concepts, approaches, and architects like data lakes, data warehouses, data lakehouses, data mesh, self-service analytics, and data science. These modern approaches have changed the role and importance of metadata because metadata that is current, accurate, and readily accessible is an imperative.
A successfully data-driven organization must actively manage metadata, and a data catalog is the right tool for the job. The data catalog has become the new gold standard for metadata and a cornerstone of data curation.
Self-service analytics: Empowering users with metadata-driven strategies
The real value of metadata is found in the answers it can provide. People who depend on data have questions about trustworthiness, latency, lineage, sensitivity, preparation, and much more. Sometimes, they want to find others who know or have worked with the data to get a human perspective. They also need to know about access, privacy, security constraints, costs, etc.
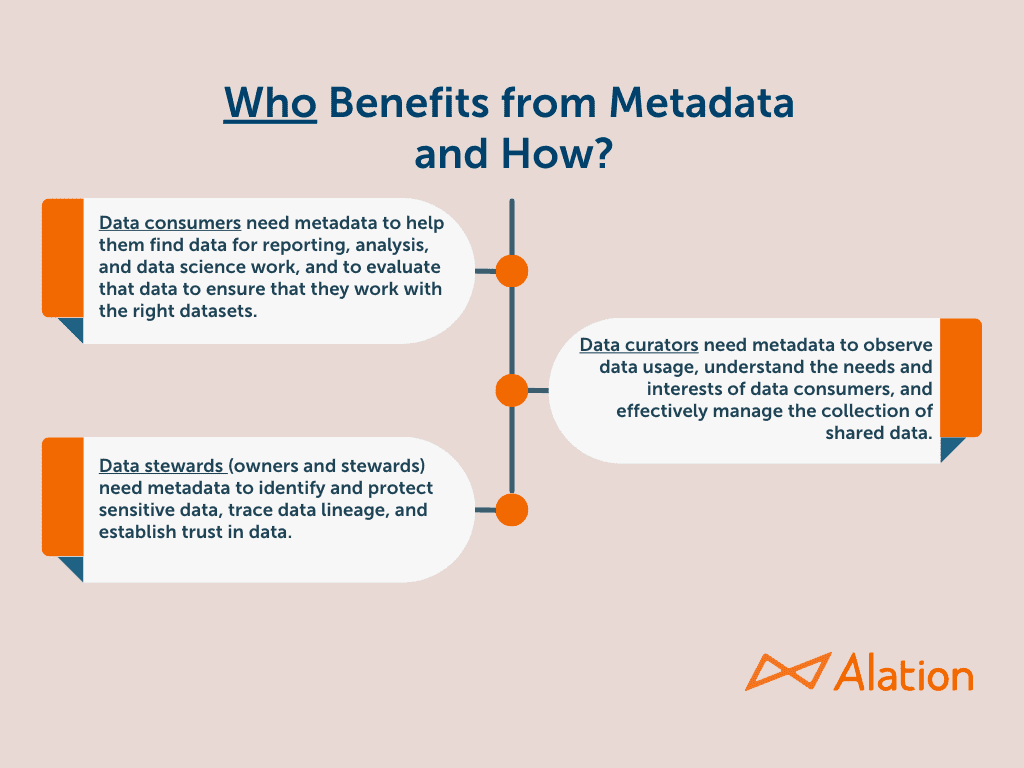
Robust metadata ranging from dataset names and properties to usage, access, licensing, and subject experts is the key to answering the many questions that data users and data managers will ask. In today’s fast-paced, self-service world, metadata is essential for three distinct groups of data management stakeholders:
Data consumers who form the bedrock of a data culture need metadata to help them find data for reporting, analysis, and data science work, and to evaluate that data to ensure that they work with the right datasets.
Data curators need metadata to observe data usage, understand the needs and interests of data consumers, and effectively manage the collection of shared data.
Data governors (owners and stewards) need metadata to identify and protect sensitive data, trace data lineage, and establish trust in data.
The data catalog and metadata: A dynamic duo
Metadata is the language of a data catalog. Every catalog collects data about the data itself and the processes, people, and platforms related to data.
Metadata tools of the past collected business, process, and technical metadata, and data catalogs continue that practice. But today’s modern data catalogs do much more. They collect metadata about datasets, metadata about processing, metadata for searching, and metadata for and about the people (and how they use data assets).
Data catalogs change the game and elevate best practices for metadata management with:
Crowdsourced metadata. Much of catalog metadata is collected automatically by applying algorithms and machine learning. However, sometimes the most valuable metadata is the knowledge and experiences of individuals and groups. Collecting that knowledge as user ratings, reviews, tips, and techniques enriches the metadata collection and converts organizational knowledge into a shared and enduring data management resource.
Metadata about people. Data management and analysis are ultimately human activities. Knowing which people have data roles and relationships and the nature of those roles is valuable. Data catalogs capture metadata to identify data users, data creators, data stewards, and data subject matter experts.
Automated metadata discovery. Organizations with massive data holdings—literally tens of thousands of databases—simply don’t know about all of the data they have. It is impossible to catalog a petabyte data estate without automated discovery. New technologies like AI help to automate and accelerate metadata discovery and management.
The business case for a data catalog
The direct impact of a data catalog on business performance includes faster time to insights, improved decision-making, reduced data duplication, and more.
Here are several business challenges that enhance the business case for a data catalog:
Accelerating cloud data migrations and value realization. A data catalog empowers faster migration by spotlighting the best data, so only the data that matters is migrated.
Ensuring confidence in business analysis. By using a data catalog to ensure data governance happens before analysis, it speeds analytics with well-governed data that produces more reliable, trusted results.
Securing sensitive data. Data catalogs mitigate risk by discovering and protecting sensitive data. Indeed, the technical challenge here is discovering sensitive data, governing it, and protecting it.
Harnessing undiscovered business value. Achieving value from available data is straightforward, but how much value are you missing in data users don’t know about? Data catalogs, especially data catalogs with active metadata management, capture the data intelligence to discover and unleash every bit of available data.
Easing regulatory compliance. Data catalogs increase compliant data usage as regulations evolve. A modern data catalog brings compliance and data governance into the entire process, from data discovery to usage.
A real-world data catalog case study: Sallie Mae
Sallie Mae is the market leader for private student lending with over $22 billion in loans outstanding. At that size, the company has over 500 data consumers across the company, each working to find the right information at the right time.
Sallie Mae set out to bolster its data culture by creating a clear path to share data, improving data governance, and strengthening data stewardship and data literacy. It chose Alation Data Catalog to eventually deliver its data users streamlined, centralized, and governed access to 250 terabytes of data across 350,000 data fields.
“After Alation, people have been brought together in a number of different forums as we implement data governance,” says Elizabeth Friend, Sr. Director, Data Governance, Sallie Mae. “Alation is the front door [and] everyone's gathering at the same house.”
The future of data catalogs: Trends and innovations
Automated metadata discovery is a part of data cataloging that is growing in importance. Emerging technologies like AI and ML are also seen as crucial as organizations lean on data catalogs to automate discovery, metadata management, and governance.
Three data catalog trends to watch include:
Modern data catalogs will provide workers with a single-pane-of-glass view that enables both technical and business users to access, manage, and govern data effectively at scale. As organizations and their data volumes grow, most will expect data consumers to have a single solution for accessing all data.
AI requires access to enormous amounts of trusted, AI-ready data as organizations look to train AI models for unique and proprietary use cases. These non-human resources have the same challenges as humans in finding, understanding, and governing data, which data catalogs are primed to solve.
More data will migrate to the cloud, increasing the value of data catalogs that can govern and connect data across cloud-based resources. Integrations with tools like AWS QuickSight, Azure Cosmos DB, Microsoft Power BI, OneStream, Qualytics, Starburst Galaxy, and others, and that use an open connector framework will enable organizations to gain insights across the modern data stack while streamlining AI applications.
We don’t know what tomorrow will bring, but it’s pretty clear that more data is a good bet. Data catalogs are crucial for enabling data-driven organizations to gain the most value from their available data, today and into the future.
To get started with your own data catalog and metadata management program, read this how-to guide for data catalog implementation.
- What is a data catalog? Your central hub for data discovery
- How a data catalog uses metadata
- Metadata management is the key to unlocking data’s potential
- Data catalog vs. metadata management: Understanding key differences
- Evolving metadata management: Modern strategies for a data-driven era
- Self-service analytics: Empowering users with metadata-driven strategies
- The data catalog and metadata: A dynamic duo
- The business case for a data catalog
- The future of data catalogs: Trends and innovations
Contents
FAQs
What is a data catalog?
A Data Catalog is a collection of metadata, combined with data management and search tools, that helps analysts and other data users to find the data that they need, serves as an inventory of available data, and provides information to evaluate fitness data for intended uses.
How does metadata discovery in catalogs work, and what are its limits?
Automated metadata discovery in catalogs involves algorithms to identify and extract metadata from various data sources. However, it may struggle with unstructured data or complex relationships.
What are the common challenges in metadata management for self-service analytics?
Challenges include ensuring accuracy and consistency across diverse data sources, managing evolving data schemas, and addressing privacy concerns without hindering access to data.
How does crowdsourced metadata benefit data catalogs?
Crowdsourced metadata enriches catalogs with user-generated insights, enhancing data searchability and quality. It fosters collaboration and taps into collective knowledge to improve data management.
Tagged with
Loading...