
According to McKinsey, by 2030, companies will integrate data into every system, process, and decision, achieving a state of “data ubiquity.” This shift will force organizations to re-evaluate how they move and manage data at scale. Strong integration ensures these systems work together as complexity grows, providing reliable data that supports faster, better business decisions.
As data volumes grow, diverse architectures—whether cloud-native, hybrid, or legacy—can strain ingestion pipelines and slow data delivery. Problems with data ingestion, such as fragmented pipelines and siloed tools, impact downstream systems like analytics and AI.
A well-defined ingestion strategy prevents these issues. It does so by enabling reliable access to data, strengthening system resilience, and supporting real-time insights. Choosing the right data ingestion tool makes all the difference here. It should align with your architecture, support everyday workflows, and provide the foundation for confident, data-driven decision-making.
The important role of data ingestion tools
Every system that depends on data begins with one question: How will that data enter your environment? Ingestion tools answer that question. They move data from fragmented sources into unified data platforms, enabling the work of analysis, compliance, governance, and AI.
But this task isn’t just about transfer. Ingestion decisions also affect data quality, freshness, and availability downstream. So when data ingestion pipelines break or deliver incomplete data, the consequences ripple through every business function. In one notable example, Unity Software attributed a $110 million revenue loss and a $4.2 billion drop in market value to ingesting bad data from a single customer. Bad data misled Unity’s ad-targeting models, producing inaccurate audience predictions that wasted advertiser budgets and eroded investor confidence.
It’s a clear reminder that ingestion quality directly shapes business performance and that reliable data flows are just as critical as the analytics and AI they power. A strong ingestion layer helps you do the following:
Automate complex intake across diverse formats and endpoints.
Maintain consistency and freshness as upstream systems shift.
Support both batch and streaming use cases without custom infrastructure.
Adapt to scale without constant rework or technical debt.
Still, ingestion alone doesn’t make data usable. Your teams must track ingested data, trace its origins, and confirm it meets defined business standards. That starts with data cleansing to correct errors at the source, followed by data curation to maintain accuracy and relevance over time. Along with data governance, these practices help teams trust, enforce, and scale the value of ingested data.
5 leading data ingestion tools: Which one is right for you?
Choosing the right tool depends on your governance needs, data architecture, and team workflows. The best platforms balance technical depth with usability for both IT and business users.
Here's how leading data ingestion tools compare across core capabilities:
Apache Kafka
Apache Kafka powers high-throughput, real-time data pipelines by distributing data streams across multiple systems. It then ingests and transports event data continuously, which allows systems to react and process information as it arrives.
Key features and benefits:
Real-time streaming: The platform processes millions of events per second with low latency by distributing data across brokers, making it well-suited for real-time pipelines.
Durable storage: It persists data to disk, replicates it across brokers, and lets teams set retention periods for a dependable storage layer.
Horizontal scalability: You can add brokers to increase throughput and storage without interrupting operations.
Cons:
Kafka requires significant infrastructure setup and maintenance.
It has a steep learning curve if you don’t already have experienced engineers on your team.
Apache Kafka fits best for organizations with strong technical teams who need maximum performance and flexibility for high-volume stream processing scenarios.
AWS Glue
AWS Glue is a serverless, cloud-based data integration service that helps you discover, prepare, and move data across the AWS ecosystem. It streamlines ingestion by combining ETL automation with deep integration across AWS-native tools.
Key features and benefits:
Automated ETL jobs: The platform generates and customizes Python or Scala code for large-scale data cleaning and preparation, removing the need to code from scratch.
Automatic data discovery: Crawlers scan data sources, infer schemas, and store metadata in a centralized catalog so teams can easily find and use data downstream.
Serverless scaling: Your workloads run on elastic resources that scale automatically, with no infrastructure to manage and costs based only on usage.
Cons:
Glue may start jobs more slowly than always-on services.
You may run into limitations if you need to integrate heavily with non-AWS systems.
AWS Glue works best for organizations that have already invested in the AWS ecosystem and that prioritize managed services over operational flexibility.
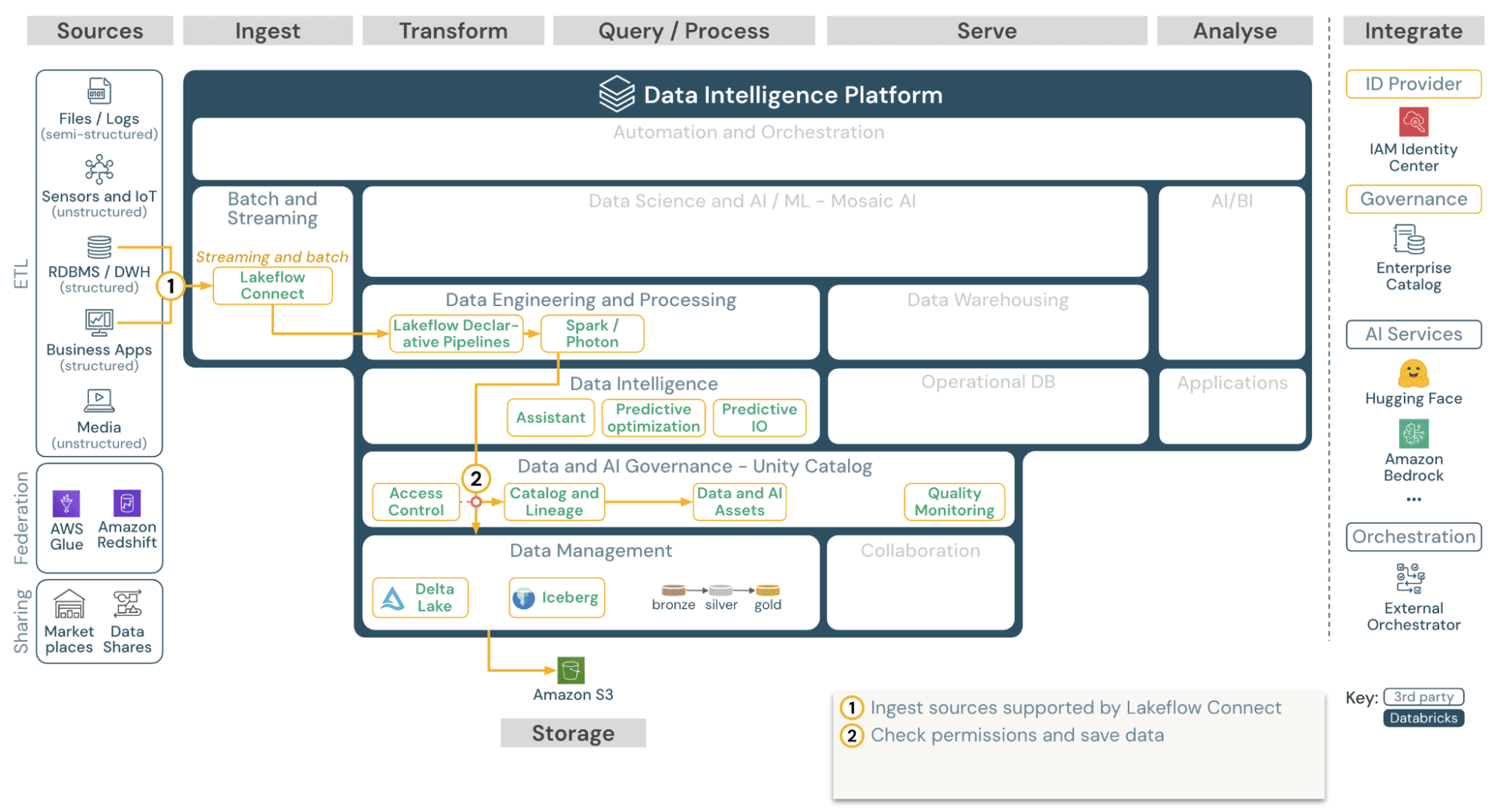
Databricks LakeFlow
LakeFlow is Databricks’ unified data ingestion and ETL tool that supports real-time streaming and batch pipelines across Delta Lake. It manages ingestion directly within the Databricks stack and unifies transfer, data transformation, and lineage in one environment.
Key features and benefits:
Unified ingestion: The platform handles both batch and streaming data in one place, removing the need for separate tools and simplifying pipeline design.
Simplified pipeline management: Teams can build, test, and monitor pipelines visually or with code, while the system manages dependencies and recovery.
Optimized performance with DLT: Delta Live Tables enforce data quality, track lineage, and handle schema changes automatically to keep pipelines reliable.
Cons:
LakeFlow is tightly coupled with the Databricks platform and lacks flexibility for external systems.
You’ll need some familiarity with Spark and Delta Lake concepts to use it effectively.
LakeFlow suits organizations already using Databricks. It serves teams that prioritize operational simplicity and are willing to invest in premium data pipeline management.
Apache NiFi
Apache NiFi is a dataflow automation tool for designing and managing complex pipelines with a drag-and-drop interface. It supports real-time and batch ingestion and works well in hybrid and on-premise environments.
Key features and benefits:
Visual dataflow design: You can build and manage pipelines through a drag-and-drop interface, enabling complex workflows without writing code.
Versatile data handling: The platform processes structured, semi-structured, and unstructured data using a large set of built-in processors for transformation, routing, and filtering.
Precise flow control: Teams can route, prioritize, and apply back-pressure to manage data movement and prevent bottlenecks.
Cons:
NiFi can become difficult to scale and manage in very large or complex deployments.
Performance tuning often requires deep platform knowledge.
As an open-source tool, NiFi appeals to teams that are looking for customizable, community-supported solutions.
Fivetran
Fivetran is a fully managed data pipeline platform that syncs data from popular sources into cloud data warehouses with minimal setup. It’s ideal if you want fast deployment and low-maintenance operations.
Key features and benefits:
Automated schema handling: Fivetran detects schema changes and updates destinations automatically, preventing failures and reducing manual work.
Extensive connector library: The platform uses prebuilt connectors for SaaS apps, databases, and files to avoid building custom integrations.
Efficient data syncing: It syncs only new or changed records to reduce latency, resource use, and costs.
Cons:
The tool provides limited flexibility for custom transformations.
Pricing may become expensive as your row count and sync frequency grow.
Fivetran fits organizations that prioritize simplicity and speed over customization, especially those that use common SaaS applications with moderate data volumes.
➜ Learn more about how to choose between ETL vs ELT approaches.
How to effectively compare data ingestion solutions
Many ingestion tools share core functions, but meaningful differences appear in daily use. These five factors reveal whether a tool can keep up with your data needs as they grow:
1. Assess user interface
Your team will spend hours on this platform, so the interface matters. A well-designed interface simplifies monitoring, shortens onboarding, and reduces human error. It also prevents schema mismatches, flags access issues, and guides users through high-risk tasks.
Who uses the platform day to day shapes these benefits. Some tools prioritize data engineers, while others serve analysts, stewards, or business teams. Match the interface to your users to drive adoption and effectiveness.
When evaluating options, look for:
Clear visibility into job status with logs, alerts, and success/failure tracking
Ease of deployment through no-code or low-code interfaces for repeatable jobs
Built-in testing or dry-run options that validate new pipelines before production
Role-based access control to keep permissions manageable across teams
You also need to consider how design affects usability as needs grow. For example, Apache NiFi offers flexible visual flow control but can become complex at scale. Fivetran simplifies setup with a streamlined interface but trades customization. Both styles work when aligned with your team’s technical fluency and operational goals.
2. Review cost models
Teams often underestimate the long-term impact of pricing. Even with a budget for monthly usage, costs can rise as you add various sources, increase sync frequency, or scale projects.
Platforms use different pricing structures. Some charge by data volume, while others base prices on compute time or connector count. What’s affordable for one team can become costly for another as demands grow.
To evaluate effectively:
Estimate how much data you’ll move each month—and how often.
Check whether the platform charges for active rows, storage time, or job executions.
See how costs change when you add connectors or schedule more frequent syncs.
Factor in soft costs like engineering time for maintenance or troubleshooting.
For example, Fivetran’s active row model keeps early costs predictable but can rise at scale. AWS Glue uses a pay-per-job model for flexibility, though slower start times may affect time-sensitive workflows.
3. Evaluate performance at scale
Early testing often misses how a tool performs under real-world conditions. As data sources grow and sync frequency rises, ingestion workloads become more demanding. Without enough throughput, retry logic, or load balancing, a platform that runs smoothly with 10 pipelines may falter at 100.
When assessing performance, ask these questions:
Can it handle parallel jobs without degrading performance?
Does it retry failed syncs automatically and log why failures occurred?
Can it process high-volume sources like Salesforce, Oracle, or streaming logs with minimal lag?
Does it support dynamic scaling or queue management for busy periods?
For example, Kafka delivers distributed, high-throughput streaming with strong scalability but needs experienced oversight. Databricks Lakeflow automates ingestion at scale with reliable performance in the lakehouse, though it’s most effective when used within the Databricks ecosystem.
If you manage large-scale ingestion across regions or business units, performance at scale is essential.
➜ Discover how data quality impacts your ingestion workflows.
4. Data processing (Batch vs. streaming)
Your use case determines whether you need batch processing, streaming, or a hybrid that handles both. Here’s how the two main approaches compare:
Batch processing suits historical analysis, regulatory reporting, and cases where slight delays are acceptable. It often offers better cost efficiency at high data volumes.
Streaming supports real-time analytics, instant alerts, and responsive user experiences, such as e-commerce personalization, fraud detection, or IoT monitoring. It delivers fast insights but usually needs more complex setup and maintenance.
Most modern tools handle both, letting you match the method to your workload. For example, Kafka offers native streaming with batch capabilities, while Databricks LakeFlow combines both in one framework.
5. Integration capabilities
Your ingestion tool acts as the bridge between your data sources and data analytics stack. The fewer manual gaps you need to fill, the stronger and more resilient your system becomes.
Robust integration support plays a key role in that resilience. Native connectors cut setup time and risk, while open APIs give flexibility for in-house systems or custom workflows. The best tools offer both, adapting as your architecture evolves.
When comparing tools, assess the following aspects:
Number of built-in connectors for databases, SaaS apps, and file systems
Support depth for legacy systems like SAP, IBM DB2, or on-prem Oracle
Ability to push metadata into catalogs or governance platforms
Compatibility with downstream tools like Snowflake, Redshift, BigQuery, or S3
Different tools specialize in different environments. Choosing the right tool based on your integration needs can prevent technical debt and rework later on.
➜ Learn how integration depth supports effective data lifecycle management.
Beyond data ingestion tools: The support your workflows need
Successfully managing enterprise data requires more than fast ingestion. You also need a solid foundation for data management that transforms raw data into strategic value through governance, discoverability, and collaboration.
Alation’s Data Intelligence Platform provides that foundation. It complements ingestion tools by delivering metadata management, lineage tracking, and AI governance.
As Marcin Cinciala, a senior data engineer at Allegro, explains, “By pushing metadata into Alation, we have a much better overview and full visibility into data with preconfigured content, like data categories, lineage, workflows, reports, and more. [...] Alation helps us to be GDPR-compliant by building a privacy-aware data culture.”
Alation supports teams throughout the ingestion and ETL process in the following ways:
Providing end-to-end data lineage that maps how data flows from source to dashboard
Enabling proactive impact analysis so you can see what depends on each source before a failure or schema change disrupts operations
Tracking change propagation to help teams coordinate updates across connected systems
Monitoring data quality with built-in visibility into freshness, completeness, and anomalies
Mapping ownership and stewardship so teams know who’s responsible for each dataset and pipeline
Offering self-service analytics so users can find, understand, and trust ingested data without help from engineering
Pairing ingestion with Alation delivers more than data movement. It adds transparency, accountability, and workflow automation to review, assign ownership, and maintain oversight—turning data transfer into strategic management.
These capabilities turn ingestion into a strategic advantage, ensuring your data is accurate, accountable, and actionable. See how this works in practice by requesting a personalized demo exploring how Alation can strengthen your data ingestion processes.
- The important role of data ingestion tools
- 5 leading data ingestion tools: Which one is right for you?
- How to effectively compare data ingestion solutions
- Beyond data ingestion tools: The support your workflows need
Contents
Tagged with
Loading...