
For data leaders, AI promises to transform business operations by automating routine data management tasks, accelerating analytics, and enabling new forms of decision-making at scale. However, most organizations struggle with basic data accessibility—ensuring data is findable, consistent, and trusted across the enterprise. This can be due to various reasons, ranging from data silos to duplicate datasets to compliance hurdles that make access more complex. Ultimately, this leaves enormous value locked away in enterprise systems.
The answer isn’t just better tools, though. The solution lies in a far more comprehensive data management framework that turns scattered data into consistent, accessible information your team can act on. Unlike traditional approaches that focus on technology first, good frameworks prioritize business outcomes while preparing your organization for AI and advanced data analytics initiatives.
Discover how to move beyond basic data management practices by building and implementing a practical data management framework that will deliver measurable results and create a system that scales with your organization's AI ambitions.

Why do you need a data management framework?
Your current data setup may feel like a group of disconnected islands. Enterprise data sits in departmental silos, data quality lacks consistency and reliability, and tracking down the right information for important decisions takes weeks instead of hours.
This fragmentation costs your organization in three critical ways:
It slows decision-making when business leaders can't access trusted data quickly.
It multiplies regulatory compliance risks because teams struggle to track data lineage and maintain proper data governance frameworks.
It blocks AI initiatives that require well-prepared datasets and trusted metadata, which provide the context, lineage, and quality signals needed to ensure data is fit for each specific use case.
A structured framework changes this dynamic by creating clear pathways for data discovery and consistent quality standards—laying the groundwork for the key components of data management that make data truly AI-ready.
What are the 4 pillars of a data management framework?
A good data management framework rests on foundational pillars of governance, metadata management, and data quality. Together, these pillars create the structure organizations need to stay compliant, innovate confidently, and realize their data's full value.
1. Governance
Data governance forms the backbone of your framework. Rather than creating bureaucratic workflows, focus on governance that enables faster, safer data use. You can do this in several ways:
Start by identifying your organization's critical data elements, the 5% to 10% of the data that drives the most business value. Map these elements to specific business outcomes, such as customer retention, revenue growth, or operational efficiency.
Choose a governance model that fits your organizational structure. Centralized, decentralized, and federated approaches each have distinct advantages. For instance, centralized models work well for highly regulated industries like healthcare and finance, while federated approaches suit organizations with more autonomous business units like retail and manufacturing.
Implement data governance best practices by assigning clear ownership roles and creating automated policy enforcement wherever possible, such as through data quality checks. Role-based access controls are also worth implementing since they assign permissions based on a user’s role in the organization, ensuring data is only accessible to the right people.

The continuous improvement cycle shown above illustrates how governance, automation, and access controls reinforce one another over time, creating a framework that enforces compliance and adapts as business needs evolve. By making governance a routine part of daily workflows—whether to meet compliance mandates or to reduce risk—organizations create the foundation on which metadata management can deliver meaningful context for data use.
2. Metadata management
Metadata provides the critical context—such as definitions, lineage, and ownership—that transforms raw data into information users can understand, trust, and apply. Your metadata management framework should focus on these four core metadata categories:
Descriptive: Information such as titles, business context, creation dates, and stewardship details that make data easier to find and understand
Structural: Details like schemas, table and field relationships, and data types that show how data is organized and connected
Administrative: Metadata about permissions, ownership, data locations, and storage footprints that govern how data is accessed and maintained
Reference: Elements including data quality scores, source provenance, processing logic, and formula definitions that indicate reliability and consistency for use
Modern platforms bring these elements together by automating metadata collection and linking it to governance and lineage. This integration makes it easier for users to locate and trust the right data, while setting the stage for the next pillar: ensuring data quality.
3. Data quality
A data catalog lays the groundwork for effective data quality efforts. It first enables organizations to identify and understand their data landscape—this includes mapping inventory, usage patterns, and stewardship to prioritize the most impactful quality improvements (e.g., frequently used or mission-critical datasets). Without that visibility, quality initiatives risk targeting outdated or irrelevant assets and wasting resources.
Implementing a catalog also helps surface who truly understands the data—the right owners, stewards, and domain experts—so that both quality standards and governance roles are clear.
Once quality objectives are in place, the catalog supports transparent visibility into quality status. It allows users to see quality metrics like accuracy and freshness at the point of consumption, so they can make informed decisions with confidence.
4. Search and discovery
If your data ecosystem spans databases, lakehouses, BI dashboards, and more, traditional keyword-based lookup will fall short. Users on your team may not know exact dataset names or how technical terms align with business concepts. Intelligent search overcomes that by combining semantic understanding and keyword matching. For example, queries like “May revenue trends” surface relevant tables even if they’re titled “Monthly Rev_Summary.”
Achieving effective intelligent search requires more than a search box—it requires a well-curated metadata foundation, semantic models, and usage-driven contextual layers. Organizations should blend metadata richness (tags, lineage, quality scores, business terms) with the following:
AI-powered search capabilities, like natural-language interpretation
Filters for data quality or endorsement
Domain-level classification
Layering governance around these features ensures trust. Search results reflect relevance, data reliability, compliance status, and usage history, so users can act with confidence, knowing the data they find aligns with policy and context. With governance, metadata, quality, and intelligent discovery working in tandem, the next step is to translate these principles into a practical framework that organizations can implement and scale.
What are the steps for creating a data management framework?
Building an effective data management framework requires a strategic approach that balances immediate wins with long-term sustainability. The following steps will help you transform scattered data assets into a cohesive system that drives innovation and supports AI initiatives:
1. Decide on target business outcomes
The first order of business is to determine which business objectives matter most to your organization. The goal isn’t to govern every dataset; it’s to focus on the 5% to 10% of data that drives the most business value. To identify those outcomes, ask questions such as:
Which decisions are currently slowed by lack of high-quality data?
Which processes generate the most risk or cost when data is missing or inaccurate?
Which strategic initiatives—for example, cloud migration, AI adoption, or customer experience—depend on reliable, well-governed data?
Common high-priority goals include:
Revenue growth through better customer insights
Increased operational efficiency by reducing time-to-insight and duplicate work
Risk reduction and compliance improvement through audit readiness and privacy protection
Accelerated innovation and AI readiness by preparing curated, trusted datasets for advanced analytics
By tying data ownership to these outcomes, you can ensure that governance efforts remain focused and impactful.
2. Define ownership
Data ownership confusion kills more projects than technical failures, so assign specific data owners for the most used and business-critical datasets. Ownership should be shared across two complementary roles:
Business steward: Accountable for ensuring the dataset is tied to a clear purpose and delivers measurable value
Technical steward: Responsible for maintaining the dataset’s accuracy, quality, and accessibility
In some cases, one person may fill both roles, but their distinct responsibilities should always be explicitly defined. This dual model fosters accountability and accelerates issue resolution while keeping governance aligned with business priorities. It also ensures that ownership ties back to your desired business outcomes, not just technical upkeep. For example, when the marketing team owns customer data quality, their success metrics should include data completeness rates alongside campaign performance.
Your data catalog becomes the definitive source for ownership information, where anyone can quickly find the right person to contact about specific datasets.
To scale this model effectively across an enterprise, consider a federated governance or “hub and spoke” approach. This allows centralized governance to establish overarching policies and frameworks, while individual departments (like marketing) act as Centers of Excellence (CoEs), governing data that is most critical to their specific objectives.
3. Consolidate your data management tools
Most organizations unknowingly operate multiple tools that perform similar functions, a discovery that often shocks leadership during data audits. Referred to as “tool sprawl,” this creates confusion, drives up costs, and fragments your data management efforts.
Rather than replacing everything at once, choose a unified platform that consolidates data cataloging, governance, and quality monitoring, then integrate it with your existing infrastructure. Data management platforms offer APIs and connectors that work with popular databases, cloud platforms, and analytics tools, reducing disruption while providing a single source of truth for data policies.
4. Establish standards
Data standards are what turn good intentions into reliable, repeatable practices—they provide the common language that allows teams across the business to collaborate seamlessly and trust shared data.
Effective standards balance consistency with flexibility. Focus on standards that directly impact business outcomes, like ensuring customer IDs remain consistent across systems or requiring specific fields for regulatory reporting. For example, a retail company may standardize product categorization across departments. Instead of abstract policies, they provide concrete examples: "Electronics > Mobile Devices > Smartphones" rather than vague guidelines about "proper classification."
Teams adopt such standards quickly because they can see exactly how to apply them. For this to happen, though, your standards must be well-documented in your data catalog with examples in formats your teams can follow.
5. Prepare data for AI and machine learning initiatives
AI-ready data requires more than traditional quality measures. Your datasets must represent real-world conditions, including the edge cases and anomalies that separate successful AI models from failed experiments. For instance, fraud detection models need examples of both obvious and subtle fraudulent behavior, not just clean transaction data.
Building effective data prep pipelines means preserving important patterns while maintaining data privacy compliance. This might involve generating synthetic data that maintains statistical properties for sensitive datasets or using innovative sampling strategies that capture rare but critical events.
The strength of collaboration between AI teams and data stewards can influence project success, so it’s worth establishing regular feedback loops. AI initiatives depend on high-quality, well-documented data, while stewards rely on feedback from AI teams to ensure data assets remain relevant and trustworthy. If your organization wants to accelerate AI projects and reduce the risks of using poor-quality or misunderstood data, it’s important for these groups to work in sync.
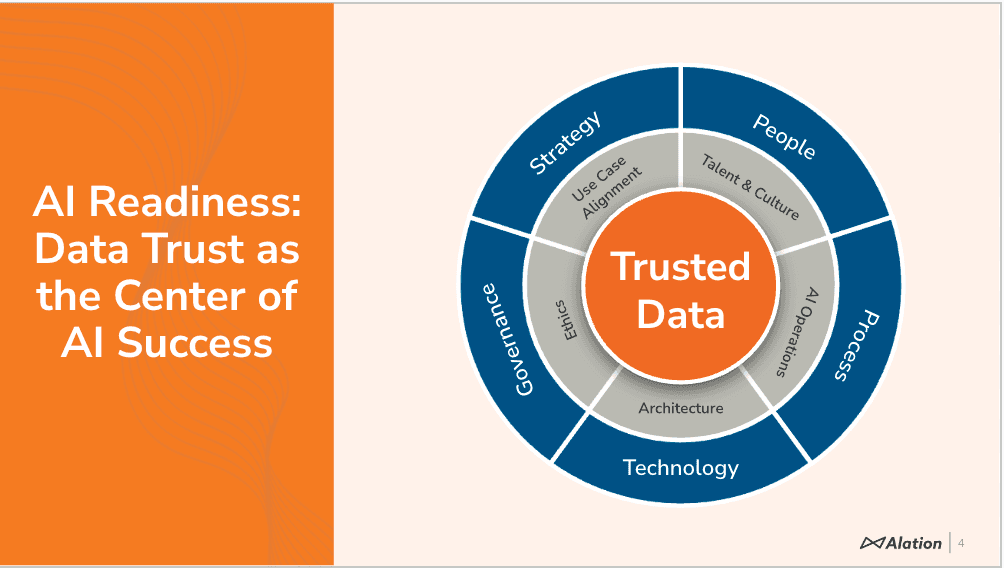
6. Ensure data quality and provenance for AI models
AI models inherit every bias and limitation in their training data, making lineage tracking essential for responsible deployment. You need complete visibility into how training datasets were created, transformed, and filtered—not just for debugging but also for explaining model behavior to stakeholders and regulators.

Document data decisions that impact model performance with the same thoroughness you'd apply to code documentation. For example, if you exclude certain customer segments from training data due to privacy concerns, record this decision so AI teams and end users understand model limitations and appropriate use cases.
Quality scorecards for AI datasets should include traditional measures like completeness and accuracy. AI-specific metrics, such as bias detection and representativeness scores across different demographic groups, are also key.
7. Manage unstructured and semi-structured data for analytics
While structured data provides the foundation, unstructured data often contains the most valuable insights (and the biggest management challenges). Customer emails, support tickets, and social media posts can reveal patterns that structured data misses, but they require different approaches to classification and quality control.
AI tools can automatically extract metadata from documents, images, and other unstructured sources, identifying personally identifiable information and classifying document types without manual review. However, achieving widespread adoption of the catalog depends on establishing clear classification schemes that make it easy for users to understand what information different datasets contain. Well-defined classifications improve discoverability, reduce duplication, and build trust in the catalog as the go-to source for data.
Unlike structured databases with defined retention policies, unstructured data often accumulates indefinitely, creating storage costs and compliance risks that compound over time. To manage it effectively, combine automated classification with clear governance policies that define how different types of content are tagged, accessed, and retained.
8. Pilot, measure, and iterate
Strategic pilots focus on high-impact use cases with clear success metrics. Customer analytics, regulatory reporting, and operational monitoring work well because they have obvious business value and measurable outcomes.
A 90-day pilot with a single business unit or dataset provides enough time to refine processes without overwhelming your organization. During this period, measure metrics like total assets curated, total active users, and top queries and search behaviors. These signals aid in linking governance to measurable results like faster time-to-insight, increased analyst productivity, and improved compliance posture.
Compliance reporting provides another powerful benchmark. Reducing the hours spent on audit preparation and regulatory filings not only frees teams for higher-value work but also lowers the risk of fines. The result is significant cost savings and a stronger compliance posture.
Post-pilot, continue to use regular surveys and usage analytics to help identify friction points before they become major problems. Plan quarterly reviews to assess both technical performance and business impact, then adjust your framework based on changing business needs and emerging technologies.

3 best practices for sustainable data management
Managing data sustainably is critical for organizations looking to balance efficiency with long-term growth. With the right strategies, businesses can optimize their resources while keeping data secure and compliant. Here are three best practices to keep in mind:
1. Implement dynamic policy management
Static policies quickly become outdated in today’s data ecosystems. Create policy frameworks that allow your organization to adapt rapidly to new data sources, changing regulations, and evolving business requirements. Then, use rule-based workflows that automatically apply policies to new datasets based on their characteristics.
Dynamic policy management ensures that governance scales as your data environment evolves, laying the foundation for accurate lineage tracking across systems.
2. Automate data lineage
Manual lineage documentation fails as data environments become more complex. Set up automated lineage tracking to follow data movement and transformations across your tech stack. In particular, focus on business-relevant lineage (as illustrated below), not just technical connections.

his lineage should offer varying depths and levels of detail, tailored to different personas and use cases. For instance, engineers may need column-level lineage to trace data flows, while analysts and business users benefit from high-level views that clarify how trusted datasets connect to reports and KPIs. Compliance teams, in turn, require lineage that highlights sensitive data usage for audit readiness.
Overall, flexible lineage ensures that governed data is actionable and relevant across the organization. As a bonus, it also provides the context AI systems need to recommend and enforce policies effectively.
3. Leverage AI for better governance
AI can automate many governance tasks that currently require manual effort and introduce the risk of human error. Seek a platform that uses machine learning to identify sensitive data, classify documents, and detect policy violations. For example, AI can automatically mask personally identifiable information (PII) from documents.
Use AI recommendations to suggest the appropriate policies for new datasets, based on their content and usage patterns. Doing so will lighten the load for your data stewards while maintaining consistent policies.
As a result, you’ll be able to prevent any gaps in your data management strategy. You’ll be continuously learning from policies and lineage, as well as ensuring that governance programs remain adaptive, scalable, and tied to business outcomes.
Put your data management framework knowledge into action
Building a data management framework is an ongoing journey, not a one-time project. Start by assessing your current state against the pillars above to identify the largest gaps between your current capabilities and your business objectives. Then, look for quick wins that deliver immediate value while you work toward larger transformation goals.
Your organization’s data is one of its most valuable assets, and a thoughtfully designed framework gives you a competitive edge. You’ll enable faster decision-making, elevate customer experiences, and power AI initiatives that drive measurable business outcomes.
See for yourself how top organizations are developing effective enterprise data management frameworks with our on-demand demo.
- Why do you need a data management framework?
- What are the 4 pillars of a data management framework?
- What are the steps for creating a data management framework?
- 3 best practices for sustainable data management
- Put your data management framework knowledge into action
Contents
Tagged with
Loading...