

For any data user in an enterprise today, data profiling is a key tool for resolving data quality issues and building new data solutions. In this guide, you’ll learn how to use profiling effectively, see its top use cases, and understand best practices to improve data quality and business outcomes.
Key takeaways:
Data profiling supports governance, migration, and pipeline reliability via better data quality.
Effective data profiling follows clear best practices.
Automated anomaly detection builds on profiling to enhance data observability.
Structured collaboration enables teams to solve quality issues effectively.
Pairing profiling with a data catalog unlocks additional benefits.
What is data profiling?
Data profiling is the process of analyzing and assessing the quality, structure, and content of data.
Data profiling technology examines data values, formats, relationships, and patterns to identify data quality issues, dependencies, and relationships. This is not to say it’s a tedious task for the modern data user. On the contrary, data profiling today describes an automated process, where a data user can “point and click” to return key results on a given asset, like aggregate functions, top patterns, outliers, inferred data types, and more.
How do other thought leaders define it? DAMA defines data profiling as: An approach to data quality analysis, using statistics to show patterns of usage, and patterns of contents, and automated as much as possible.
Gartner defines data profiling as: A technology for discovering and investigating data quality issues, such as duplication, lack of consistency, and lack of accuracy and completeness. This is accomplished by analyzing one or multiple data sources and collecting metadata that shows the condition of the data and enables the data steward to investigate the origin of data errors. The tools provide data statistics, such as degree of duplication and ratios of attribute values, both in tabular and graphical formats.
What do you learn about data through profiling? Most would say the following values form the basics of profiling:
Max Value
Min Value
Avg Value
# of Null Records – a Record Count
Max Length
Min Length
Inferred Data Type
Pattern Analysis – w/Record Count
Range of Values – w/Record Count
Matches LOV – List of Values – a Record Count
Details on these values empower data users to get a high level of understanding of the data. This, in turn, enables them to build new data pipelines, solutions, and products or clean up existing data.
It bears mentioning that data profiling has evolved tremendously. In the past, experts would need to write dozens of queries to extract this information over hours or days. Today, data profiling tools have made this process instantaneous, accelerating people’s ability to deliver new data products and troubleshoot quality issues.
What are the top use cases for data profiling?
Data profiling helps organizations validate and improve data in practical ways. These use cases show how data profiling delivers value across critical business areas:
Data governance
Data governance describes how data should be gathered and used within an organization, impacting data quality, data security, data privacy, and compliance. Data profiling helps organizations understand the data they possess with an eye to its quality level, which is vital for effective data governance.
Data profiling helps organizations holistically comprehend their data landscapes, as it documents data assets and dependencies, including data lineage, metadata, and data relationships. This documentation is crucial for effective data governance, as it enables organizations to understand how data moves through their systems, who owns the data, and how data is used across the organization.
Business data stewards benefit from having a breakdown of the patterns that exist in the data. With these details, a data steward focused on fixing a data quality issue can drill into it, find the issues, and then partner with the technical steward to leverage or create the tools needed to improve data quality efficiently and effectively. Data profiling details can be used to build out more extensive data policies and data quality rules as well to support more robust governance.
In summary, data profiling is a critical component of a comprehensive data governance strategy.
Data quality issue resolution
When things break, profiling is often the first step to finding the fix. Instead of embarking on a “hunting expedition,” profiling pinpoints anomalies quickly—such as unexpected characters, broken patterns, or invalid values.
Data profiling enables you to quickly pinpoint anomalies, rather than embarking on a hunting expedition.
Modern data profiling will also identify all potential problems in a single quick scan. It can identify the ten potential causes of a problem, rather than just one. This enables data engineers to rerun the profile and troubleshoot as they go, ultimately saving them time.
Data pipelines
For data engineers seeking to build new data products, profiling can help them understand data conditions, including:
Data Type
Data Rules
BI Data Validation Reports
Data Cleaning Needs – programmatic
Data Cleaning Needs – manual
Data profiling details give engineers a clear view of data conditions, helping them work more efficiently and cut the time needed to build new data products by half.
Data migration
Digital transformation is ongoing. Modern developers need to upgrade systems, be it bespoke, ERP, SaaS, or some other platform type. To achieve this, these developers need to build data pipelines that migrate data.
Yet data migration is often viewed as: (1) the Achilles heel of new software implementation; (2) the long pole to completion; or (3) the project headwind.
However, by using data profiling (and borrowing pipeline techniques), developers can lead effective migrations. This process involves conducting an early assessment, predicting the level of effort needed, and planning accordingly. This approach increases the confidence of the project team and enables them to deliver within a reliable timeline.
Master data management
The rollout of a new MDM application is very similar to an ERP system. However, it often takes much longer because integrations need to occur across multiple applications.
With data profiling, teams can see all the systems being integrated by the MDM project. They can then assess the level of effort required and use the profile results to accelerate building cross-reference tables (XREF), also known as crosswalk tables.
This allows rapid discovery of the uniform set of comparative values and helps to reduce the time to deploy. Using profiling proactively for MDM can also catalog enterprise information before the MDM tools are purchased, aligning human resource needs.
How to conduct effective data profiling: 5 best practices
Data profiling reveals data quality issues and patterns. Once you analyze the results, you can start planning next steps and asking sharper questions of data producers to prevent recurring problems.
The key is to treat profiling as a practical tool for solving problems and improving data initiatives. Too often, teams overlook its value when troubleshooting quality issues or building new products. For example, profiling customer data before launching a personalization engine can prevent wasted spend on bad recommendations.
Here are five ways to make your profiling more effective:
Establish rules
Define standards for clean, complete, and valid data as part of a supporting governance framework. Once these rules are in place, profiling can use them to assess data conformance and highlight exceptions. For example, a retailer might consider product IDs valid only if they are eight-character alphanumeric codes because this makes deviations easier to spot.
Define data profiling scope
Clarify which datasets, tables, or fields matter most. Profiling is often exploratory, so teams may start broadly and then refine the scope based on what they uncover.
For example, a finance team might begin by profiling all transaction data to understand why monthly reports keep showing unexplained variances. As they dig in, they might discover duplicate records, inconsistent date formats, or missing account codes. This insight could shift their scope from all transactions to current period data tied to revenue recognition. Narrowing the focus enables them to fix the reporting issue and establish rules to prevent it from happening again.
Use multiple data profiling techniques
A single method rarely uncovers every data issue, so combining approaches gives a fuller picture of data quality. For example, column statistics can reveal missing values, pattern recognition can flag irregular formats, and dependency analysis can catch inconsistent relationships between tables.
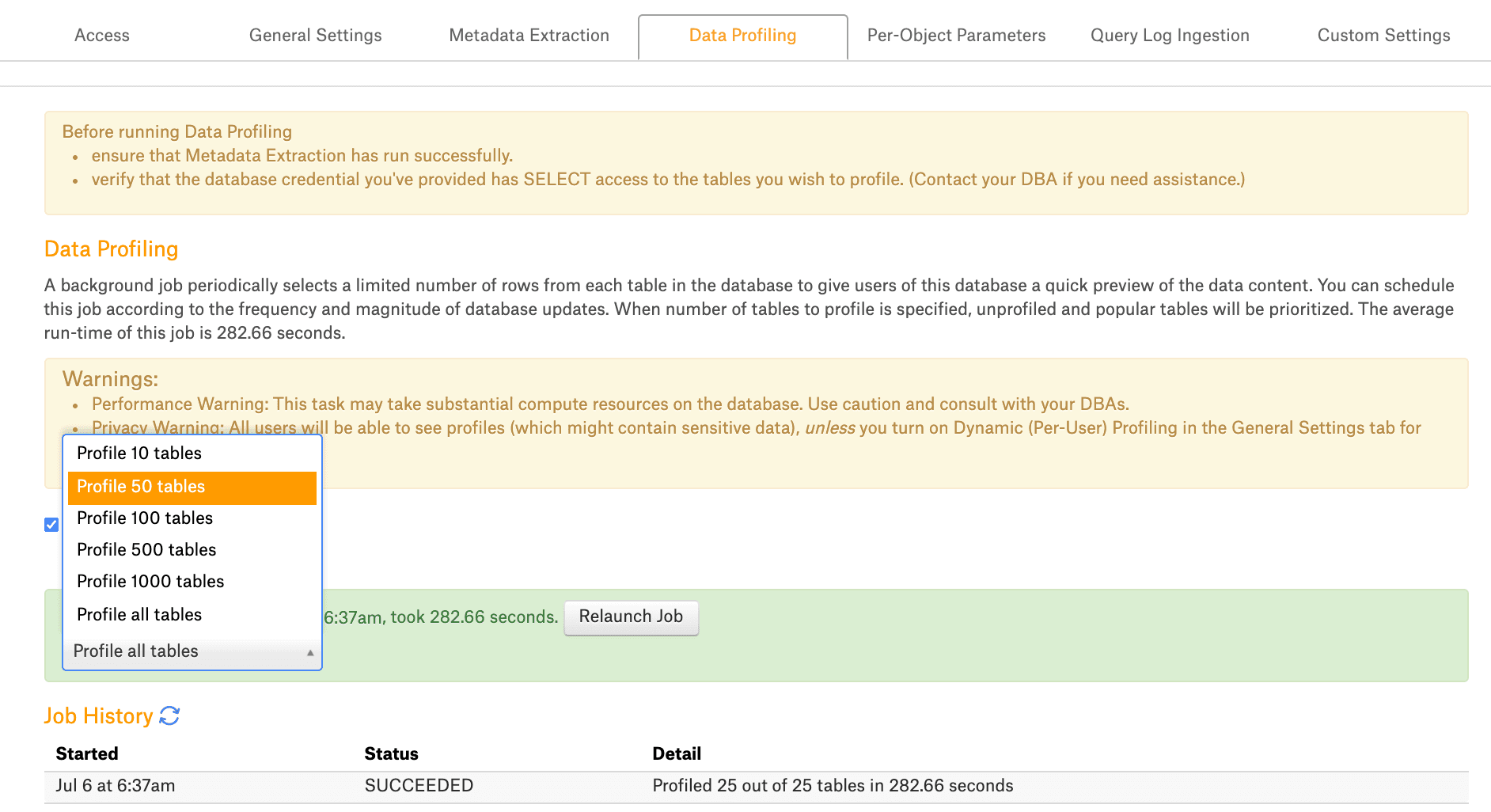
Alation makes this easier by letting users sample and analyze data at the schema, table, and column levels. This visibility helps teams spot anomalies, validate assumptions, and understand patterns across large, complex datasets.
Validate results
Use trusted sources, such as source systems or historical benchmarks, to validate profiling findings. This step ensures that what looks like a problem in the data is actually a genuine issue and not a system quirk. For example, a healthcare organization might cross-check patient demographics with registration records to spot real issues versus anomalies.
Incorporate data steward feedback
Data stewards provide context that tools can’t capture, such as explaining why legacy fields remain intentionally blank. Their input makes corrections practical and aligns them with business knowledge. As a result, they play a key role in enforcing centralized governance standards. Involving stewards strengthens the data quality review process and improves outcomes like more accurate reporting, fewer downstream errors, and faster issue resolution.
Ensuring the accuracy and reliability of data profiling results is critical for building trust in data. To do this, teams should review results with stewards, incorporate their feedback into data quality rules, and adjust processes based on their insights. This approach creates a steward-informed profiling process that strengthens the overall governance framework.
What are common techniques for data profiling?
Your profiling technique will largely depend on your use case and what you seek to accomplish. Look at the basic profile to determine your next steps, which can be broken down into questions:
Do you need to explore cross-column profiling?
Do you need to define a data quality rule and add that to the profile?
Do you need to find overlap between two tables—and use cross-table profiling?
Do you need to add metadata to information to put it in a data lake?
Do you need to migrate data from one system to another?
Simpy put? You run the profiling, then do the analysis on the results. Next, based on the type of data, you can start asking questions. If it’s product data, you may ask, do these dimensions make sense? Does it have a color? Should it only have a specific color? Or should there be 15 different versions of how you spell blue? Once you run the profiling and get the results, you can ask key questions to help your analysis and recommendations.
The value of automated anomaly detection
Automated anomaly detection uses algorithms to flag unusual patterns or outliers in data without requiring manual checks. Profiling complements this by providing descriptive statistics and trend insights. It also helps teams understand data distributions, spot irregular patterns, and report metrics like null rates or distinct counts.
Consider a retail company that profiles daily sales data. The profiling may reveal unusual transaction distributions for one region, signaling a potential issue that teams can investigate further. Automated anomaly detection monitors these same trends in real time. It detects sudden drops or spikes in sales volume, order counts, or transaction values, which may indicate system outages or data integration failures.
Keeping profiling and anomaly detection distinct but complementary gives organizations static insights from profiling and real-time awareness from observability tools. This approach helps them maintain trustworthy data and reduces the need for manual firefighting.
Addressing data quality issues through data profiling
Successful data profiling projects demand collaboration with data stewards and data owners. Here are some best practices to make data profiling for superior data quality a team sport:
Define roles and responsibilities
Assign ownership for each type of data issue. Data stewards in particular play a key role in enforcing governance standards while monitoring specific domains. For example, a steward might manage customer data quality while data engineers handle system-level corrections. Clear roles here can help them prevent overlap and ensure accountability.
Establish communication channels
Set up consistent ways to report, discuss, and escalate issues. In addition, use shared collaboration platforms, real-time ticketing systems, or Agile workflows to keep the team aligned. For example, pairing a weekly data quality review with a real-time issue-tracking system helps teams surface, track, and resolve problems quickly. This approach fits smoothly into modern DevOps or Agile setups.
Share results and findings
Document profiling results in a standardized format so teams can easily access and act on insights. To support this, highlight quantifiable metrics like null rates and deviations from expected thresholds, since these numbers make issues measurable. Clear metrics give teams a common reference point and make progress easier to track over time. Use dashboards to track trends and identify recurring issues. These tools let teams filter metrics and quickly drill into specific problems.
Prioritize data quality issues
As you identify issues, use profiling to spot trends that may indicate business or regulatory risk. Next, rank problems based on their potential impact on revenue, compliance, or analytics. Focus first on issues that pose the greatest risk of financial loss, regulatory penalties, or flawed decision-making. For example, missing product codes or inconsistent regulatory fields take priority over minor formatting errors.
Develop actionable recommendations
Finally, translate profiling findings into clear steps to fix or prevent errors. This step might involve adjusting workflows, improving processes, or creating automation scripts. Recommendations should also engage relevant stakeholders across data governance, quality, and business teams. Then, assign owners and deadlines to ensure accountability and follow-through.
For example, if profiling reveals a high null rate in customer email fields, the recommendation could be to add mandatory validation at the point of entry. A separate automated check can then flag records without emails. The governance team defines the rule and IT implements the automation. With ownership and deadlines in place, the issue gets fixed and stays under control.
Effective collaboration with data stewards and data owners is critical for data profiling. By defining roles and responsibilities, establishing communication channels, sharing results, prioritizing data quality issues, and developing actionable recommendations, organizations can strengthen governance and provide better support for decision-making.
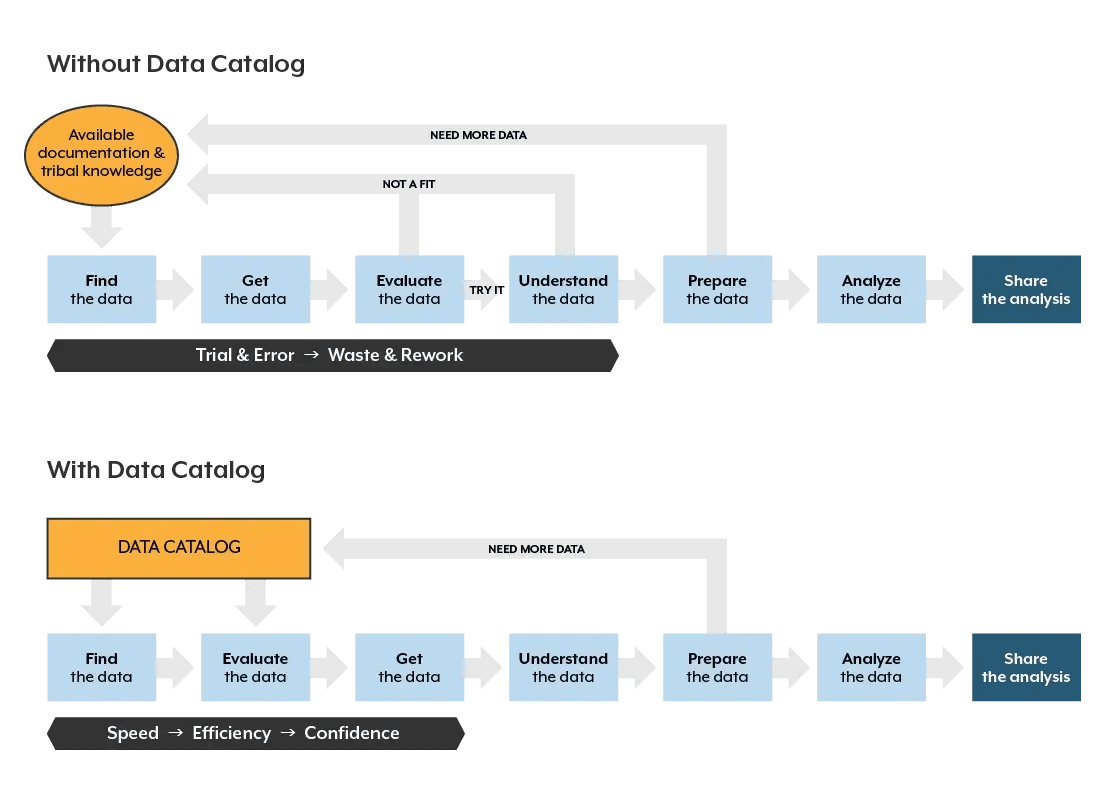
What are the benefits of data profiling with a data catalog?
Data profiling with a data catalog provides several benefits:
Enhances metadata management
A data catalog allows users to manage and store metadata, like data definitions, lineage, and ownership. By linking metadata with data profiling details, data users can better understand their data assets.
Improves collaboration
By enabling key stakeholders to share information about data assets and data quality, organizations can establish a more comprehensive data governance framework.
Increases efficiency
A data intelligence platform can streamline the data profiling process by automating certain tasks, such as data discovery and metadata management. This frees up data professionals to focus on more strategic initiatives.
Improves decision-making
Data profiling makes it easier to find and fix data quality issues, like missing or inconsistent data. This ability improves the accuracy of analytics, resulting in better business decisions.
Using a data catalog in tandem with data profiling makes managing and sharing data simple and fast. It also helps organizations unlock maximum value from their information assets.
Why AI needs trusted data to succeed
AI models can only perform as well as the data they learn from. When that data is incomplete or inconsistent, predictions become biased, inaccurate, or misleading. This bad data undermines both business outcomes and user confidence.
Without profiling, teams often discover data problems only after an AI model fails in production. By then, the damage is done, whether it is faulty customer recommendations, compliance violations, or lost revenue. Profiling shifts that work up front, making sure the data foundation is strong before models are built or retrained.
Data profiling lays the groundwork for AI trust by making data quality visible and actionable:
Reveal hidden risks: Profiling shows null rates, skewed distributions, or unexpected values that could bias training data.
Detect drift early: Continuous profiling highlights shifts in source data that may cause model degradation over time.
Trace accountability: Profiling builds lineage records so teams can explain which inputs influenced specific model behaviors.
Make AI explainable: Understanding the data itself helps connect model outputs back to real-world inputs and identify root causes of anomalies.
In short, investing in thorough data profiling goes beyond improving data quality. It also makes AI dependable, transparent, and actionable for end users.
Improve your approach to data profiling with Alation’s data catalog
Pairing profiling with Alation’s modern data catalog helps strengthen metadata management, collaboration, efficiency, and decision-making. In short, It helps organizations use data as a strategic asset more efficiently.
Learn how Alation can help your team implement profiling more effectively and drive higher data quality across your organization.
- Key takeaways:
- What is data profiling?
- What are the top use cases for data profiling?
- How to conduct effective data profiling: 5 best practices
- What are common techniques for data profiling?
- The value of automated anomaly detection
- Addressing data quality issues through data profiling
- What are the benefits of data profiling with a data catalog?
- Why AI needs trusted data to succeed
- Improve your approach to data profiling with Alation’s data catalog
Contents
FAQs
What is data profiling?
Data profiling is the process of analyzing the quality, structure, and content of data to uncover patterns, anomalies, and relationships. It provides insights like minimum and maximum values, data types, record counts, and patterns, helping organizations assess data accuracy, completeness, and consistency. Modern tools automate profiling, making it fast and accessible for business and technical users.
Why is data profiling important for businesses?
Data profiling is essential because it improves data quality, supports governance, accelerates data product development, and reduces risks during data migrations. By identifying anomalies and inconsistencies early, businesses can make better decisions, increase efficiency, and build trust in their data.
What are the main use cases for data profiling?
Key use cases include: - Data governance – documenting assets, lineage, and dependencies. - Resolving data quality issues – quickly identifying anomalies in failing records. - Building data pipelines and products – understanding conditions for clean, accurate data. - Data migration – assessing complexity and planning system upgrades. - Master Data Management (MDM) – ensuring consistent values across integrated systems.
What techniques are used in data profiling?
Techniques vary by use case but include: - Column profiling – analyzing values within a single column. - Cross-column profiling – detecting dependencies or correlations between fields. - Cross-table profiling – identifying overlaps and relationships between tables. - Pattern and rule analysis – checking formats, ranges, and data quality rules. These techniques enable deeper exploration and validation of data quality.
What are best practices for effective data profiling?
To get the most from data profiling, organizations should: - Define the scope of data profiling. - Establish clear rules for completeness, accuracy, and consistency. - Use multiple profiling techniques, including statistical analysis and pattern matching. - Validate results against business requirements. - Incorporate feedback from data stewards and stakeholders.
How does data profiling help resolve data quality issues?
When errors occur, data profiling provides a fast way to pinpoint root causes, such as unexpected characters, invalid values, or duplicate records. Instead of manually searching, automated profiling surfaces anomalies across entire datasets, allowing engineers and stewards to troubleshoot and remediate issues efficiently.
What are the benefits of using a data catalog with data profiling?
Integrating data profiling into a data catalog enhances metadata management, improves collaboration across teams, increases efficiency through automation, and strengthens decision-making. By linking profiling results with metadata, organizations gain a more complete understanding of their data assets, supporting both governance and analytics.
How can businesses implement effective data profiling techniques to improve data quality?
To start, businesses should define the scope of profiling and set clear data quality rules. Next, apply techniques such as column analysis and pattern checks. Then, validate findings against trusted sources and gather feedback from data stewards to ensure insights are meaningful.
Following these steps helps teams gain a clear, actionable understanding of their data, identify quality issues early, and take targeted steps to improve data flow and reliability.
What are some examples of data profiling in real-world business scenarios?
Profiling focuses on identifying unusual distributions, missing values, or duplicates. This approach helps teams detect potential data issues before they impact reporting, analytics, or AI.
In retail, profiling can reveal unusual sales patterns or unexpected gaps in transaction data. Similarly, finance teams can profile distributions in transaction records to spot anomalies or inconsistencies. In healthcare, profiling may uncover unusual patterns in patient demographics or visit counts.
Which data profiling tools are most effective for managing large and complex data environments?
For large datasets, platforms that combine profiling with cataloging and governance work best. Alation, for example, merges automated profiling, anomaly detection, and metadata management, helping teams spot issues, ensure compliance, and collaborate efficiently. This capability keeps data accurate and ready for analytics, reporting, or AI.
Tagged with
Loading...