

Modern organizations are facing increasing pressure to extract insights from their data. However, without clear data classification, they struggle with disorganized, fragmented information that’s difficult to access and prone to risks. As a result, data quality becomes a major concern. According to Precisely’s 2025 Planning Insights Report, 64% of organizations cite data quality as one of their biggest challenges, with 67% saying they don’t completely trust data to guide decisions.
Proper data classification helps you solve these challenges by categorizing data based on sensitivity, value, and usage so it’s protected and accessible. By implementing an effective classification strategy, businesses can streamline their workflows and enhance their data security. This empowers teams to make more informed decisions and ultimately maximize the value of their data.
Key takeaways
Data classification organizes data by sensitivity and usage by combining manual and automated methods for scalability and accuracy.
Organizations typically use three classification types: content-based, context-based, and user-based. Each is suited to different use cases.
To classify data, define business goals, categorize data, set classification levels, and establish processes for monitoring workflows.
Modern classification systems automate discovery, apply metadata-driven policies, and provide audit-ready reporting for better governance.
Alation’s Data Intelligence Platform simplifies classification with AI tools that automate discovery and policy application and provide audit-ready reports.

What is data classification?
Data classification is the process of analyzing and organizing data into categories—based on sensitivity, value, or usage—to strengthen security, compliance, and accessibility.
Organizations classify both structured and unstructured data, using labels such as public, internal, confidential, or restricted. This process may be done manually or with automation, applying context, content, and business rules to assign accurate labels. By mapping data to its risk and business value, classification ensures that sensitive information receives the right protection, while high-value data supports smarter decision-making.
Data classification is essential for compliance with regulations like GDPR, HIPAA, and CCPA, which often require organizations to demonstrate they understand and control their data. Beyond compliance, classification streamlines access control, improves governance, and boosts efficiency by clarifying what data exists, where it resides, and how it should be used. In doing so, it reduces the risk of breaches while enabling organizations to maximize the value of their information and safeguard data security.
Manual data classification
Manual data classification is when data owners or users determine and create the data classification policies. It involves the following actions:
Entering assets into a data catalog
Determining and setting sensitivity levels
Labeling assets
Ensuring that teams use the asset properly based on its classification
As your organization collects and uses more data, manual data classification can become overwhelming for data owners. This is why many organizations leverage automated data classification, which augments labeling projects with help from AI governance and machine learning (ML).
Automated data classification
The following two kinds of automated classification have grown popular with organizations that manage large, complex datasets:
Real automation uses ML to locate certain data categories and label them appropriately based on common patterns (for example, a passport number has a letter followed by 9 digits, and a social security number is 9 digits long). Since sensitive data types are often interlinked, automation helps teams analyze and categorize them more efficiently.
Hybrid automation combines human input with automation by creating rules to classify data. For example, an “if-then” rule applies labels based on column titles, such as “IF column title = name, THEN label as PII.”
Although AI and ML can streamline classification, human context remains essential for accuracy. Hybrid automation offers a balanced approach, combining the speed of automation with the nuanced understanding of human judgment, especially in large, complex data environments.
Why is data classification important?
Data is only as good as your ability to use it effectively. Without knowing what you have, you won’t be able to maximize the value of it. You also need to protect the sensitive data. Whether from a data security or privacy perspective, you need to limit access to PII like names, addresses, telephone numbers, banking information, and social security numbers.
Here are some of the ways data classification makes it easier to leverage information while keeping sensitive data protected:
Maintain governance and compliance
As organizations collect more data, properly managing access becomes increasingly critical. Risks are always present, but without classification, they’re far harder to identify and control. Classification makes those risks visible and actionable by labeling PII such as credit card numbers or patient records and applying the right safeguards. This process helps businesses enforce security measures and comply with GDPR, HIPAA, CCPA, and other regulations.
Data classification helps organizations:
Protect sensitive data by labeling it according to its level of sensitivity.
Identify compliance obligations by tagging data that falls under specific regulations (like PCI, HIPAA, SOX, and BCBS).
Respond to regulatory requirements, such as the Right to Be Forgotten or data subject access requests (DSARs).
Support access controls by providing the labels that security policies use to restrict or grant visibility based on roles.
For example, when an organization pulls employee data, such as salary information, it must restrict access to specific users, like human resources. Data classification helps by labeling and masking data based on access rights.
The result? Analysts can still work with aggregated data because the system conceals employee names while giving authorized users access to salary information. This approach protects sensitive details and still enables necessary analysis—all while meeting privacy laws.
Accelerate data analytics
Beyond compliance, data classification can maximize the return on investment of your analytics tools. Here’s how:
Time savings: Classification enables business users to quickly discover and use relevant data, reducing time spent searching and accelerating analysis.
Operational efficiency: Organized tagging and categorization provide secure, structured access to data, helping users find what they need without compromising security.
By implementing data classification, you’ll clearly understand what data you have and where it’s located. These insights are essential not only for maintaining regulatory compliance but also for democratizing access in a controlled manner.
Streamline cloud migration
As you begin to migrate data to the cloud, you need a way to understand what data is most critical to your operations. Data classification helps you rank your most used data, which is a reliable indicator of your most useful data. Visibility into this data empowers you to ensure that you migrate only your most valuable data to the cloud.
By focusing on high-value data, leaders broaden access and drive smarter, more efficient analysis. A cloud migration strategy begins by asking, “Which data is most valuable to migrate?” and “What data can be securely moved to the cloud?” Framing migration with these questions aligns business priorities with technical execution, helping organizations cut costs while reducing risk throughout the process.
Mitigate security risk
For many organizations, security and compliance are primary data classification drivers. You can’t protect what you don’t know you have or where you have it. Financially motivated cybercriminals may try to steal sensitive data if you don’t properly protect it.
3 types of data classification and examples
Why categorize data? The answer often links to your reasons for engaging in the process in the first place. But since data has multiple uses nowadays, there’s no “one-size-fits-all” approach.
Across the industry, these three traditional approaches to data classification work as best practices. However, you may want to use only one or two, or even all three, depending on your data strategy.
Content-based classification
Content-based classification addresses security or privacy compliance mandates. This process involves inspecting files for sensitive, personal, and confidential information. Then, teams label them accordingly. This classification often supports compliance by labeling files that contain sensitive or regulated information.
For example, under HIPAA, a hospital must label electronic protected health information (ePHI) to protect it from unauthorized access. While classification helps meet these needs, it complements—rather than replaces—the broader regulatory requirements imposed by HIPAA.
Context-based classification
Context-based classification examines how people use the information and who has access to it. This process focuses on the application, location, or creator to determine whether the information is sensitive.
For example, since local regulations increasingly mandate how you can use data within a specific geographic region, a multinational corporation may tag the data generated in Iceland with its origin. That way, the data’s users will know that they must comply with the stringent Icelandic law.
User-based data classification
This classification type relies on manual processes. This is because often people have unique knowledge and must use their discretion to classify data.
With user-based data classification, users review documents, files, or databases and then categorize them based on their personal jurisdiction. However, it’s important to set the appropriate permissions or tracking so you maintain control over how they classify it.
For example, if a data steward must retroactively label data as sensitive, they can use lineage capabilities in a data catalog to track related data and label the sensitive data accordingly.
Data classification helps organizations mitigate this risk with the following actions:
Labeling sensitive data so you can limit access and mask it if necessary
Reducing the number of locations where you store sensitive information to reduce the attack surface
Integrating sensitive data types into your data loss prevention and other policy-enforcing applications
When you classify sensitive information correctly by applying role-based and attribute-based controls, authentication becomes easier. These security controls limit access based on a user’s role and location, as well as the data’s sensitivity level, so only authorized users can access sensitive data.
Data classification use cases
Data classification helps organizations make the most out of their data by organizing and tagging it in ways that drive analytics and support business goals. Below is a key use cases highlighting the impact of Alation Data Catalog in enabling efficient data classification:
Hulu (now Disney) used Alation to maximize the value of viewership, content, and engagement data by making it more accessible to users. By leveraging data classification, Hulu has built a foundation for accessibility and trust, which enables better collaboration, data stewardship, and data democratization at scale.
These use cases highlight how classification enhances accessibility and accelerates decision-making. As organizations increasingly rely on data products for AI-driven insights, they must classify those products correctly to maintain trust, improve explainability, and deliver reliable outcomes.

How can you prepare data products for AI via classification?
Effective classification is crucial for preparing data products that are not only usable but also trustworthy and explainable for AI model training. By categorizing data according to its importance, access needs, and intended use, teams take the first step toward making the right data available for AI. Still, classification alone isn’t enough. Organizations must combine it with access controls and security measures to fully safeguard AI implementations.
Here’s how classification enables organizations to prepare data for AI:
Ensures discoverability: By classifying data based on its sensitivity, value, and usage, teams can quickly identify and access the data they need for model training.
Builds trust: Labels clarify data’s accuracy, completeness, and reliability, which is essential for boosting model confidence.
Facilitates explainability: Classification offers context about how teams collect data to ensure transparency and support model explainability during audits and reviews.
Properly classified data lays the foundation for AI success, but many organizations struggle to apply these practices consistently across complex data environments. This is where the Alation Data Intelligence Platform delivers value—automating classification, embedding governance into workflows, and ensuring AI models train on reliable, trustworthy data.
➜ To ensure data quality throughout this process and enhance AI success, consider implementing a data quality management framework.
What are the 6 steps of data classification?
If you’re embarking on your data classification journey, you’ll need to create and follow a plan. A clear data classification process ensures that you have defined goals, standard naming conventions, and prioritized workflows.
Here are the steps your organization should follow when classifying data:

1. Define business objectives
Start by clarifying your organization’s goals. Data classification works best when it directly supports these objectives. If your priority is compliance, align the strategy with regulatory requirements. If your aim is efficiency, focus on making data easier for analysts to find and use.
For example, when GDPR compliance is the goal, you need to label PII according to regulation guidelines so sensitive data is managed and accessed appropriately.
2. Categorize data types and establish classification levels
The next step in the process is to assess risk. You’ll need to identify the data that you collect to appropriately set sensitivity and risk levels. Your classification or sensitivity levels can be low, medium, or high.
Low sensitivity data is anything that’s intended to be public.
Medium sensitivity data includes emails between employees and external recipients.
High sensitivity data is data that falls into a protected category, like PII.
To maintain consistency across all your data, ensure that your classification definitions are clear, well-defined, and easy to understand. Doing so will guide your team in applying classification levels accurately, minimize errors, and ensure compliance.
3. Define classification processes
Once you’ve identified your business objectives and data types, start creating processes to maintain your data classification initiatives. This involves scanning data to apply classifications in a systematic order. Then, determine which data you should classify automatically and which requires user input.
For example, the system could automatically scan and classify financial records based on sensitivity, while users tag marketing content so it aligns with your company’s specific categorization standards.
➜ Learn more about how to ensure data consistency and quality.
4. Determine categories for classification
Depending on the data you collect, you might have multiple categories of sensitive information. Overlapping rules may be at play, too. We’ve all heard the saying, “All squares are rectangles, but not all rectangles are squares,” and similar rules are likely to arise in this step.
For example, some PII is PHI, but not all PHI is PII. All privacy regulations classify a social security number as both PHI and PII. Meanwhile, a medical record number is PHI, but it may not fall under the more general term of PII for other regulations.
Determining categories for classification supports compliance. If you’ve identified the types of data that need protection under a regulation, then you can use data classification to help you meet those requirements.
5. Identify classified data usage for compliance
Identifying usage focuses on who should have access to data and how they should use it. This means defining how employees can use sensitive information within the organization so you can set the appropriate compliance controls around it—like masking data or restricting access entirely, based on a user’s permissions.
AI-powered data catalogs significantly enhance this process by integrating data quality management directly into your workflows. These catalogs also help organizations maintain clean, reliable, and compliant data, which makes it easier to apply classification policies and enforce access controls based on sensitivity.
6. Monitor and maintain workflows
Data classification isn’t just a one-and-done process. You’ll also need to create streamlined workflows that allow you to classify data appropriately as you collect it and to classify new data as you discover it.
By actively managing and maintaining these workflows, you’ll ensure that your data remains organized, compliant, and ready for analytics. This supports business decisions without risk.
What are the main capabilities of modern classification systems?
Modern classification systems go beyond static labels. Unlike legacy tools that rely heavily on manual work and siloed policies, today’s platforms combine automation, metadata, and governance workflows to classify data at scale. The following capabilities make classification more accurate and more useful for compliance, analytics, and AI:
Automated discovery of sensitive assets
Modern systems use automation to scan data sources and detect sensitive elements like personal identifiers, health records, and financial information. This automation reduces reliance on human judgment and handles data volumes that manual methods can’t manage. Plus, it enables quick recognition of sensitive data, even as you add new sources.
Metadata-driven classification policies
Classification becomes more consistent and scalable when it builds on metadata. When you apply rules that align with business policies, systems can categorize data based on file type, source, ownership, or usage context. This metadata-driven approach offers flexibility. Teams can adjust policies as regulations evolve or as the business sets new risk thresholds, all without rescanning the entire dataset.
Ensuring solutions remain configurable is critical because compliance requirements shift over time. Tools that adapt without retroactive changes or added engineering effort deliver real value, whether the policies rely more on business or technical metadata.
Audit-ready classification reporting
Modern systems make reporting a core feature by generating audit-ready outputs. These outputs show which data you classified, how you applied policies, and whether you enforced controls. These reports provide regulators and auditors with confidence while helping internal stakeholders track progress. These audit-ready reports transform classification from a back-office function into a visible, measurable capability that supports compliance and risk management.
Data classification with Alation
Effective data classification helps organizations manage, protect, and leverage their data efficiently. The Alation Data Intelligence Platform simplifies this process by automating data discovery, tagging, and governance at scale. With AI-powered metadata enrichment, Alation enhances data discoverability and ensures that you’ve accurately categorized sensitive data so it meets compliance requirements and drives informed decision-making.
Here’s a look at how Alation’s catalog surfaces data products with PII classification, helping teams quickly identify sensitive information.
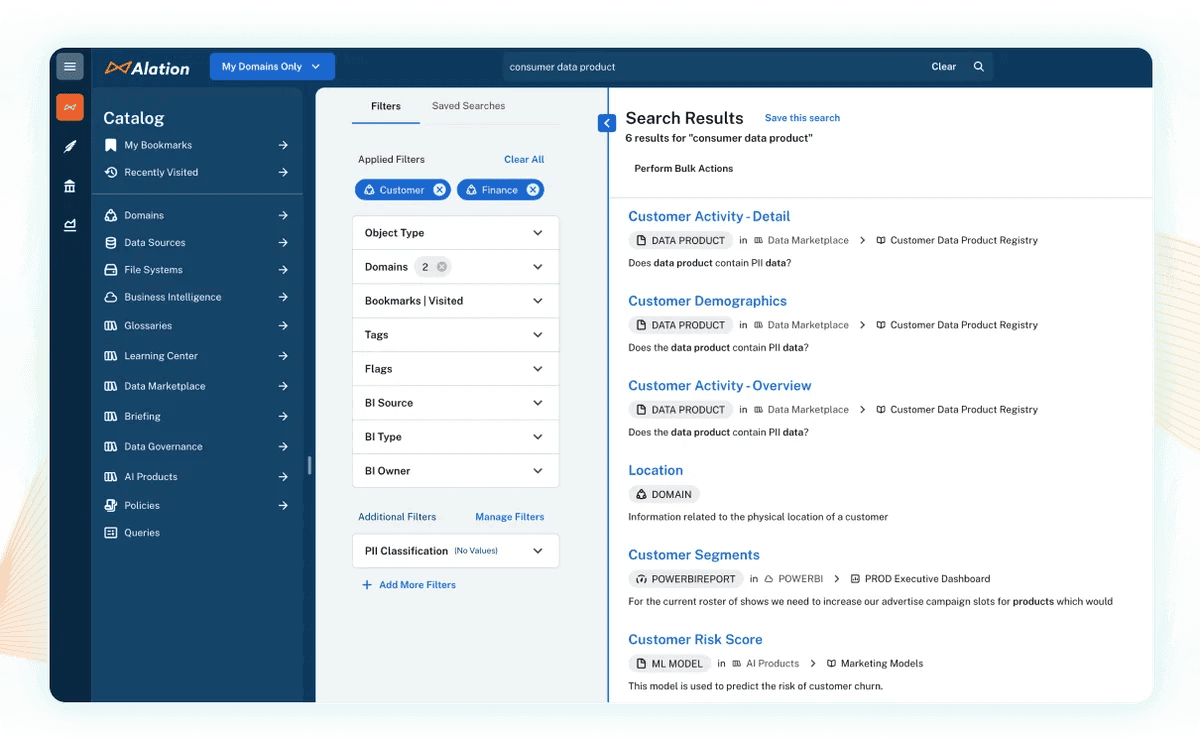
By embedding classification into governance workflows, Alation enables businesses to apply policies seamlessly, automate data masking, and improve operational efficiency.
Key capabilities that support classification include:
ALLIE AI: Enhances data curation, discovery, and governance. It streamlines classification by intelligently suggesting stewards, titles, and descriptions.
Data Products Builder Agent: Uses generative AI and catalog metadata to help organizations create high-quality data products faster. It begins with business use cases and ensures alignment with organizational objectives.
Workflow Automation: Automates manual and repetitive tasks, such as applying security classifications and updating policies. The automation improves efficiency and ensures consistent application of governance rules.
AI governance: Provides tools for lineage tracking, AI documentation, data discovery, and custom tagging. These capabilities ensure that AI models rely on secure, compliant, and well-documented data.
Chat with Your Data: Offers a metadata-aware AI assistant that lets users ask questions in plain language and receive trusted, explainable answers. The assistant works on curated data products and metadata, ensuring that responses remain accurate, transparent, and governed by design.
Chris Aberger, CEO of Numbers Station, highlighted the platform’s impact: “With Alation, we’re realizing a shared vision: making AI useful by grounding it in structured metadata and enterprise context. This integration turns the promise of generative AI into real, explainable action for business and data teams alike.”
By integrating these capabilities, your organization can streamline the data classification process and enhance governance. This approach also ensures that data is AI-ready, driving more informed decision-making and improving business outcomes.
For more information, request a free demo to learn how Alation can help your organization optimize the governance of your sensitive data.
Or to explore best practices for automating governance tasks (including data classification) and discover how to boost your data-driven insights, download Alation’s free whitepaper today.
- Key takeaways
- What is data classification?
- Why is data classification important?
- 3 types of data classification and examples
- Data classification use cases
- What are the 6 steps of data classification?
- What are the main capabilities of modern classification systems?
- Data classification with Alation
Contents
FAQs
What is data classification?
Data classification is the process of analyzing and organizing structured and unstructured data into categories based on factors like file type, content, or metadata. Classification ensures data is properly labeled according to sensitivity, regulatory requirements, or business use cases, making it easier to secure, manage, and leverage effectively.
Why is data classification important?
Classification is critical because it helps organizations protect sensitive data, maintain compliance with regulations like GDPR, HIPAA, and CCPA, and improve data analytics efficiency. It enables secure access to data, reduces risk from breaches, accelerates self-service analytics, and supports better decision-making. Without classification, organizations can’t fully understand or trust their data.
What are the main types of data classification?
Most organizations use four levels of classification:
Public data can be shared freely with anyone.
Internal data stays limited to employees.
Confidential data requires tighter controls, such as masking or encryption.
Restricted data represents the most sensitive category and includes assets like financial accounts and health information.
These levels provide a clear structure for protecting information consistently and ensuring compliance with security policies and data privacy standards.
How does automated data classification work?
Automated classification uses rules, AI, and machine learning to identify sensitive data based on patterns (like credit card or passport numbers) and apply labels automatically. Hybrid approaches combine automation with human review, allowing organizations to scale classification efficiently while preserving critical context.
How does data classification support governance and compliance?
Classification provides the foundation for effective governance by labeling sensitive data, mapping it to applicable regulations, and controlling access through policies. Integrated with a modern data catalog like Alation, classification ensures that governance rules are visible at the point of data discovery. For example, Alation enables policy enforcement, sensitive data masking, and metadata tagging to support compliance with laws like GDPR or HIPAA.
How can data catalogs improve data classification?
Data catalogs centralize classification policies, automate tagging across systems, and capture lineage so stewards know where sensitive data resides and how it flows. With Alation, organizations can automatically classify PII, enforce policies, and provide business users with self-service access to trusted data while still protecting compliance-critical information.
What role does data classification play in cloud migration?
When migrating to the cloud, classification helps organizations identify and prioritize their most valuable and frequently used data. This ensures only high-value data is migrated, lowering costs, reducing risk, and improving efficiency. Data catalogs enhance this process by providing visibility into sensitivity levels, ownership, and usage patterns that guide migration strategies.
What steps are involved in a data classification process?
Organizations typically follow six steps: - Define business objectives. - Categorize data types and set classification levels. - Define classification processes and rules. - Determine categories (e.g., PII, PHI). - Identify usage for compliance and set controls. - Monitor and maintain classification workflows continuously.
How does Alation help organizations with data classification?
Alation’s data catalog automates mapping and categorization of sensitive data, applies governance policies, and masks private information to ensure compliance. Customers like Hulu and Texas Mutual use Alation to accelerate classification, improve stewardship, and reduce operational costs. By integrating classification with governance, Alation makes data discoverable, trusted, and compliant at scale.
What are some best practices for implementing a data classification policy in a business setting?
Implementing a data classification policy requires both structure and adaptability. The following practices help organizations build policies that are effective and sustainable:
Begin with clear objectives and categories that align with business needs and regulations.
Use automation to manage scale, while maintaining human oversight for context.
Train employees so they consistently label assets such as credit card numbers and intellectual property according to their sensitivity.
Review policies regularly to keep them accurate and relevant.
Embed classification into governance workflows to ensure the policy is practical, repeatable, and aligned with daily operations.
Together, these practices create a policy framework that balances accuracy, compliance, and usability.
➜ Learn more about data cataloging best practices.
Can data classification requirements vary by region or industry?
Yes, regulations and industry standards influence classification requirements. Healthcare organizations must protect patient information under HIPAA, while financial services firms must comply with PCI DSS for payment data. Regional laws like GDPR in Europe or CCPA in California add further obligations. Businesses that operate across multiple regions or sectors should design policies that meet the strictest applicable standards to reduce compliance risk and protect sensitive cybersecurity data.
Tagged with
Loading...