
Metadata is “data about data” that describes the content, context, and structure of information—making it easier to find, understand, trust, and use.
Examples of metadata include file names, authors, creation dates, schema details, and usage history. But in today’s enterprise landscape, metadata is far more than labels. It acts as the connective tissue that gives data meaning and actionability—helping people determine whether data is reliable, compliant, and fit for use in analytics or AI. As AI projects scale from pilots to production, the quality of your metadata often predicts the quality of business outcomes.
Organizations manage metadata through frameworks and catalogs that automate discovery, classification, and lineage. This strengthens governance, enhances transparency, and prevents issues like duplication, conflicting KPIs, or audit risk. When applied effectively, metadata management turns scattered data assets into a coherent, governable knowledge fabric that improves discovery, boosts data quality, and accelerates decision-making.
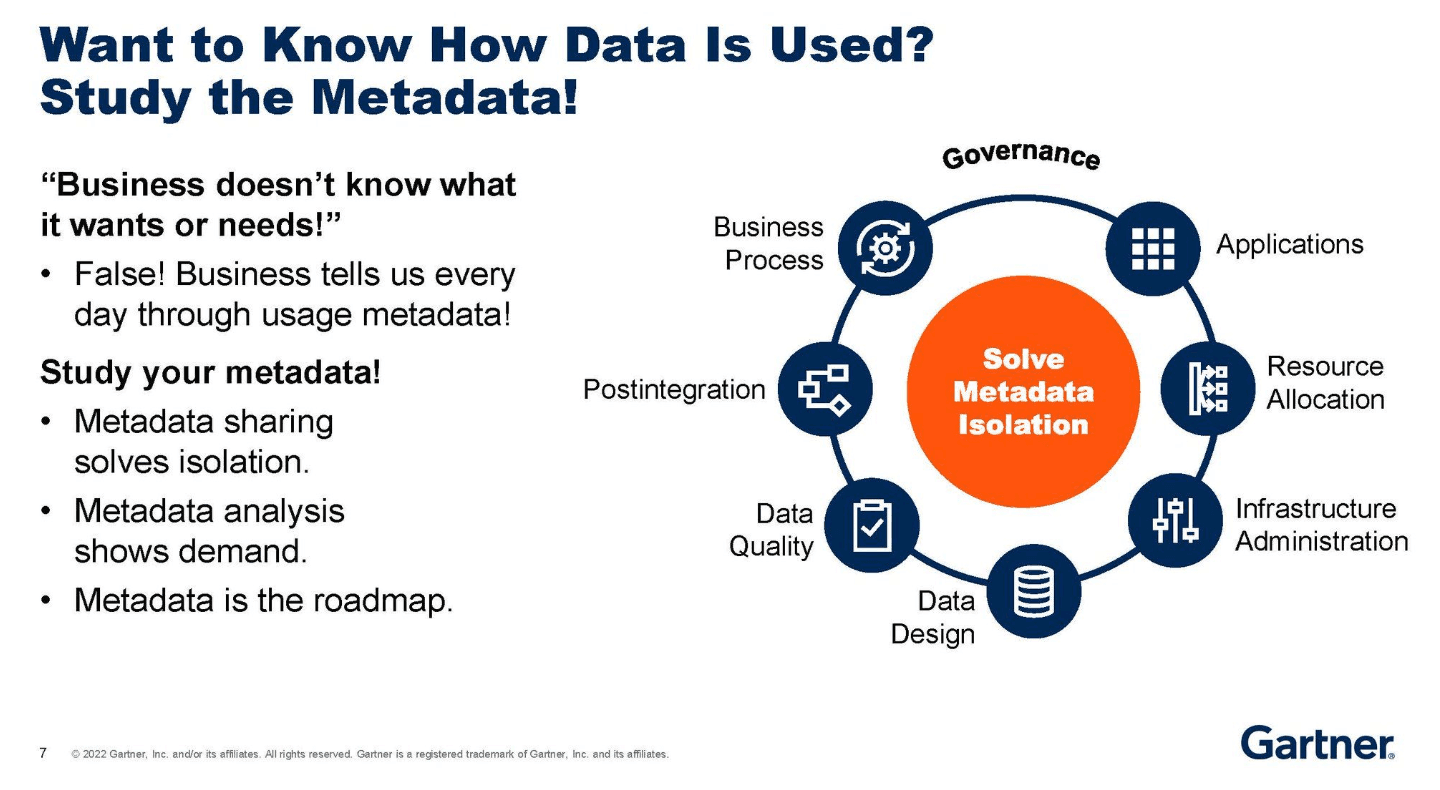
This blog is a practical primer on the types of metadata and how to work with them to drive business success. We’ll define the different types of metadata used in modern data management, show how to apply them across repositories, workflows, and different systems, and share concrete tips to improve data discovery, data quality, and decision‑making.
Key takeaways
Metadata is a multi‑type system—business, technical, compliance, operational, and behavioral—and each type answers different questions for different users.
Combining metadata in a catalog creates a shared language and a single pane of glass to discover, govern, and operationalize data across teams and tools.
Activation matters: use AI to automate curation, apply usage analytics to surface trusted assets, and design a thoughtful taxonomy so people can actually find what they need.
Standards like CWM and DCAT improve interoperability and portability, especially across lakehouse, warehouse, and open data ecosystems.
Cloud, ML, and LLM use cases depend on rich metadata to ensure scalability, cost control, reproducibility, privacy, and safety.
Measure value with outcomes (time‑to‑insight, reduced data downtime, faster audits, model risk mitigation), not activities (number of tags created).

Key metadata types, examples, and users
Metadata has been discussed in academic and industry literature since at least the 1960s. What’s evolved is how we use it. The following categories capture the forms of metadata that materially improve analytics and AI in modern enterprises.
Business metadata
Purpose: Define business meaning in human language.
Why it matters: Consistent, decision‑oriented definitions reduce time‑to‑trust and prevent conflicting metrics in business intelligence. For example, an Active Subscriber KPI should include the full formula, valid filters, and a link to the certified table powering dashboards—so analysts do not reverse‑engineer logic across different systems.
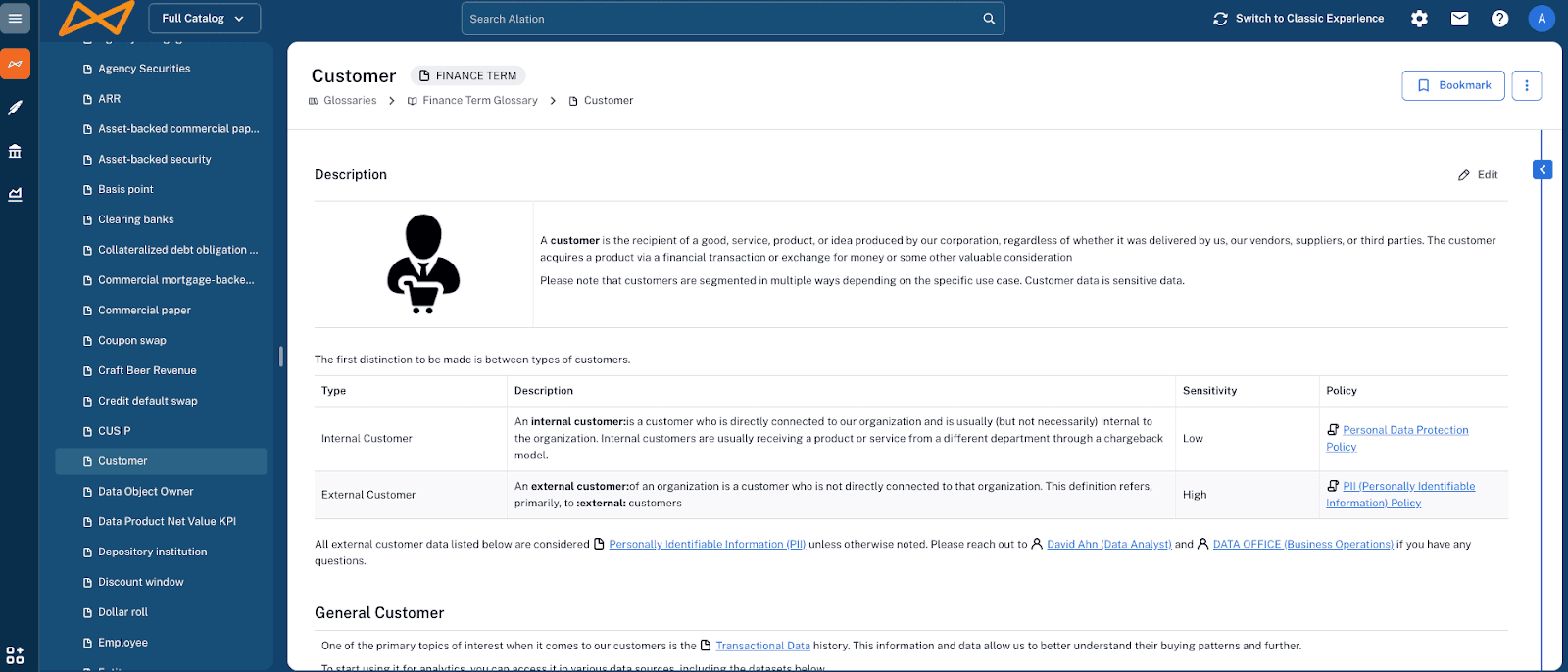
By aligning on the definitions of key terms like "customer" in a Business Glossary, businesses can ensure all teams are speaking the same language.
Examples:
Business glossary terms (e.g., Customer, Active Subscriber)
Metric/KPI definitions (e.g., Gross Margin, with calculation logic and exclusions)
Domain ownership and stewardship (e.g., “Marketing domain,” Owner = VP Growth)
Data product descriptions and service‑level objectives
Primary users: Business analysts, product owners, domain SMEs, stewards, and leaders consuming dashboards and models.
Questions it answers:
What does this term mean, and how is it calculated?
Who owns this metric or dataset, and how do I request access?
Which version is authoritative for a given decision or report?
Tips: Standardize your glossary schema and make ownership explicit. At minimum, capture these metadata elements for every term and KPI: definition, data elements used in the calculation, authoritative data repository/table, creation date, review cadence, permissions and rights management, and the responsible owner.
Publish business definitions to the catalog and expose them in BI tools and relevant web pages via APIs. Use approval workflows to review changes, and require owners to validate downstream impact before edits go live. This turns business metadata into a living contract between producers and data consumers.
Technical metadata
Purpose: Describe structure and processing in machine‑readable form.
Why it matters: Rich technical metadata shortens incident MTTR and enables optimization of queries and storage. It also powers safer data integration because schemas and contracts are explicit.
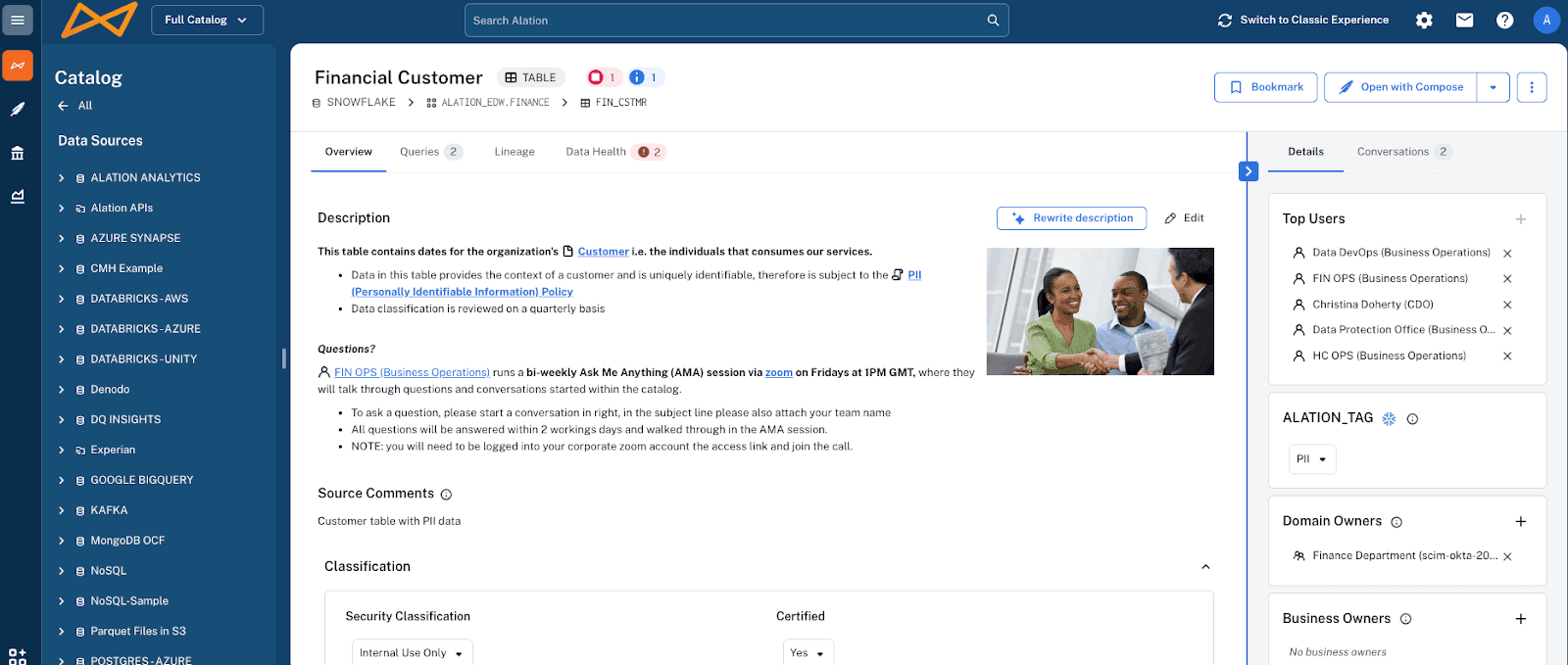
Examples:
Schemas, data types, constraints, partitions, file formats
Data lineage: column‑to‑column transformations across pipelines
Orchestration details: job names, dependencies, and schedules
Indexes, materializations, caching strategies
Primary users: Data engineers, analytics engineers, data scientists, platform teams.
Questions it answers:
Where did this column come from, and what transformed it?
How fresh is the table, how far back is history retained, and how expensive is it to query?
What are safe joins and known anti‑patterns?
Tips: Automate metadata management by harvesting schemas, file type, constraints, partitions, and lineage from warehouses/lakehouses, ETL/ELT tools, and notebooks into a central data repository. Capture structural metadata (keys, indexes, relationships) and column‑level lineage so teams can trace data structures end‑to‑end.
Turn on continuous scanners; parse SQL to infer joins and anti‑patterns; expose safe‑join guidance next to tables; and let ranking algorithms boost well‑documented, performant assets in search. Use change‑data‑capture to auto‑update lineage when pipelines evolve, and banner breaking changes where people query data.
Compliance metadata
Purpose: Encode regulatory and policy context so that safe behavior can be enforced and audited.
Why it matters: Strong, automated controls reduce exposure and speed audits. The average cost of a data breach reached $4.88M in 2024, so proactive governance is not optional (IBM, 2024).
Examples:
Data classifications (PII, PHI, PCI, confidential, public)
Applicable regulations (GDPR, CCPA/CPRA, HIPAA, SOX) and jurisdictions
Retention schedules and legal hold flags
Data handling instructions: masking rules, purpose limitations, consent state
Access policies and entitlements linked to roles/groups
Primary users: Privacy and compliance officers, security teams, data governance, and any analyst or engineer who touches regulated data.
Questions it answers:
Is this dataset subject to GDPR or sector‑specific controls?
What masking or tokenization is required in each environment?
Can this data be used for this purpose, and for how long?
Tips: Treat policy as code and link it to enforcement. Map classifications to access control rules, rights management, masking, and retention; record purpose limitations and consent; and make approvals auditable.
Express policies as templates (e.g., PII → mask by default; reveal by exception with ticket and time‑bound purpose). Connect the catalog to warehouses, BI, and notebooks so those policies apply wherever people use metadata and data.
Operational metadata
Purpose: Expose the runtime state and performance of data pipelines and products.
Why it matters: Reducing data downtime has material impact. Over 90% of mid‑size and large enterprises report that one hour of downtime now costs more than $300,000—and that excludes penalties (ITIC, 2024). Link incident data to lineage so owners can assess blast radius instantly (ITIC, 2024).
Examples:
Data freshness, latencies, and SLA adherence
Throughput, table volumes, file sizes, error rates, and incident tickets
Cost telemetry (warehouse credits, object storage, egress)
Environment and deployment history (version, commit, change requester)
Primary users: Platform engineering, SRE for data, analytics engineers, on‑call rotations, and product owners.
Questions it answers:
Did the pipeline meet its SLA today? If not, why and where?
How many rows changed, and is the variance within expected bounds?
What’s the cost profile of this dataset, and who’s consuming it?
Tips: Stream operational metadata from orchestrators and warehouses into the catalog: freshness, latency, row counts, error logs, and cost. Alert on anomalies and banner status on downstream assets.
Set SLOs for priority datasets (for example, “<30‑minute freshness during business hours”). Trigger runbooks automatically when thresholds breach, and pause dependent dashboards until status is green to protect trust and usability.
Behavioral metadata
Purpose: Capture how humans and systems actually use data so you can prioritize, promote, and protect what matters.
Why it matters: Surfacing the best option reduces rework and speeds data analytics. It also guides preservation metadata decisions by showing which digital assets merit long‑term care.
Examples:
Query and dashboard usage (views, unique users, dwell time)
Asset popularity, endorsements, comments, and request/approval flows
Query join graphs, filter patterns, and common paths
Agent and copilot interactions (prompts, retrieval sources, outcomes)
Data sharing events (exports, shares, embeds)
Primary users: Data product managers, governance leads, platform teams, enablement, and anyone deciding what to certify or retire.
Questions it answers:
Which datasets power the most critical decisions and AI use cases?
Who are the top consumers and subject‑matter experts for this domain?
Where should we focus documentation, tests, and incident response?
Tips: Operationalize behavioral metadata into a transparent trust model. Combine popularity, reliability, certification, and business impact to compute a trust score; boost trusted assets in ranking; and flag redundancies.
Show “Why this is trusted” explanations; auto‑suggest canonical joins based on real query patterns; and route new analyses to certified sources by default. Deprecate low‑use, low‑trust copies to streamline your catalog and prevent silos.

How classical metadata categories map to enterprise practice
Many teams ask how library‑science categories fit modern practice. Here is a quick mapping you can apply across repositories and tools:
Descriptive metadata: Titles, summaries, keywords, and Dublin Core elements (creator, subject, creation date). In practice, this fuels search in catalogs and internal search engines, improves data discovery, and clarifies context on dashboards and web pages.
Structural metadata: How parts relate—schemas, relationships, partitions, and a table of contents for a digital file or dashboard. This helps systems assemble composite data assets and helps people navigate complex reports.
Administrative metadata: Stewardship, permissions, rights management, formats/file type, and lifecycle. This enables governance, compliance, and data security across different systems.
Preservation metadata: Fixity checks, archival plans, and retention decisions to ensure long‑term integrity and optimization of storage tiers.
Provenance metadata: Source systems and transformation history—the enterprise counterpart to academic citations—which supports audit, decision‑making, and reproducibility.
Together with the business/technical/compliance/operational/behavioral model above, these different types of metadata give you a complete toolkit for categorizing and governing enterprise data.
The value of combining metadata types in a data catalog
Housing these types in a single catalog (AKA a metadata management platform) multiplies value by providing:
Shared meaning: Link business glossary terms and KPI logic directly to technical tables and semantic models so engineers build to the same definitions leaders consume.
Governance that enforces itself: Tie classifications to access policies so rules follow data across tools and environments.
Faster ops: Overlay operational status on lineage so you instantly see which reports and models are affected by a failing job.
Safer AI: Use compliance and business context to constrain prompts, ground retrieval, and log decisions for audit.
Think of the catalog as a knowledge graph of your enterprise data. Nodes (terms, datasets, dashboards, models, policies, people) are connected by typed relationships (derives‑from, calculates, owned‑by, governed‑by). Once the graph exists, you can answer high‑value questions programmatically: “Show me all certified customer churn features used in production models where data is fresh within 24 hours and does not include EU personal data.”
Activating (operationalizing) your metadata
Metadata only creates value when it changes behavior—of people and of systems. Activation means pushing the right context into the right moment and automating the right control or suggestion.
Use AI to automate metadata curation
What to automate:
Extraction: Summarize schemas and queries into human‑readable descriptions; infer business terms from column names and sample values.
Classification: Auto‑tag PII/PHI with entity recognition; detect sensitive free text; classify domains and data products.
Lineage inference: Reconstruct column‑level lineage from SQL and notebook code—even across heterogeneous systems.
Deduplication & normalization: Cluster near‑duplicate assets and align synonyms (e.g., Cust_ID, CustomerKey).
Quality detection: Flag anomalies in distributions, null rates, and freshness; propose tests.
Human‑in‑the‑loop: Keep stewards and owners in the approval loop. Present AI suggestions with confidence scores, allow bulk acceptance, and require review on high‑risk changes (e.g., reclassifying PII).
Guardrails: Log training data sources for transparency, restrict model access to regulated content, and version auto‑generated metadata for rollback.
Leverage usage analytics: identifying high‑value datasets and surfacing trusted assets
Usage analytics turns behavioral metadata into decisions about trust and investment. Implement a trust scoring model that ranks assets and steers users toward the best choice.
Metadata usage signals:
Popularity: unique users, recurring usage, cross‑team adoption
Freshness & reliability: SLA attainment, days since last failure, incident count
Quality evidence: validation tests, schema stability, distribution drift
Endorsement: certifications, owner responsiveness, SME comments
Business impact: linked KPIs, OKRs, or decisions; model feature usage
Cost efficiency: query cost per use; storage growth vs. consumption
Example trust score (illustrative):
Trust = 0.25*Popularity + 0.2*Reliability + 0.2*Quality + 0.2*Endorsement + 0.1*BusinessImpact + 0.05*CostEfficiency
Use the score to:
Badge and boost: show “Trusted” or “Certified” labels; boost in search ranking.
Auto‑route requests: default new analyses to trusted sources; warn on low‑trust assets.
Drive lifecycle: promote to canonical, or target for deprecation/merge.
Finally, leverage dashboards that explain trust: Pair the score with explainability (“Why is this trusted?”) so users learn and adjust behavior.
Approach metadata taxonomy design thoughtfully
A taxonomy is the scaffolding that makes metadata usable. Poorly designed taxonomies bury meaning under jargon; good ones map to how people search and work.
A pragmatic methodology:
Clarify goals and personas. What tasks must the taxonomy support? (e.g., “Find a certified revenue table for EMEA within 24h freshness.”)
Inventory & normalize. Collect existing tags, labels, and glossaries. Collapse duplicates and define canonical terms.
Model facets, not a single tree. Prefer a faceted taxonomy over deep hierarchies. Typical facets: domain, data product, sensitivity, lifecycle (draft → production → deprecated), geography, system, freshness tier, SLA, certification state.
Define required vs. optional fields. Keep the required set small (e.g., Owner, Domain, Sensitivity, Lifecycle, Description). Add optional fields for teams that need more control.
Establish naming conventions. Examples: kebab‑case for technical names; Title Case for business terms; prefix environments (prod_, stg_). Ban ambiguous prefixes.
Govern change. Create a lightweight review board and change log. Batch changes and communicate releases.
Seed and iterate. Auto‑tag where possible, then host short tagging sprints with SMEs. Measure findability and adjust.
Anti‑patterns to avoid: too many required fields, free‑text tags without standards, overlapping categories, and hidden ownership.
Deliverables to produce: a one‑page taxonomy spec, examples of “good” vs. “bad” asset pages, and a starter set of controlled vocabularies.
Common metadata standards in business: Common Warehouse Model (CWM) and Data Catalog Vocabulary (DCAT)
Standards improve interoperability across tools and organizations. Two that matter in 2026 are CWM and DCAT.
Common Warehouse Model (CWM)
CWM, from the Object Management Group (OMG), provides a meta‑model for data warehousing, describing sources, transformations, and storage. It’s especially useful when integrating heterogeneous BI and ETL tools or documenting warehouse design in a vendor‑neutral way.
Key benefits of the CWM:
Interoperability: Share warehouse designs between tools that understand CWM.
End‑to‑end visibility: Model source‑to‑target mappings and transformations.
Consistency: Apply a standardized vocabulary for dimensions, facts, and processes.
Practical tip: Even if your tools don’t speak CWM natively, map key concepts (dimensions, facts, transformations) into your catalog so teams can reason consistently about complex pipelines.
Data Catalog Vocabulary (DCAT)
DCAT is a W3C standard for describing datasets and catalogs to enable discovery and reuse, particularly across open data ecosystems and government portals. DCAT’s linked‑data roots make it a good fit for publishing and consuming data across organizational boundaries.
Key benefits of the DCAT:
Semantic consistency: Shared classes and properties for datasets, distributions, and catalogs.
Discoverability: Searchable, machine‑readable metadata that improves reuse.
Portability: Easier federation among agencies, partners, and platforms.
Practical tip: Use DCAT when publishing or integrating with external catalogs. Inside the enterprise, align your internal schema to DCAT concepts to simplify exchange.
Metadata in cloud computing: ensuring data accessibility and scalability
In cloud and lakehouse architectures, metadata is how you keep scale, cost, and security in balance.
Make storage smart with metadata:
Tag objects and tables with ownership, sensitivity, and lifecycle to drive automated retention and tiering (hot, warm, cold).
Use table formats (e.g., Delta/Apache Iceberg) that persist schema and transaction metadata for ACID operations and time travel.
Apply data locality and residency tags to route processing to compliant regions.
Enforce least privilege at scale:
Bind classifications to policy‑based access controls (row/column level) and dynamic masking rules.
Connect the catalog to your IAM/entitlement system so access requests are auditable and reversible.
Control cost and performance:
Record query cost and cache hit ratios as operational metadata. Expose them in the catalog so teams can pick efficient datasets.
Use freshness tiers (e.g., bronze/silver/gold with explicit SLAs) so users trade accuracy for latency intentionally.
Resilience and portability:
Version schemas and contracts. Treat schema changes as breaking/compatible with automated diffs and approvals.
Capture deployment metadata (commit IDs, approvers) to speed rollback and post‑incident analysis.
What’s more, metadata is an invaluable asset to inform successful cloud migrations. Learn more about how a metadata-driven migration can save time and reduce costs.
Metadata for machine learning and AI: boosting automation
ML and AI amplify both the value and the risk of metadata. Here are some best practices for metadata management when it comes to ML and AI.
For traditional ML:
Track dataset versions, feature lineage, and training/validation splits to ensure reproducibility.
Manage feature stores with owners, freshness, and drift monitors. Link features to the business KPIs they move.
Record experiment metadata (hyperparameters, code version, environment, seeds) and model cards (intended use, limitations).
For LLMs and agents:
Maintain corpus metadata: source systems, recency, sensitivity, and copyright status. Tie to retrieval policies (what can be used for grounding and by whom).
Store chunk‑level attributes (document section, author, date, privacy) to improve retrieval quality and safe citations.
Capture interaction metadata (prompt templates, tools used, fallbacks, human feedback) for auditability and continuous improvement.
Apply guardrail metadata: allowable use cases, prohibited topics, and redaction requirements.
With the right metadata, you can answer: Which features powered last quarter’s churn lift? or Which documents trained or grounded this agent’s decision, and were they permitted?—and then you can act on the answer.
As Raza Habib, CEO of Humanloop, explains, good metadata practices are not just about regulatory pressure—they’re critical for building resilient AI systems:
“The EU AI Act is going to force people, especially those working on high-risk applications, to be able to show that they used data sets that had been checked for quality and bias, that they had good record keeping of their decisions, and that they have a risk management system in place. But for me, it’s also about making it easy for teams to track the history of what they did—the decisions they made, the data they used—so everything is repeatable. If you need to go back and audit a system, you can answer: why did we change that prompt, what evaluation was running, who did it, and what data trained it?”
Habib argues that tracking datasets, versioning prompts, and logging evaluations aren’t just compliance safeguards—they’re best practices that improve product quality:
“If you have a repeatable pipeline for evaluation, then you can answer the question of: compared to three months ago, did we actually make the system better? Governance around LLM Ops—tracking datasets, versioning prompts, maintaining observability—helps you respond when something goes wrong and, more importantly, build better features.”
By embedding these metadata best practices into ML and AI workflows, organizations can meet regulatory requirements while also accelerating innovation and improving system reliability.
Generate measurable business value from your metadata
To realize outcomes, tie metadata management to a few headline metrics and embed metadata into daily workflows. Focus on time‑to‑insight (how quickly users find and trust relevant information), data downtime, adoption of certified assets, and audit readiness. As the Global DataSphere accelerates—IDC estimated 129 zettabytes created in 2023 and more than double by 2027—automation and clear ownership become mandatory, not optional (IDC forecast via AWS, 2024).
Make value tangible: surface freshness and quality banners directly in BI; prioritize high‑trust datasets in search; and retire duplicates to streamline the catalog. Publish a simple monthly scorecard and celebrate teams that improve data quality and reduce incidents. When leaders can see faster analyses, fewer outages, and easier audits, support for investment compounds.
Ready to turn metadata into measurable outcomes? Book a demo to see how a modern data catalog activates metadata across your stack—so people, processes, and AI work from the same, trusted foundation.

- Key takeaways
- Key metadata types, examples, and users
- The value of combining metadata types in a data catalog
- Activating (operationalizing) your metadata
- Common metadata standards in business: Common Warehouse Model (CWM) and Data Catalog Vocabulary (DCAT)
- Metadata in cloud computing: ensuring data accessibility and scalability
- Metadata for machine learning and AI: boosting automation
- Generate measurable business value from your metadata
Contents
Tagged with
Loading...