The First Pillar of Data Culture: Data Search & Discovery

By Aaron Kalb
Published on June 9, 2021

According to a recent survey by Alation, 78% of enterprises have a strategic initiative to become more data-driven in their decision making. According to Gartner, data culture is a top priority for chief data officers (CDOs) and chief data & analytics officers (CDAOs). In this four-part blog series on data culture, we’re exploring what a data culture is and the benefits of building one, and then drilling down to explore each of the three pillars of data culture – data search & discovery, data literacy, and data governance – in more depth.
This post focuses on the role of data search & discovery within a data culture. The first post in the series defines data culture, its benefits, and the three pillars of a data culture. The third and fourth posts take a deeper look at data literacy and data governance respectively.
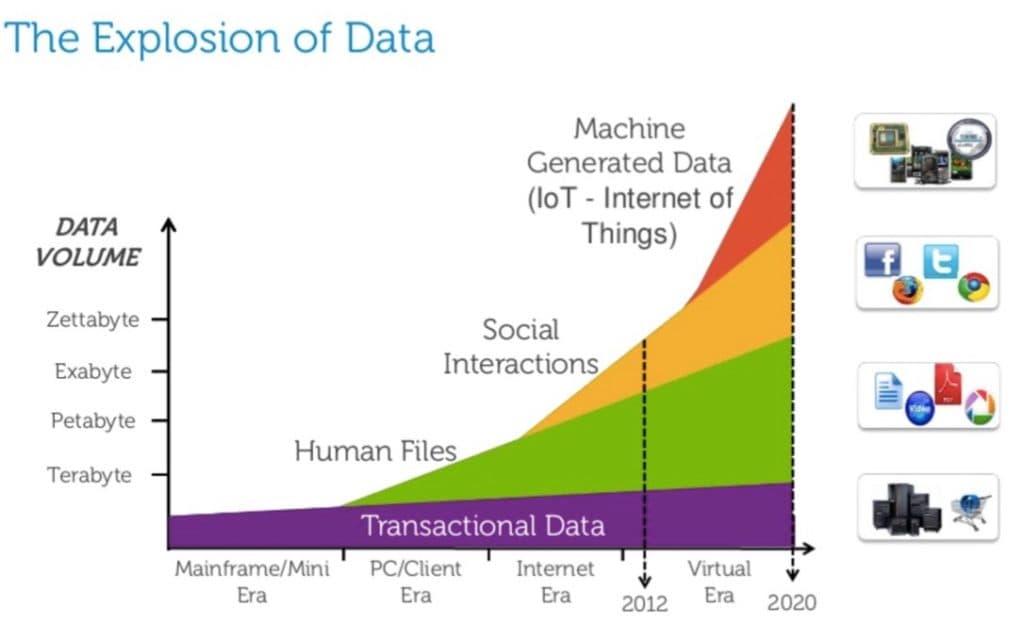
What is Data Search & Discovery?
According to IDC, more than 59 zettabytes (59,000,000,000,000,000,000,000 bytes) of data was created, captured, and consumed in the world in 2020. We have an explosion, not only in the raw amount of data, but in the types of database systems for storing it (db-engines.com ranks over 340) and architectures for managing it (from operational datastores to data lakes to cloud data warehouses). It’s almost quaint to think that 20 years ago, organizations generally didn’t have enough data to perform desired analyses. Today they have too much. Organizations are drowning in a deluge of data.
What’s more, business intelligence (BI), once thought to be the solution, has become part of the problem. In addition to an exploding amount of raw data, we now have an explosion in BI artifacts – reports, dashboards, and visualizations – that may provide information seekers with accurate answers… or may just confuse or mislead them. BI artifacts must therefore be treated as information assets in their own right.
If yesterday’s question was, “do we have the data?” today’s is “how do I find the data?”. Moreover, given that the desired data likely exists in multiple systems and forms, the question becomes, “of the many sources available, how do I find the best one?”.
Data search & discovery is a capability that enables users to find, understand, and trust the information they need to make data-driven decisions. Data search & discovery is the foundational pillar of data culture; it doesn’t matter whether data governance is in place or how data literate employees are, if people cannot find the data they need.
Data search & discovery should be defined broadly: helping users find not just raw data (e.g. in databases), but also a wide range of other information assets, including unstructured information, BI artifacts, text documents, etc., and going beyond simply finding information to include both understanding and trusting it.
Understanding data refers to learning more about the data asset (e.g., what does it look like? What does it mean? Where did it come from? Who stewards it? Who else uses it? What data do people typically combine it with?).
Trusting data means knowing whether and how a given data asset can be used (e.g., is it high quality/accurate/up-to-date? Do other people use it? Am I allowed to use it? What policies should I be aware of when using it?). While data search & discovery may have started out focused simply on finding data, people quickly realized that—much as with BI where questions beget questions—finding data begets questions about that data. A good search & discovery capability enables people to answer those questions.
Social Signals in Search Result Ranking
Early search engines indexed the internet, making it possible to instantly find (i.e. to “recall”) all webpages containing a given keyword. The problem was, people didn’t want millions of pages—they wanted the single page which best answered their question. Ranking is critical.
Early search engines ranked results solely based on page content. They used techniques like TF-IDF, which prioritizes pages that disproportionately contain the search terms. So if the term “information retrieval” occurs once every million words in the internet as a whole, but appears 25 times in a 300-word blog post, then that blog appears to be about (or at least highly relevant to) information retrieval.
But such a technique doesn’t ensure that the top hits are the best—i.e. informative and trustworthy. In fact, early spammers figured out that by “keyword stuffing” (repeating a keyword ad nauseum in their pages), they could promote their content, however crappy it might be.
Google solved search with PageRank. Instead of just counting words on a given page, Google counted how many other pages (especially reputable ones) linked to that page. Since the human beings generating web content typically only add links to pages they believe to be useful & reliable, those social signals are superior indicators of quality and utility.
Data search is hard because datasets aren’t self-describing the way webpages are. Suppose I were a data analyst looking for data on the shopping habits of young British women. The best dataset might not contain “young”, “British”, or “women” at all; rather it might have a column with dates of birth, a gender field set to “M” or “F”, and a column called cntry_cd (meaning “country code”), which I’d want to filter to “UK.” So sophisticated algorithms and/or user training is required to get even basic recall to work.
But it turns out that good ranking for datasets can be achieved analogously to PageRank—by looking not at the dataset itself, but at the indicators people leave behind, which tell us clues about the data. Where Google looked at links, Alation looks at logs—using machine-learning in its behavioral analysis engine to bring the useful and relevant datasets to the top of the search results page in its data catalog.
User Classes and the Virtuous Cycle of Adoption
Today data search & discovery solutions serve analytical end-users, as well as data governance use cases. Those end-users comprise three primary classes:
Data scientists, typically trying to locate raw datasets for modeling, advanced analytics, and data products,
Business analysts, generally aiming to locate datasets or existing BI artifacts and collaborate around them., and
Business users, often seeking to find existing BI artifacts to answer questions of interest.
With each new class of end-users, the potential for usage within an organization expands 10-100x.
Usage is critical within data search & discovery systems because such systems benefit from a virtuous cycle, or flywheel effect:
The more people use the system, the better it gets, both because they contribute knowledge and since their usage patterns leave behind hints about relevance.
The better the system gets, the more people use it, because the increased quality of the content and search results attracts new users.
Once the flywheel has momentum, the dynamic gets better and better. But there are two dangers you should plan for:
Problem #1: the flywheel never starts moving. Solution: Develop a rollout plan for any data search & discovery initiative, which seeds the virtuous cycle and bootstraps early adoption.
Problem #2: the flywheel has friction and gets stuck. Solution: Select data search & discovery software with a slick, high-quality, consumer-grade user experience. Be wary of systems built for IT or data governance audiences, as these tend to have clunky interfaces optimized for policy-makers at the expense of the far more plentiful information seekers.
Data search & discovery systems are also leveraged for data governance to ensure proper management of data and compliance with policies. For instance, someone in charge of Data Privacy might want to find all instances of phone number data to label them as PII (Personally Identifiable Information). This is a use case where complete recall—of all matches—is essential, not just a relevant “top result”. The best data search & discovery systems will serve all the aforementioned audiences. While a system purpose-built for data governance tends to frustrate analytical end-users, a system built for information seekers can delight and empower data governance teams
The Role of Data Catalogs in Data Search & Discovery
Alation invented the modern data catalog and pioneered the use of machine-learning-based search relevancy. Data catalogs were effectively invented as data search & discovery tools. Over time, and in response to customer feedback, data catalogs evolved to support broader classes of users. Today data catalogs are evolving into data intelligence platforms suitable for supporting a broad range of applications, including data search & discovery, data governance, cloud data migration, digital transformation and many others. Data intelligence is a key to building a data culture in the same way that CRM is a key to building customer intimacy.
In the next post in this series, we’ll discuss the second pillar of data culture, data literacy.
- What is Data Search & Discovery?
- Social Signals in Search Result Ranking
- User Classes and the Virtuous Cycle of Adoption
- The Role of Data Catalogs in Data Search & Discovery
Contents
Tagged with
Loading...