
For organizations aiming to surge ahead in an AI-driven economy, the modern data stack is no longer optional—it’s foundational. Whether you’re a data leader evaluating infrastructure or a business executive asking how to accelerate AI initiatives, this guide offers a clear, strategic explanation of the modern data stack with particular attention to how it enables AI.
Key Takeaways
Organizations are shifting from legacy on-premises systems to modern, flexible, cloud-native stacks that support AI and decentralized workflows.
Modern data stacks enable faster insights and greater agility, thanks to real-time access, self-service tooling, and scalable architectures.
By democratizing access to high-quality data, improving governance, and accelerating data product creation, modern data stacks empower organizations of all sizes to deliver measurable business value.
What is a modern data stack?
A modern data stack is a thoughtfully assembled collection of cloud-native tools, processes, and architecture that enables enterprises to ingest, store, transform, and analyze data with agility, scale, and governance.
In practice, the modern data stack enables organizations to move beyond “data warehousing + BI” to a platform that supports self-service analytics, AI/ML pipelines, and enterprise-wide data products. It aligns infrastructure with business agility—letting teams explore, deliver, and iterate on data assets without legacy bottlenecks. As articulated by vendors and practitioners, this stack addresses the “inedible to edible” data journey—raw data becomes actionable insight.
At Alation, we view the modern data stack as enabling three things simultaneously: visibility (through metadata and discovery), agility (through interoperable tooling), and trust (through governance and lineage). These three pillars allow organizations to scale data for AI and deliver the data products that drive business outcomes.
Components of a modern data stack
A typical modern data stack consists of the following core components:
Extract, Load, Transform (ELT) tools
Data ingestion/integration services
A data warehouse, data lake, or data lakehouse
Data orchestration tools
Business intelligence (BI) platforms
Reverse ETL tools
These tools are used to manage big data for enterprises. [make this definition more authoritative] Big data is typically defined as data that is too large or complex to be processed by traditional means, which means you need specialized tools and infrastructures to build your own data stack.
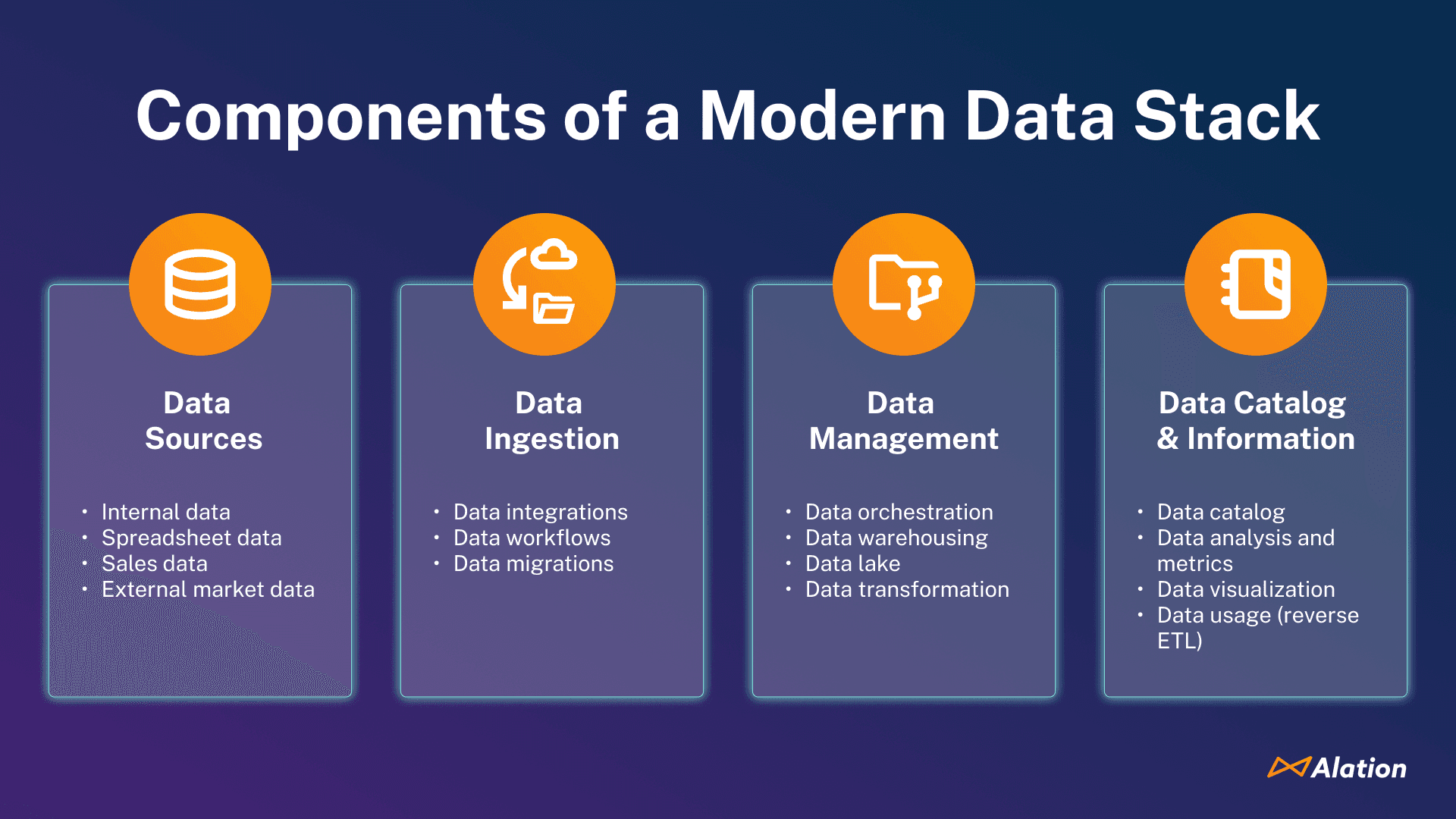
Components of a modern data stack.
What is a modern data stack for AI?
A modern data stack for AI is a cloud-native data infrastructure designed so that AI models, copilots, and autonomous agents can retrieve, understand, and act on enterprise data with accuracy, governance, and a full audit trail.
It still includes everything a modern data architecture has always needed — ingestion, cloud storage, transformation, orchestration, and analytics. What makes it for AI is the layer that sits on top: the context layer that encodes what your data means, how concepts relate, and what an AI system is allowed to do with them.
Put simply: a traditional stack makes data available. A modern data stack for AI makes data understandable and actionable to machines — which is a much higher bar, because an AI agent has none of the institutional knowledge a human analyst uses to silently correct for ambiguity.
At Alation, we view the modern data stack as enabling three things simultaneously: visibility (through metadata and discovery), agility (through interoperable tooling), and trust (through governance and lineage). For AI, a fourth requirement joins them: context — the meaning and judgment that lets agents act, not just retrieve.
How a modern data stack for AI differs from a traditional analytics stack
Three years ago, "modern data stack" meant a cloud warehouse, an ELT pipeline, a transformation tool, and a BI layer. That combination was genuinely transformative for analytics teams — and for descriptive reporting, it still works well.
But AI changed the requirements. When a platform exists only to answer historical questions — what happened, how much, how often — a clean analytics stack is sufficient. The moment the platform has to power recommendations, detect anomalies in real time, or let an agent execute a multi-step workflow, the architecture has to evolve.
Dimension | Traditional analytics stack | Modern data stack for AI |
Primary consumer | Human analysts via dashboards | LLMs, copilots, and autonomous agents |
Core question | "What happened?" | "What should we do, and can we prove why?" |
Data shape | Structured, batch, historical | Structured + unstructured, often real-time |
What it standardizes | Metric calculations | Metrics plus meaning, relationships, and policy |
Failure mode | A wrong number on a dashboard | A confidently wrong action, taken at scale |
Governance model | Review at deployment, then spot-check | Continuous feedback loop on every interaction |
Decisive layer | BI / semantic metrics | Context layer (semantic → ontology → ECL) |
The trap most enterprises fall into is running AI workloads on infrastructure designed for reporting — then wondering why the agent gives plausible, polished, wrong answers.
What are the components of a modern data stack for AI?
A modern data stack for AI has two tiers: the foundation (the data plumbing) and the context layer (what makes it AI-ready).
Foundation — the data plumbing:
Extract, Load, Transform (ELT) and data ingestion / integration services
A data warehouse, data lake, or data lakehouse
Data orchestration tools
Business intelligence (BI) and analytics platforms
Reverse ETL tools
Context layer — what makes it AI-ready:
A semantic layer that standardizes how metrics are calculated and named
An ontology that encodes what entities are and how they relate
An Enterprise Context Layer (ECL) that supplies the policy and judgment an agent needs to act
A governance feedback loop — glossaries, lineage, data quality monitoring, and automated correction — that keeps all of the above current
The foundation is necessary but not sufficient. You can have flawless pipelines and a pristine warehouse and still get unreliable AI, because the model doesn't know that your fiscal year ends in September or that your definition of "active customer" changed twice last quarter. That knowledge lives in the context layer.
How has the modern data stack evolved into an AI stack?
The stack has transformed over 15 years, driven by cloud computing, changing workflows, and exploding data volumes — and most recently, by AI's far higher demands on context.
Early 2010s: Cloud data warehouses emerge. BigQuery, Amazon Redshift, and Snowflake introduce scalable cloud storage; organizations discover the cost ceiling of on-premises infrastructure.
Mid-2010s: The ELT revolution. The industry shifts from Extract, Transform, Load (ETL) to Extract, Load, Transform (ELT) — load raw data first, transform as needed. BI tools like Looker and Tableau gain wide adoption.
Late 2010s: Integration and ecosystem growth. Ingestion tools like Stitch and Fivetran provide seamless connections; alternative stores (MongoDB, Cassandra, Elasticsearch) mature the ecosystem.
Early 2020s: Democratization and real-time. Demand for access drives cloud migration; agile analytics and vendor flexibility become standard; real-time processing expands.
2025–2026: AI-first and context-driven. The stack becomes the backbone of enterprise AI. Data products emerge as the unit of value, and the context layer — semantics, ontology, and policy — becomes the decisive differentiator between a stack that reports and a stack that can act.
The shift from ETL to ELT let analysts extract insights faster. The shift now underway — from ELT to context-aware data — is what lets AI agents act safely.
How does a modern data stack power AI and machine learning?
A modern data stack is the backbone of AI and machine learning because these technologies are only as good as the data and context behind them. The stack supplies four things AI can't function without:
Scale and speed. Cloud elasticity manages large volumes efficiently, and real-time processing feeds latency-sensitive use cases like fraud detection, personalization, and predictive maintenance.
Quality and governance. High data quality and active governance lead to more accurate predictions and faster, safer integration of new sources.
Context. The semantic, ontological, and policy meaning that lets a model interpret data the way your best employee would.
Auditability. A decision trace — what data the agent saw, what policy governed it, what it did — captured at runtime, not reconstructed after the fact.
How the modern data stack powers data products for AI
One of the most significant developments of 2026 is data products as the framework for delivering AI-ready value — and data products and the semantic layer are inseparable in practice.
A data product is a governed, trusted, reusable data asset built for consumption. A well-built one is effectively an integrated semantic layer: it bundles the metric definitions, certified sources, and shared vocabulary that make data trustworthy across teams. If the semantic layer underneath is inconsistent, the data product inherits that inconsistency and distributes it at scale — to every agent that consumes it.
The modern data stack supports a data product operating model through accessibility (self-service discovery), reliability (automated pipelines and quality monitoring), actionability (insight that informs the next step), and scalability (elastic growth from one team to the enterprise). Organizations pairing data product thinking with their stack report measurable wins — reduced churn via real-time risk scores, optimized supply chains via predictive inventory, and faster time-to-market via instant access to behavioral analytics.

Modern data stack vs. legacy data stack
Understanding the contrast clarifies the value of modernization for AI:
Architecture: A modern stack runs on cloud computing; a legacy stack stores data on servers. Modern stacks are more scalable, flexible, and efficient. Legacy stacks usually mean traditional RDBMS using SQL.
Accessibility: A modern stack democratizes data across the organization; legacy systems create IT bottlenecks.
Flexibility: Modern stacks let tools be mixed and matched with consumption-based pricing and no vendor lock-in.
An RDBMS can still play a role, and SQL remains a popular query language across both — but legacy architectures rarely supply the scale, real-time access, or context AI workloads require.
What are the benefits of a modern data stack for AI?
1. Scalability that keeps pace with AI workloads
Cloud elasticity lets you scale compute up for heavy AI jobs and back down to control cost. At Spark New Zealand, migrating to a cloud-based stack powered by Snowflake and Alation let the company scale analytics seamlessly — with over 900 machine learning features cataloged, more than 200 users accessing Snowflake via Alation, and Power BI report creation accelerated by 30%.
2. Flexibility and agility without lock-in
Tools can be added or removed as needs change. RaceTrac built a lakehouse on Azure and Databricks, using Alation to connect and govern data across its ecosystem — reducing redundant datasets by 65% (from 725 to 250) and reacting "at the speed of business" without vendor lock-in.
3. Efficiency that compresses time-to-insight
Cloud-native tools designed to work together save time and broaden access. At Discover Financial Services, integrating the Alation data catalog into analytics workflows cut data pipeline creation from 30 days to two — a foundation that directly accelerates AI experimentation.
4. A data culture that makes AI adoption stick
Usable tools strengthen data culture across search and discovery, data literacy, and governance. Digital-only GXS Bank has nearly 300 employees using Alation daily — 5,000+ searches and 3,000 SQL queries through the catalog — turning an entangled ecosystem into a harmonized, AI-ready one.
For a sector-by-sector look across healthcare, financial services, and the public sector, see our industry deep dive.
How do you build a modern data stack for AI?
The market trains organizations to choose technology first and define outcomes second. That sequence is backward. Start with the outcome, then build the layer that delivers it.
Step 1: Name the business problem before the technology
Three diagnostic questions guide the sequence:
Where does our data break down most often? If different teams get different numbers for the same question, your first investment is the semantic layer.
Where do our AI systems make factually wrong inferences? If agents fail because they don't understand domain relationships or operational sequences, you need an ontology.
Where do our agents fail on complex, multi-step workflows? If agents can't handle the judgment, policy, and situational dimensions of a decision — or you can't audit their reasoning — you need an Enterprise Context Layer.
Step 2: Assess the foundation you actually have
Before any layer, take an honest inventory. Is your underlying data trusted, cataloged, and governed? Do you have business glossaries the organization has actually agreed on? Do you have data lineage visibility? Do you have a mechanism to capture agent errors and feed corrections back? If the answer is no, the most important investment is foundational governance — not an ontology or an ECL.
Step 3: Deploy the foundation (warehouse, ingestion, transformation, BI)
Choose a cloud data warehouse or lakehouse sized to your data (Snowflake, BigQuery, Redshift, Databricks). Connect sources with ingestion tools like Fivetran, Airbyte, or Stitch. Clean and model with a transformation tool such as dbt. Add BI for human consumers and reverse ETL (Hightouch, Census) to push data back into operational apps. Pair all of it with a data catalog as the metadata backbone.
Step 4: Build the context layer
Layer the semantic definitions, ontology, and ECL on top of the governed foundation — in the sequence your maturity demands (see the table below). This is what turns an analytics stack into a modern data stack for AI.
Step 5: Build the feedback loop in from the start
The most common reason expensive data initiatives fail isn't technical — it's that context drifts as the business changes and nothing keeps it current. Every layer needs a governance feedback loop: when a metric definition changes, who owns the update and how fast does it propagate? When a policy changes or an agent surfaces an error, does that signal flow automatically back into the catalog, ontology, and ECL — or sit in a ticket queue? An ECL without automated feedback requires a permanent maintenance team. An ECL with it compounds accuracy over time.
Step 6: Enable the organization
Train teams, document the stack, and create champions. The stack only delivers value when people — and now agents — actually use it.
How to sequence the investment by AI maturity
The right first investment depends on where you are, not where you want to be:
AI maturity stage | Primary investment | Business outcome target |
Descriptive analytics & BI | Semantic layer | Consistent metrics; fewer reporting disputes; faster decisions |
Predictive models & rule-based automation | Ontology | Compressed decision latency; reasoning over complex domains |
Autonomous agents & agentic workflows | Enterprise Context Layer + governance | Scalable judgment; auditable, policy-compliant AI at scale |
Governance: the foundation that keeps an AI data stack trustworthy
All three context layers can decay. The semantic layer drifts when definitions change and tables aren't updated. The ontology goes stale when processes evolve faster than the model. The ECL degrades every time a policy changes or a table is deprecated, and nobody updates the context.
The most dangerous governance model for agentic AI is the checkpoint model — review before deployment, then monitor intermittently. With agents making decisions at scale, by the time a checkpoint catches a problem, it has already propagated through thousands of decisions. The right model treats governance as a continuous feedback loop, where the governance infrastructure does four things:
Provides authoritative vocabulary — business glossaries of agreed definitions (Customer, Product, Revenue, Active) that ontology builders draw from and ECL systems reference.
Maps the landscape — automated data lineage tracing how data flows and transforms across systems.
Establishes trust signals — data quality monitoring and certification that validate freshness and conformance before any agent consumes the data.
Closes the feedback loop — mechanisms that capture agent errors and corrections automatically and flow them back into the catalog, ontology, and ECL.
This is where cumulative accuracy comes from. Each feedback cycle doesn't just fix an error; it adds to a growing body of institutional knowledge about how your business actually works — making each successive AI use case less risky than the last. That's the real goal of AI transformation: not more output faster, but a system where every agent interaction makes the next decision more accurate, more governed, and more defensible.
What challenges come with adopting a modern data stack for AI?
Tool sprawl. Specialized tools accumulate fast. Set evaluation criteria, favor multi-capability platforms, and use a data catalog as the central inventory.
High and unpredictable costs. Consumption pricing surprises teams as volumes grow. Implement cost monitoring, automated scaling, and data lifecycle policies early.
Talent gaps. Modern stacks need specialized skills. Upskill existing staff, create learning paths, and choose tools with strong documentation and intuitive interfaces.
Governance gaps. Flexibility without controls risks quality, security, and compliance failures — magnified when agents act on the data. Implement a catalog early, define ownership, and build lineage and feedback in from the start.
Slow adoption. Involve end users in selection, create departmental champions, demonstrate quick wins, and make the new stack genuinely easier than the legacy one.
Who needs a modern data stack for AI?
Any organization deploying AI on enterprise data benefits — but it's essential for those with multiple data teams, regulated data, or autonomous agents in production. Beneficiaries include data and business analysts, data scientists, software and cloud engineers, data engineers, and the business leaders who depend on AI outputs to make decisions. Increasingly, even small and mid-sized businesses manage data landscapes large enough — and AI ambitions serious enough — to justify the investment.
Getting started with a modern data stack for AI
The market will keep selling you technology. Your job as a leader is to anchor every technology conversation in a specific business outcome — not "we need a semantic layer" but "we need reporting arguments to stop so leadership decides faster"; not "we need an ECL" but "we need our agents to act with the judgment and policy awareness of our best employees, at scale, with a full audit trail."
Then work backward: from the outcome, to the layer that addresses it, to the governance that keeps it current, to the organizational alignment that makes it real. Many successful organizations start with a single high-value use case, prove value, and expand.
Start with the outcome. Build the layer. Govern the system. That's how a modern data stack for AI becomes business value rather than technology theater.
Curious how a data catalog and active governance can anchor your modern data stack for AI? Book a demo to see for yourself.
FAQs
What is a modern data stack for AI? A modern data stack for AI is a cloud-native data infrastructure that lets AI models and agents retrieve, understand, and act on enterprise data accurately and with governance. It extends the traditional analytics stack (ingestion, storage, transformation, BI) with a context layer — semantic definitions, an ontology, and an Enterprise Context Layer — plus a governance feedback loop that keeps that context current.
How is a modern data stack for AI different from a regular modern data stack? A regular modern data stack is optimized for human analysts answering historical questions through dashboards. A modern data stack for AI adds the meaning, relationships, and policy context that machines need to act — because an AI agent lacks the institutional knowledge a human uses to silently correct for ambiguous or inconsistent data.
What is a semantic layer, and why does AI need one? A semantic layer standardizes how business metrics are calculated and named so a request like "Q3 revenue by region" means the same thing everywhere. AI needs it because, without one trustworthy definition per metric, an agent will confidently pick the wrong one and present the result as fact.
Why do AI initiatives fail on a traditional data stack? They fail on context, not compute. A generic AI assistant pointed at ungoverned data returns confident answers from the wrong source, definition, or population — for example, calculating a "full year" on a December fiscal year when the company's year ends in September. The semantic layer, ontology, and ECL exist to prevent exactly these failures.
How do you build a modern data stack for AI? Start with the business outcome, not the technology. Assess your governance foundation, deploy the cloud data plumbing (warehouse, ingestion, transformation, BI, catalog), build the context layer (semantic → ontology → ECL) sequenced to your AI maturity, and build an automated governance feedback loop from day one so context doesn't drift.
Can a legacy data stack be migrated to a modern data stack for AI? Yes, though the path depends on data volume and complexity. Most organizations migrate the cloud foundation first, establish governance and semantic consistency, then layer in ontology and context capabilities as their AI use cases mature.

- Key Takeaways
- What is a modern data stack?
- What is a modern data stack for AI?
- How a modern data stack for AI differs from a traditional analytics stack
- What are the components of a modern data stack for AI?
- How has the modern data stack evolved into an AI stack?
- How does a modern data stack power AI and machine learning?
- How the modern data stack powers data products for AI
- Modern data stack vs. legacy data stack
- What are the benefits of a modern data stack for AI?
- How do you build a modern data stack for AI?
- How to sequence the investment by AI maturity
- Governance: the foundation that keeps an AI data stack trustworthy
- What challenges come with adopting a modern data stack for AI?
- Who needs a modern data stack for AI?
- Getting started with a modern data stack for AI
- FAQs
Contents
FAQs
What Is the Modern Data Stack?
The modern data stack is a combination of various software tools that are used to collect, process, and store data on a well-integrated cloud-based data platform. It is known to have benefits in handling data due to its robustness, speed, and scalability.
What Separates a Modern Data Stack From a Legacy Data Stack?
A modern data stack is typically more scalable, flexible, and efficient than a legacy data stack. A modern data stack relies on cloud computing, whereas a legacy data stack stores data on servers instead of on the cloud. Modern data stacks provide access to more data professionals than a legacy data stack.
Who Can Adopt the Modern Data Stack?
The modern data stack is well-suited for companies with large amounts of data. In the past, this was restricted to enterprise-sized organizations, but increasingly, even smaller businesses face large data landscapes and will benefit from a modern data stack.
Can legacy data stacks be seamlessly migrated to modern data stacks?
Legacy data stacks can generally be migrated to modern data stacks, but the process may vary depending on factors like data volume and complexity. Robust planning and execution are key to ensuring a smooth transition without disruptions to operations.
How does the modern data stack accommodate real-time data analytics?
The modern data stack accommodates real-time data analytics by leveraging tools that enable continuous data ingestion, processing, and analysis. These tools allow organizations to derive insights from data as soon as it becomes available, facilitating faster decision-making.
Tagged with
Loading...